Download to read offline








![ Creating a View
You can create a view at the time of executing a SELECT
statement. The syntax is as follows:
CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], ...)
] [COMMENT table_comment] AS SELECT ...
hive> CREATE VIEW emp_30000 AS SELECT * FROM employee WHERE salary>30000;
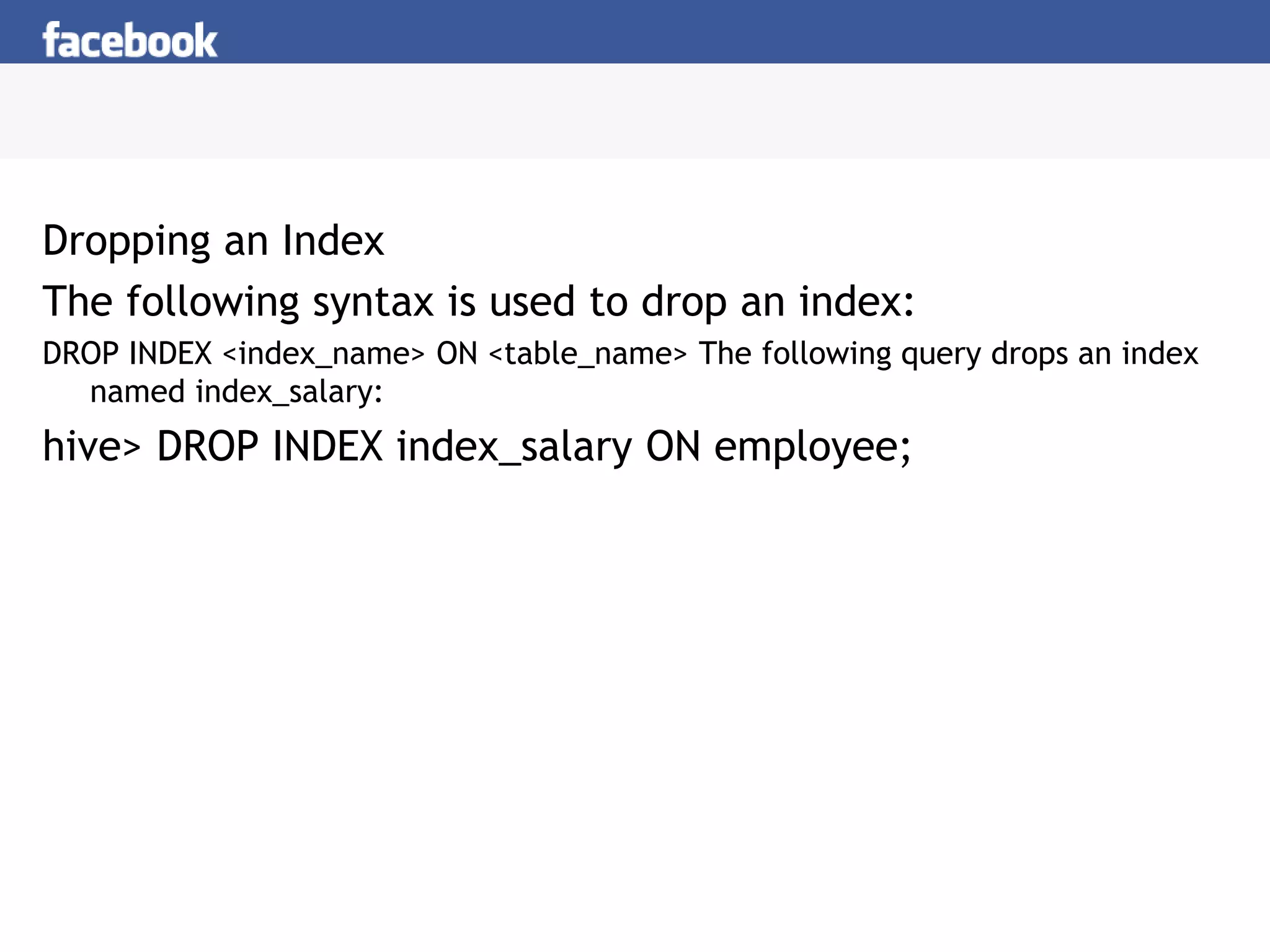
Dropping a View
Use the following syntax to drop a view:
DROP VIEW view_name The following query drops a view named as emp_30000:
hive> DROP VIEW emp_30000;](https://image.slidesharecdn.com/unit-5-lecture4-210825042058/75/Unit-5-lecture4-17-2048.jpg)
![Creating an Index
An Index is nothing but a pointer on a particular column of a
table. Creating an index means creating a pointer on a
particular column of a table. Its syntax is as follows:
CREATE INDEX index_name ON TABLE base_table_name (col_name, ...) AS
'index.handler.class.name' [WITH DEFERRED REBUILD] [IDXPROPERTIES
(property_name=property_value, ...)] [IN TABLE index_table_name] [PARTITIONED BY
(col_name, ...)] [ [ ROW FORMAT ...] STORED AS ... | STORED BY ... ] [LOCATION
hdfs_path] [TBLPROPERTIES (...)]
hive> CREATE INDEX inedx_salary ON TABLE employee(salary) AS
'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';](https://image.slidesharecdn.com/unit-5-lecture4-210825042058/75/Unit-5-lecture4-18-2048.jpg)
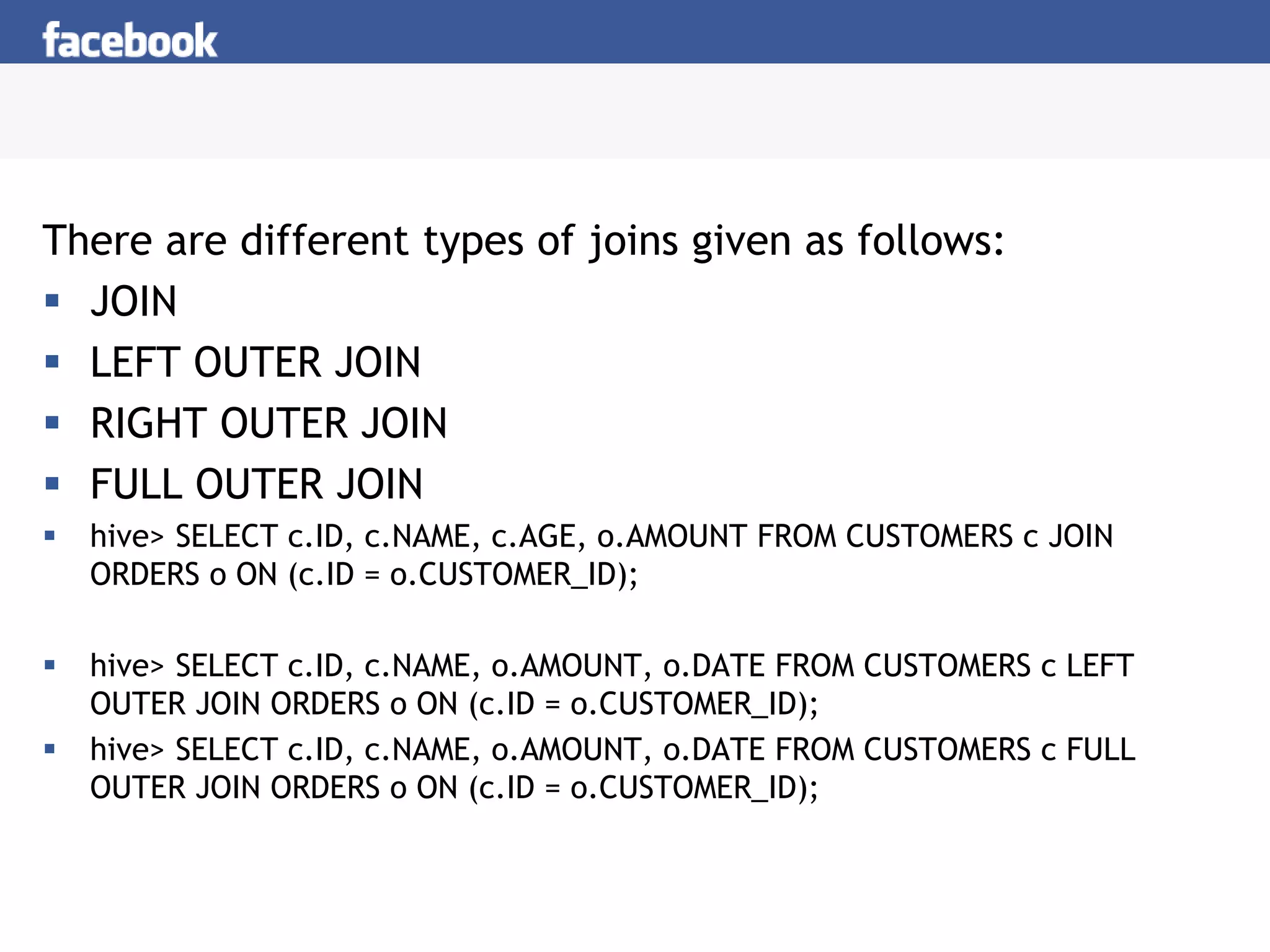

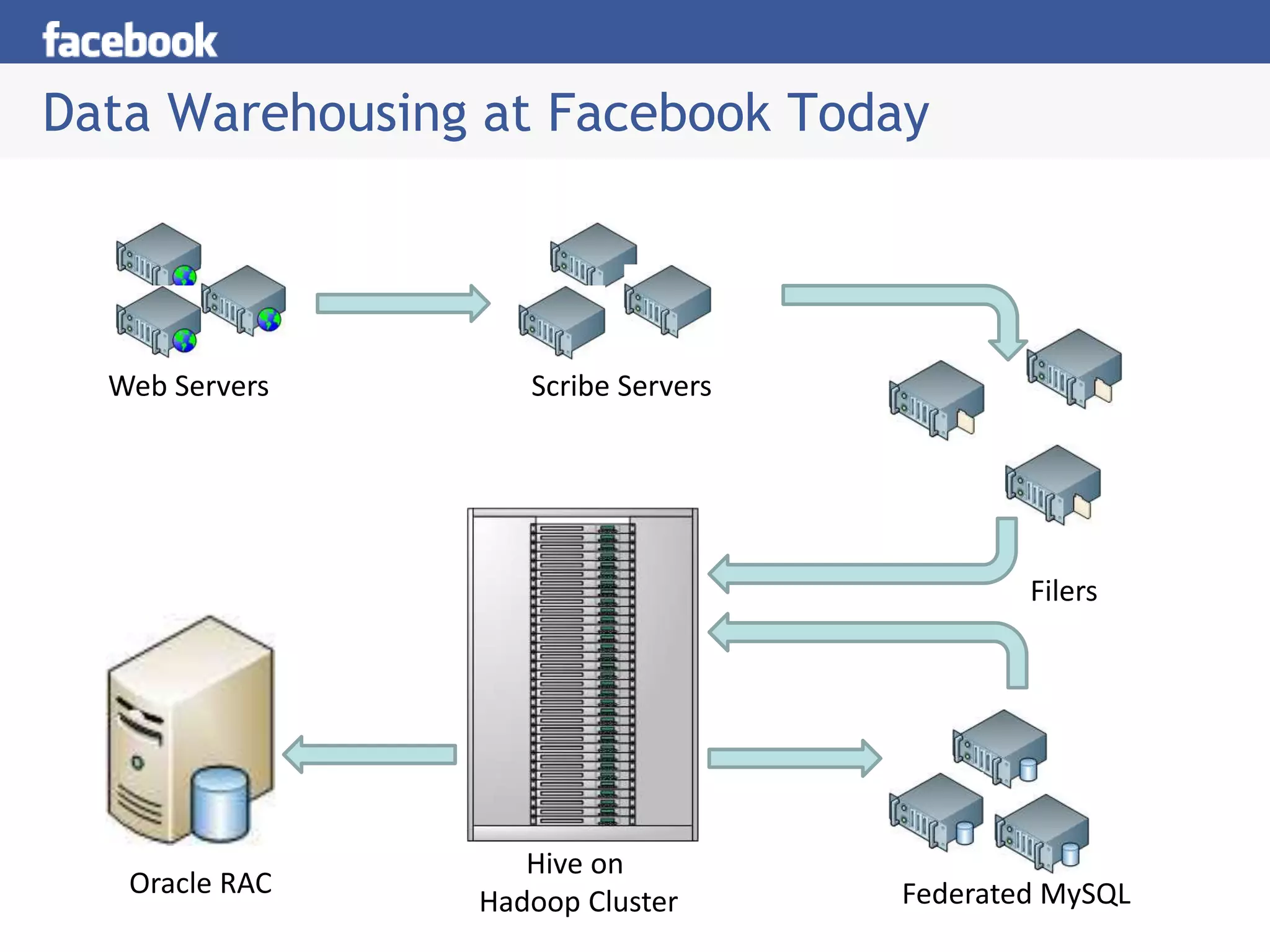
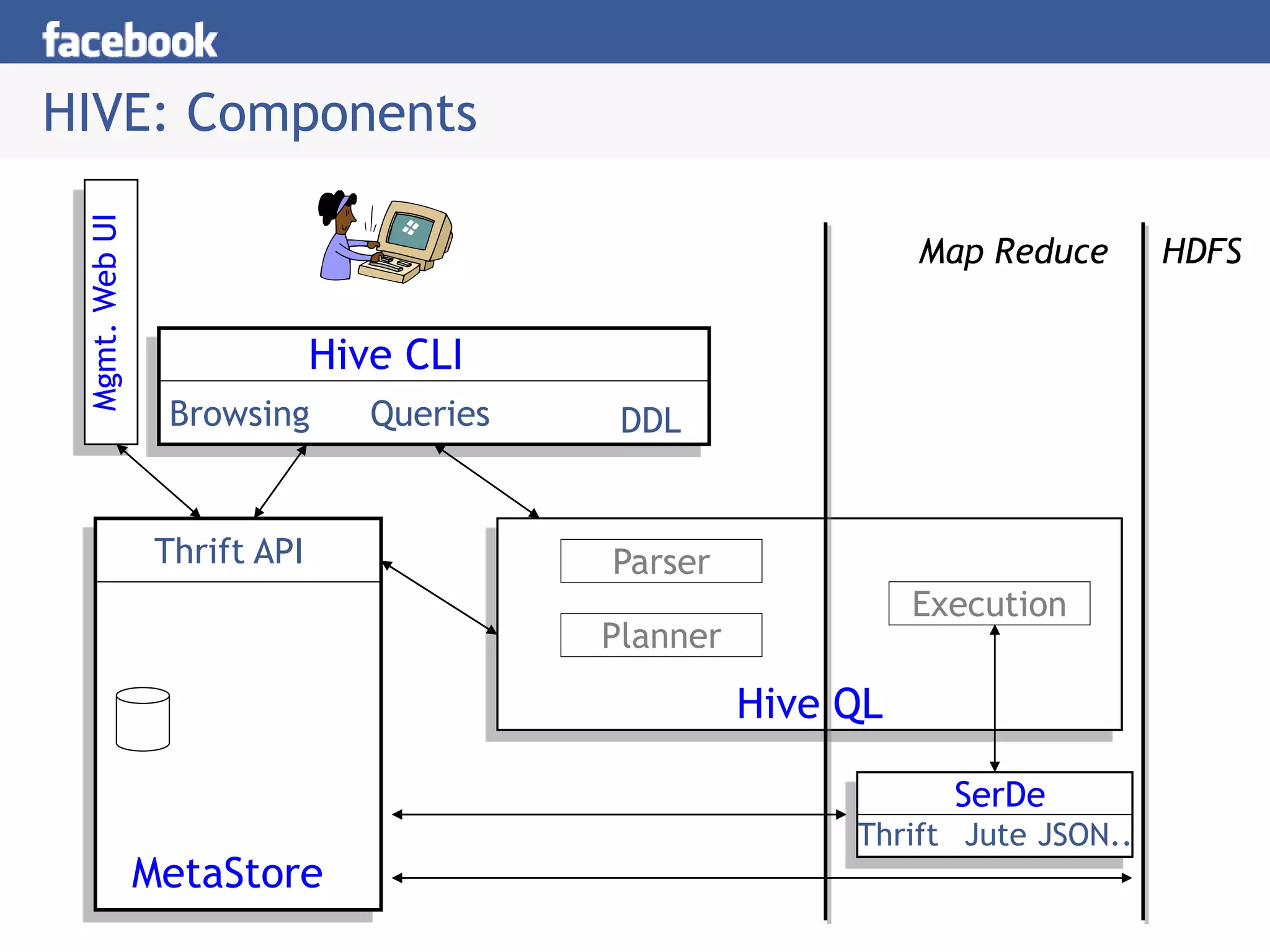
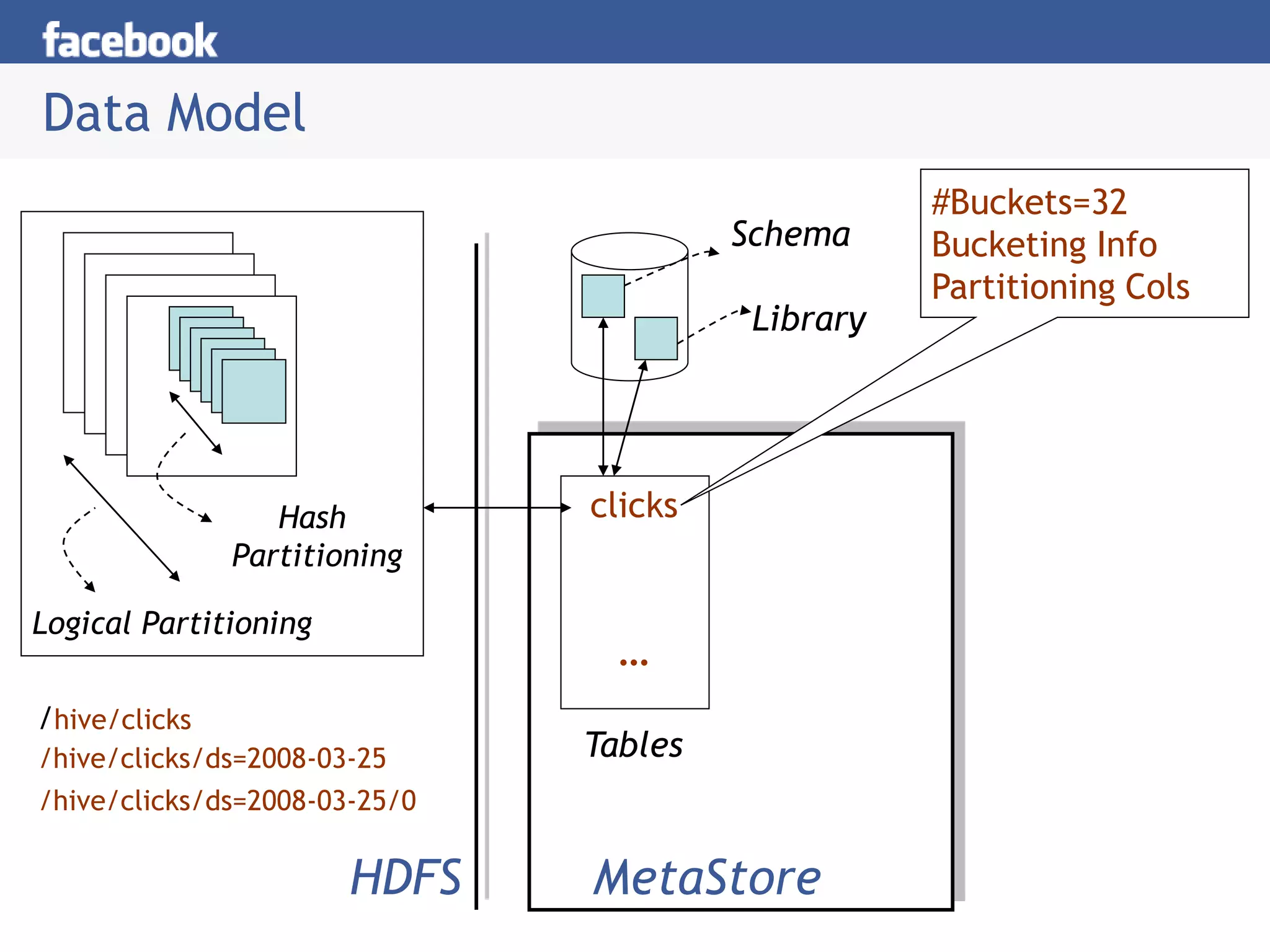
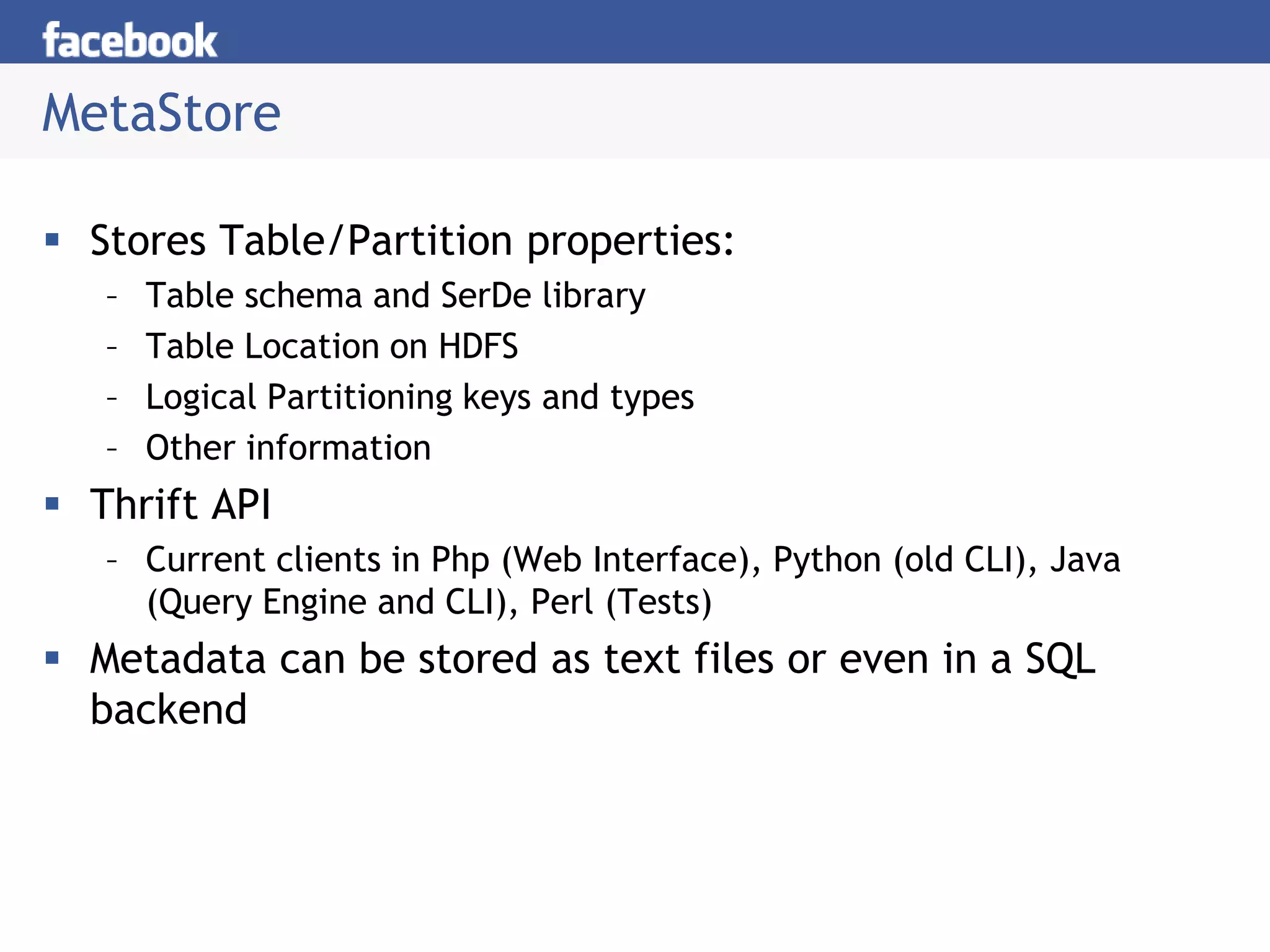
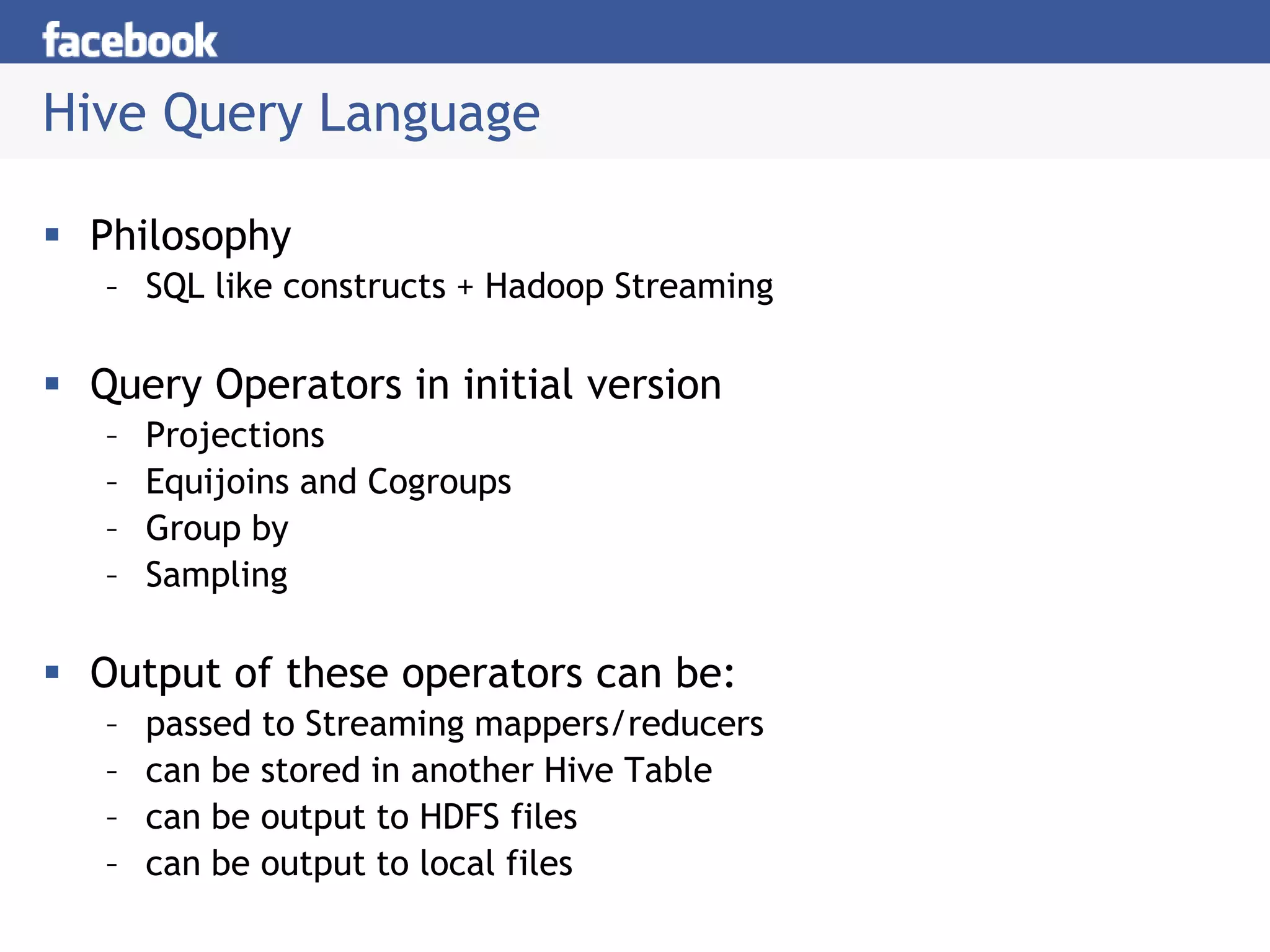
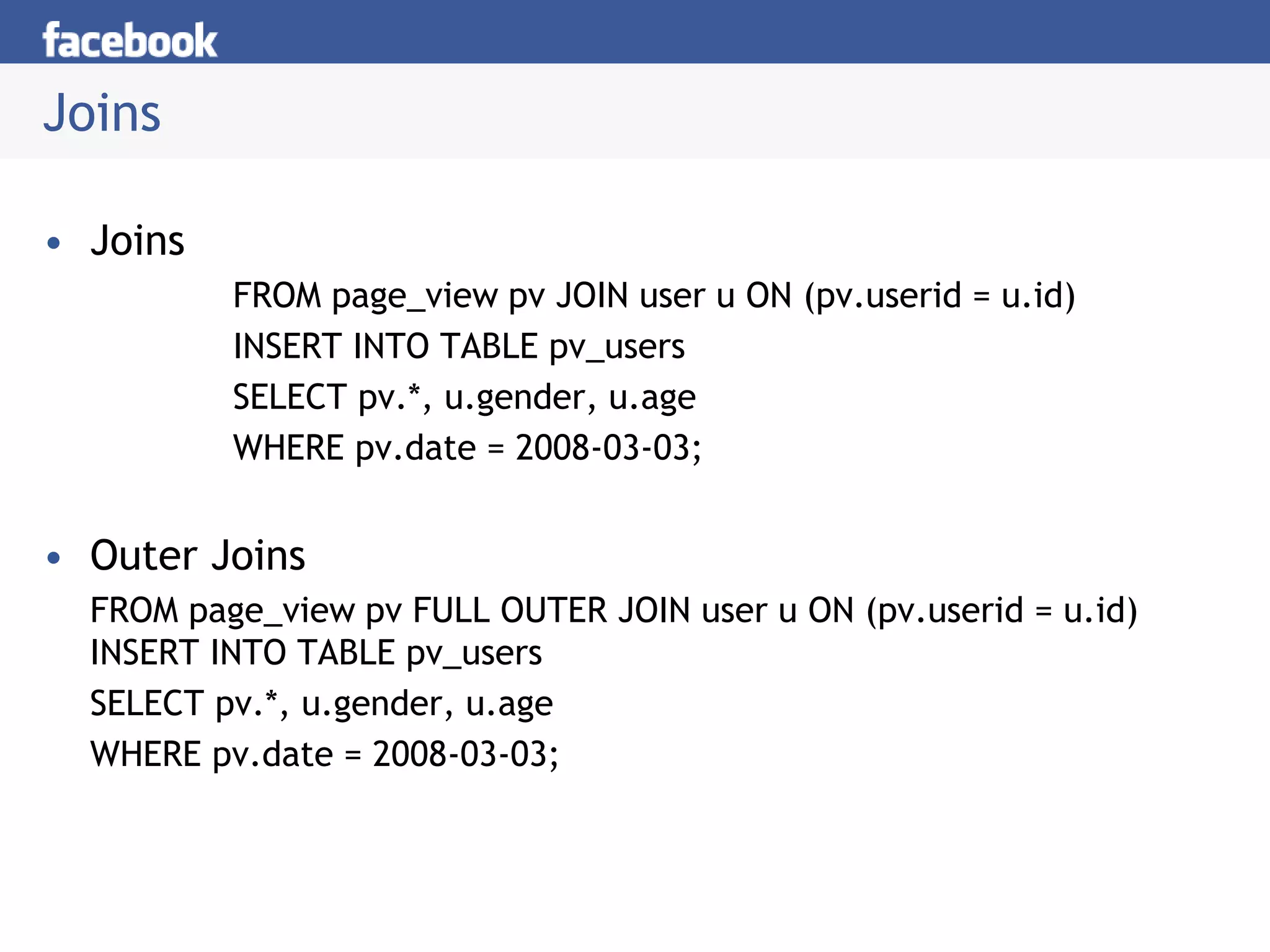
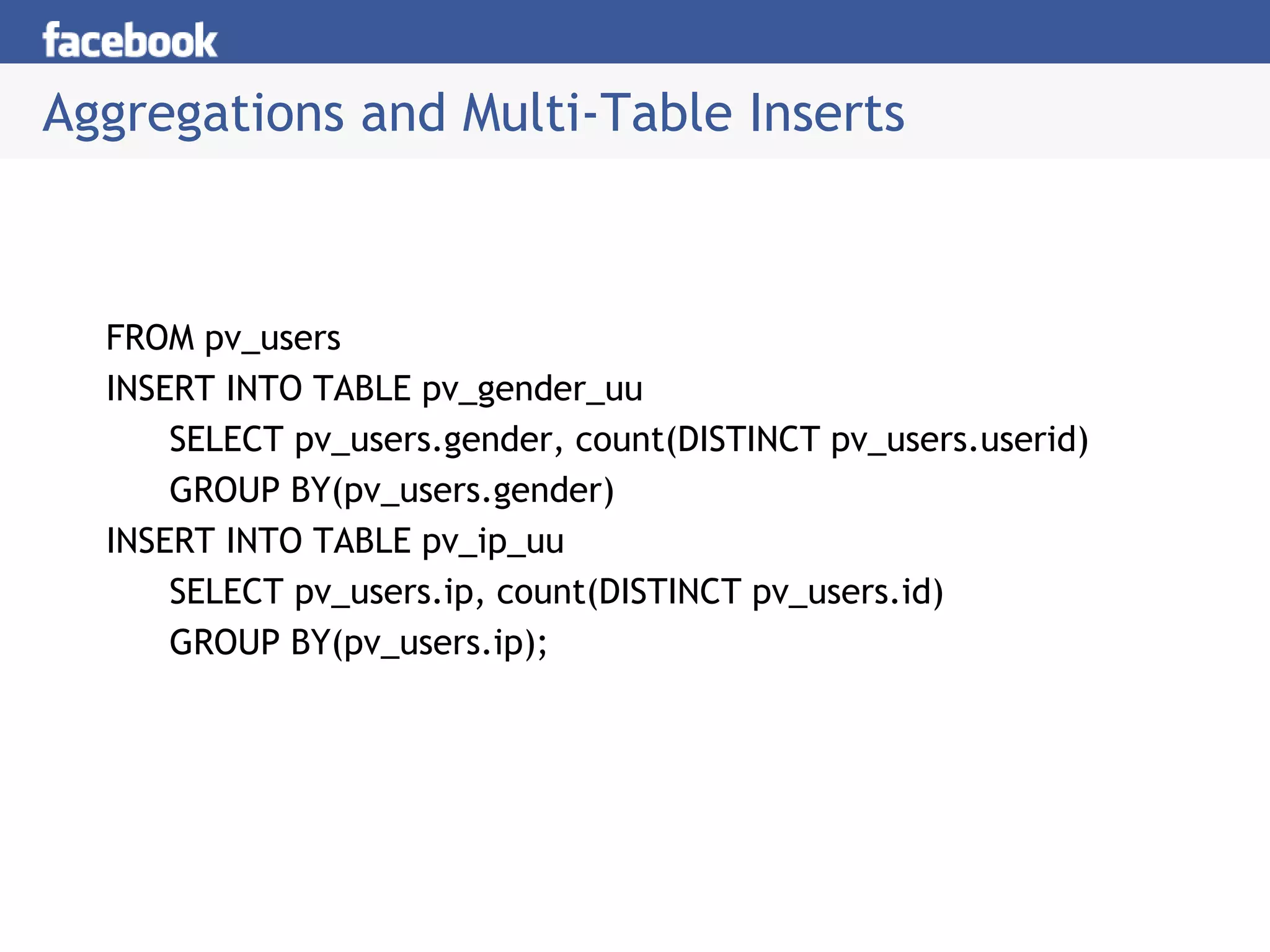
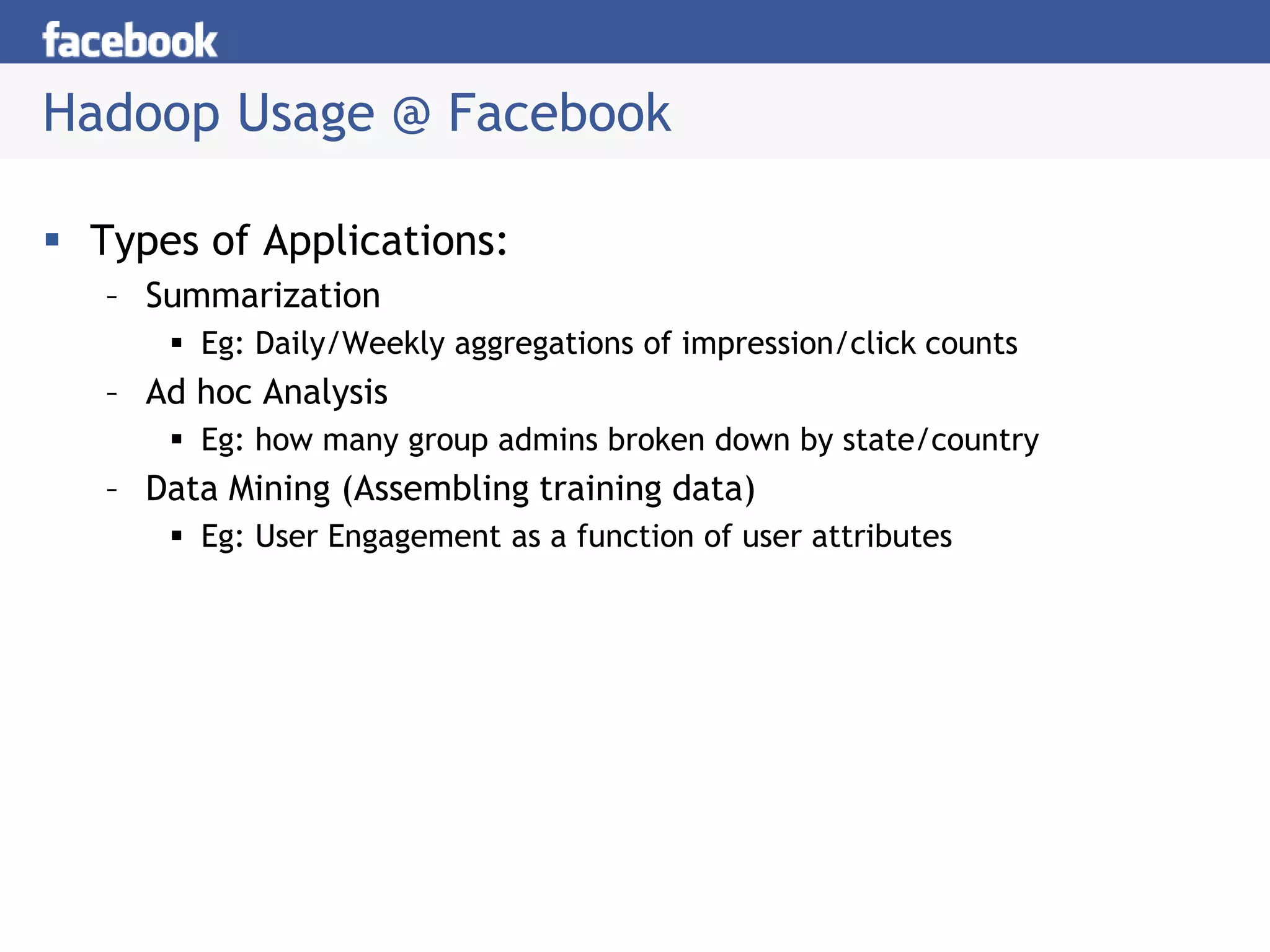
Hive is a data warehousing system built on Hadoop that allows users to query data using SQL. It consists of components like the Hive query language, metastore, and SerDes. Hive allows users to create and manage databases and tables, load data, and run queries using a SQL-like language that outputs results or transforms data using MapReduce jobs. It is used at Facebook to analyze large amounts of structured data stored in HDFS.




































































![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
