Downloaded 15 times





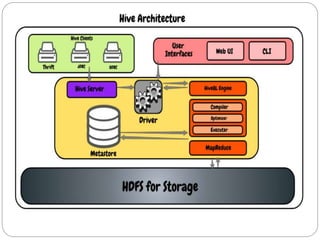

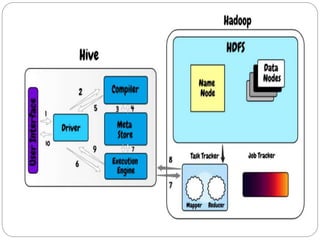

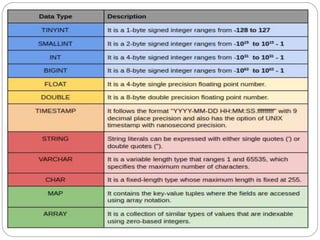

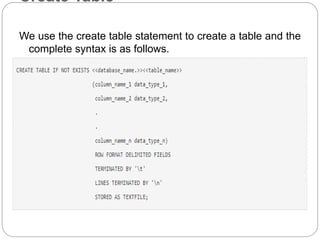
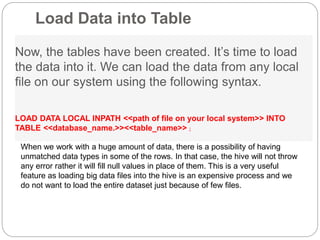




Apache Hive is a data warehouse system that allows users to write SQL-like queries to analyze large datasets stored in Hadoop. It converts these queries into MapReduce jobs that process the data in parallel across the Hadoop cluster. Hive provides metadata storage, SQL support, and data summarization to make analyzing large datasets easier for analysts familiar with SQL.























































































