Downloaded 112 times
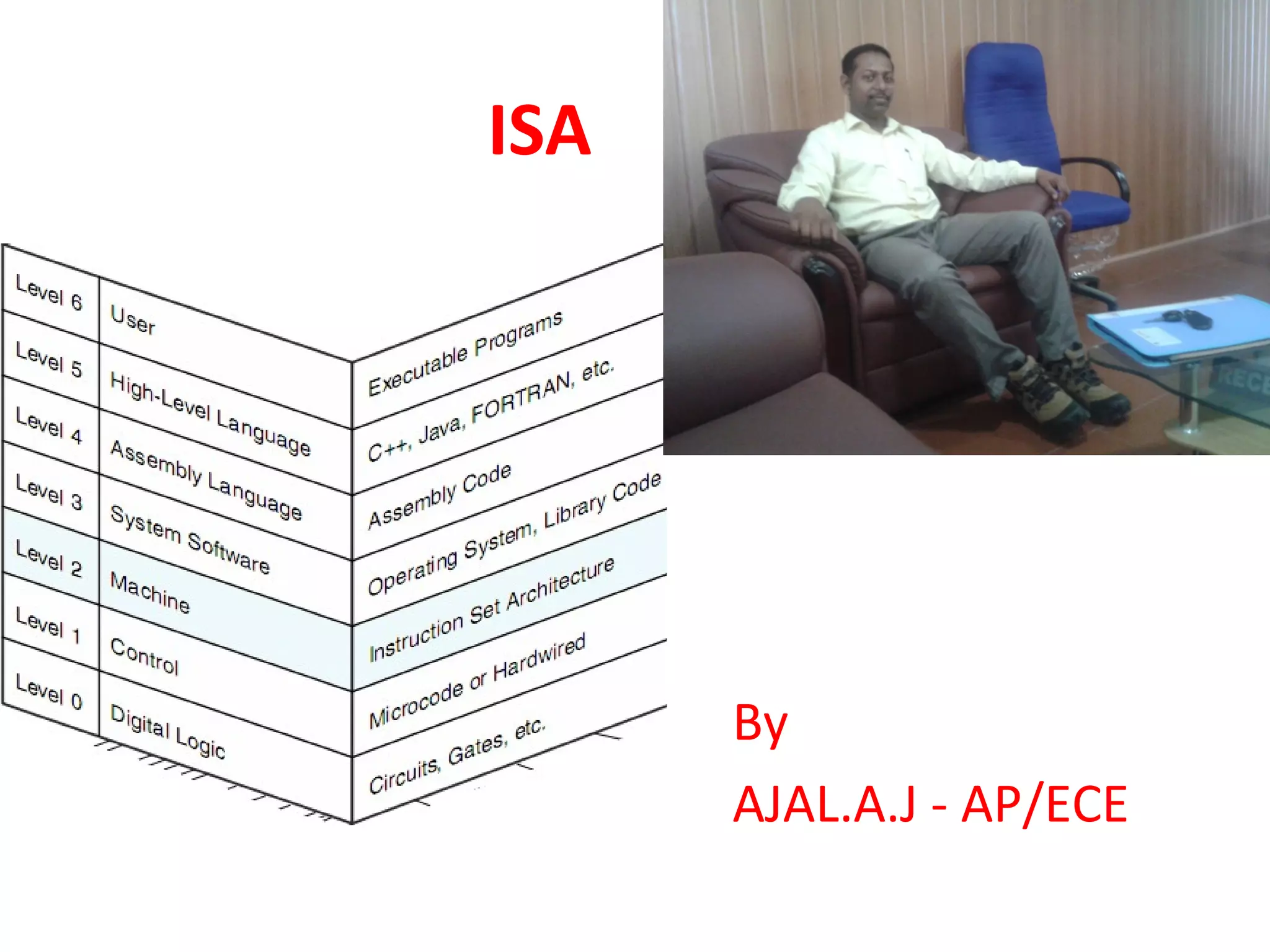

![Instruction Set Architecture
Computer Architecture =
Instruction Set Architecture
+ Machine Organization
• “... the attributes of a [computing] system as seen by
the programmer, i.e. the conceptual structure and
functional behavior …”](https://image.slidesharecdn.com/isa1-150210012211-conversion-gate01/75/isa-architecture-3-2048.jpg)




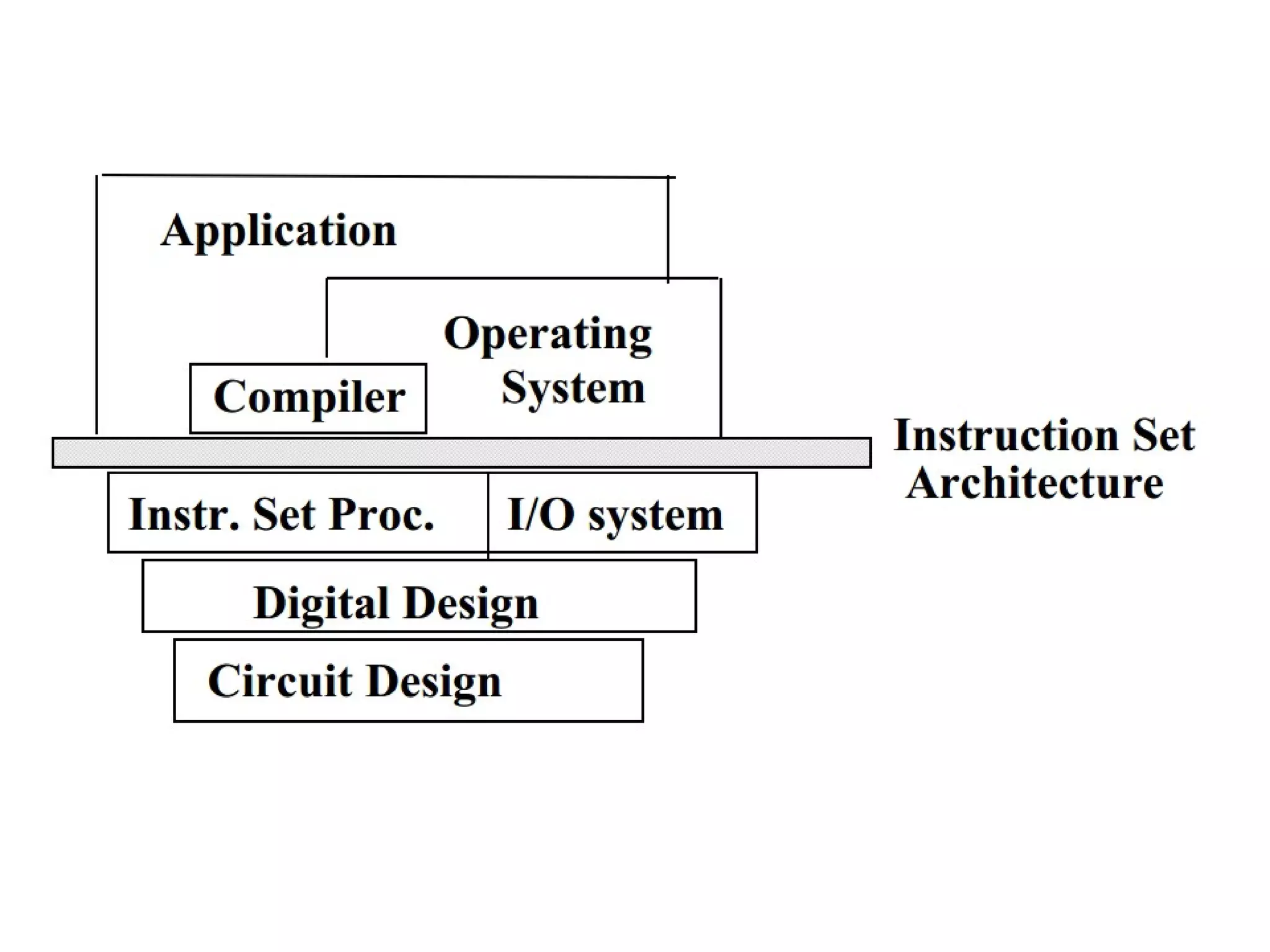





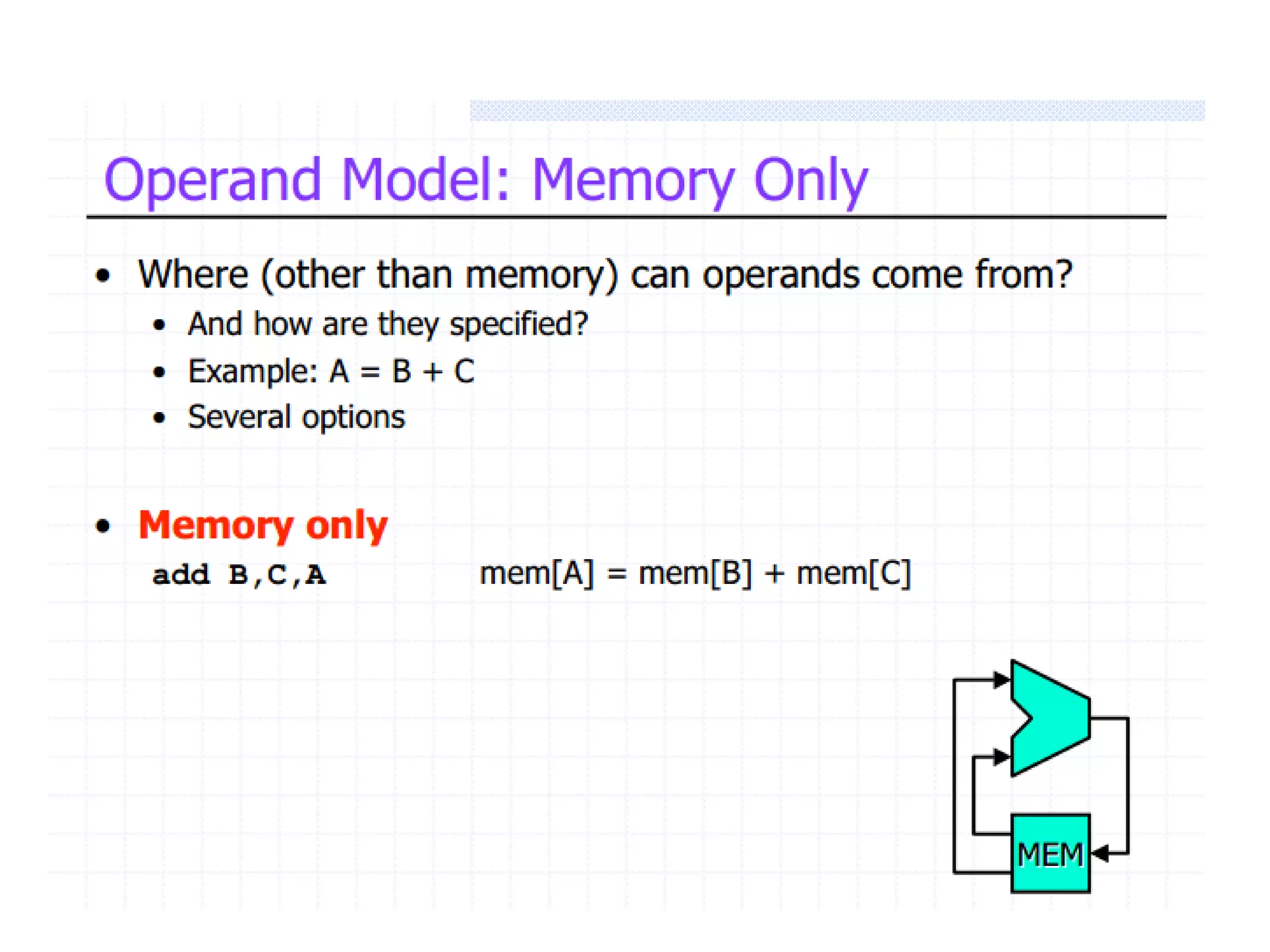
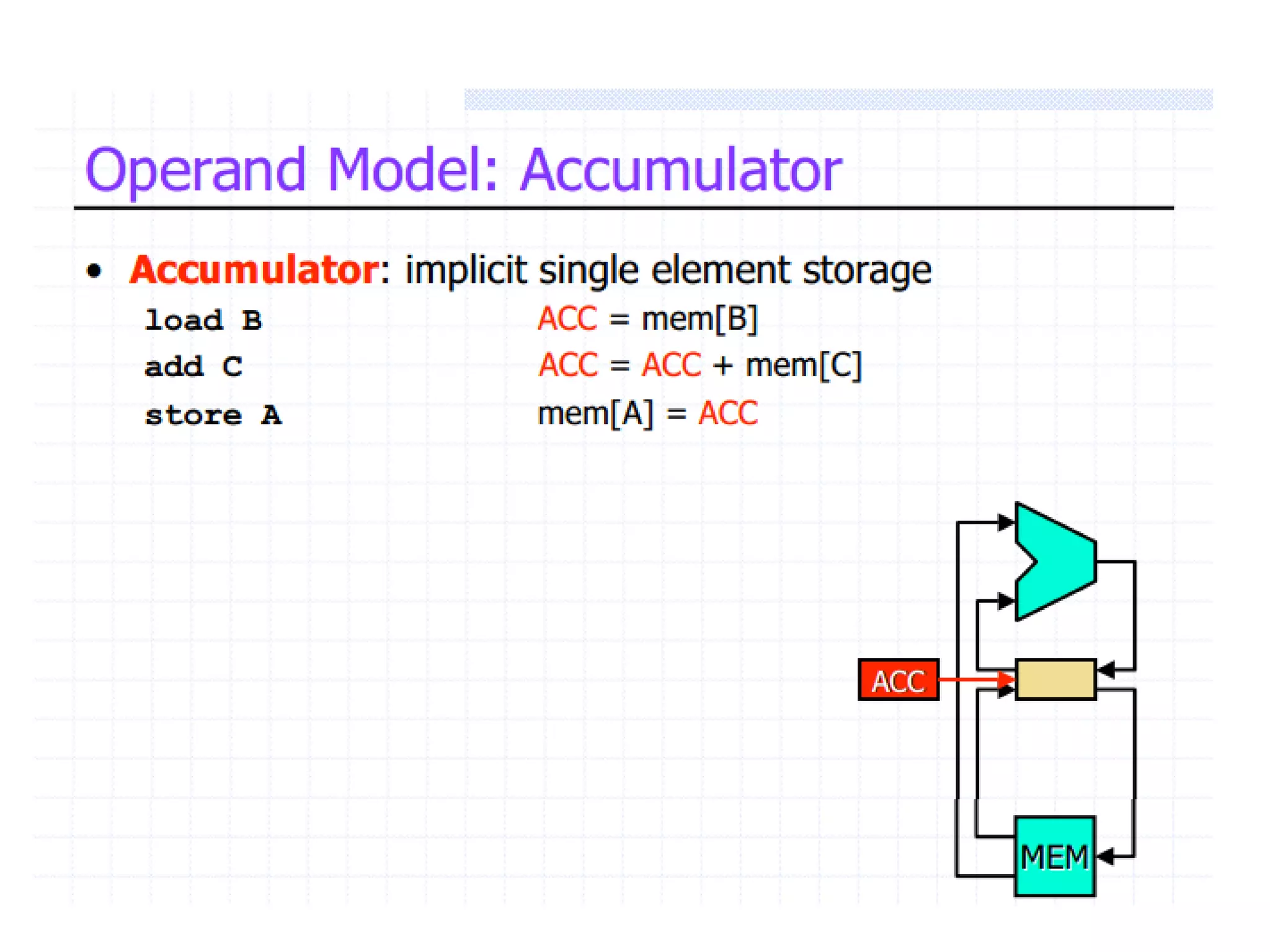
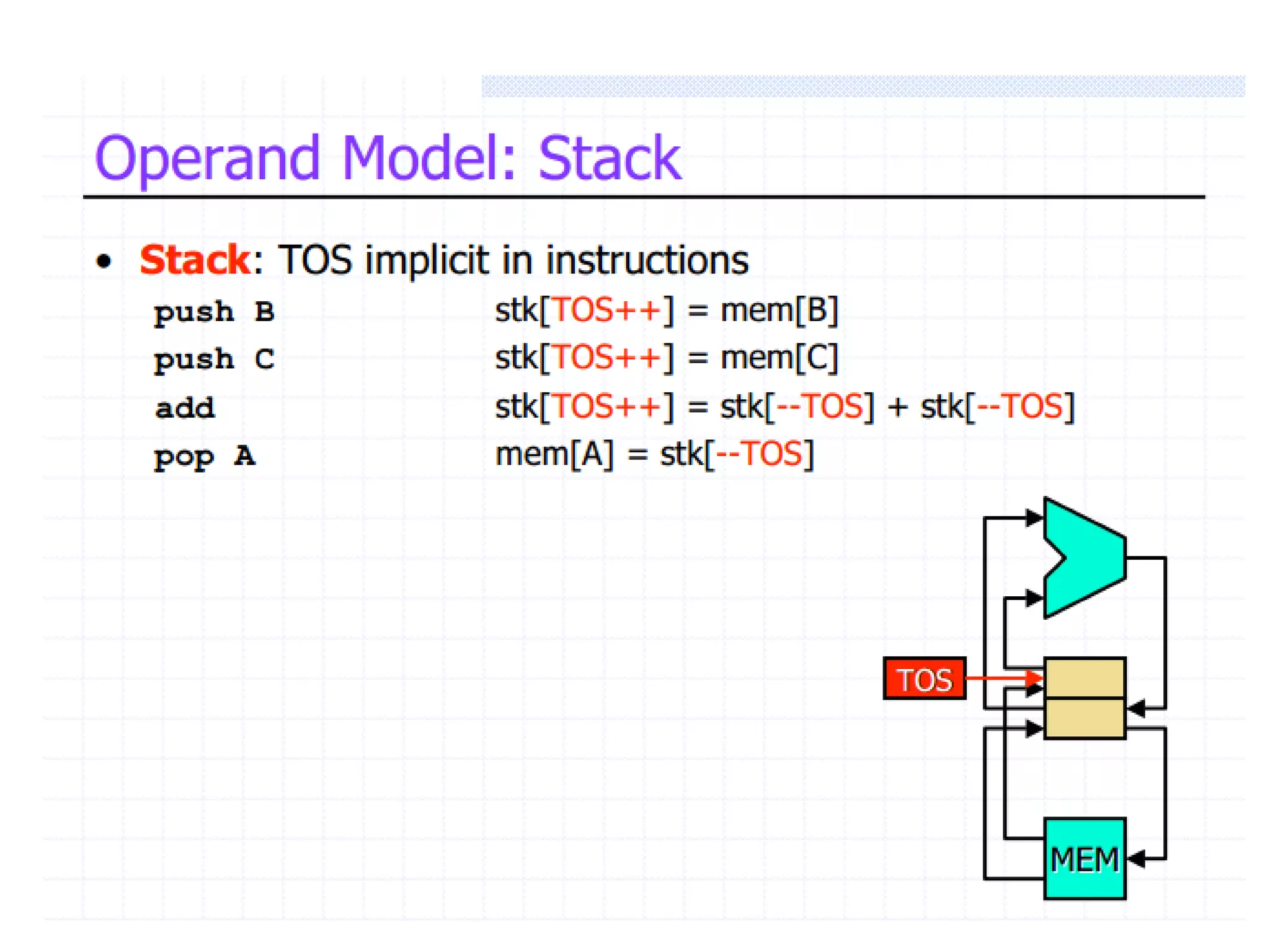
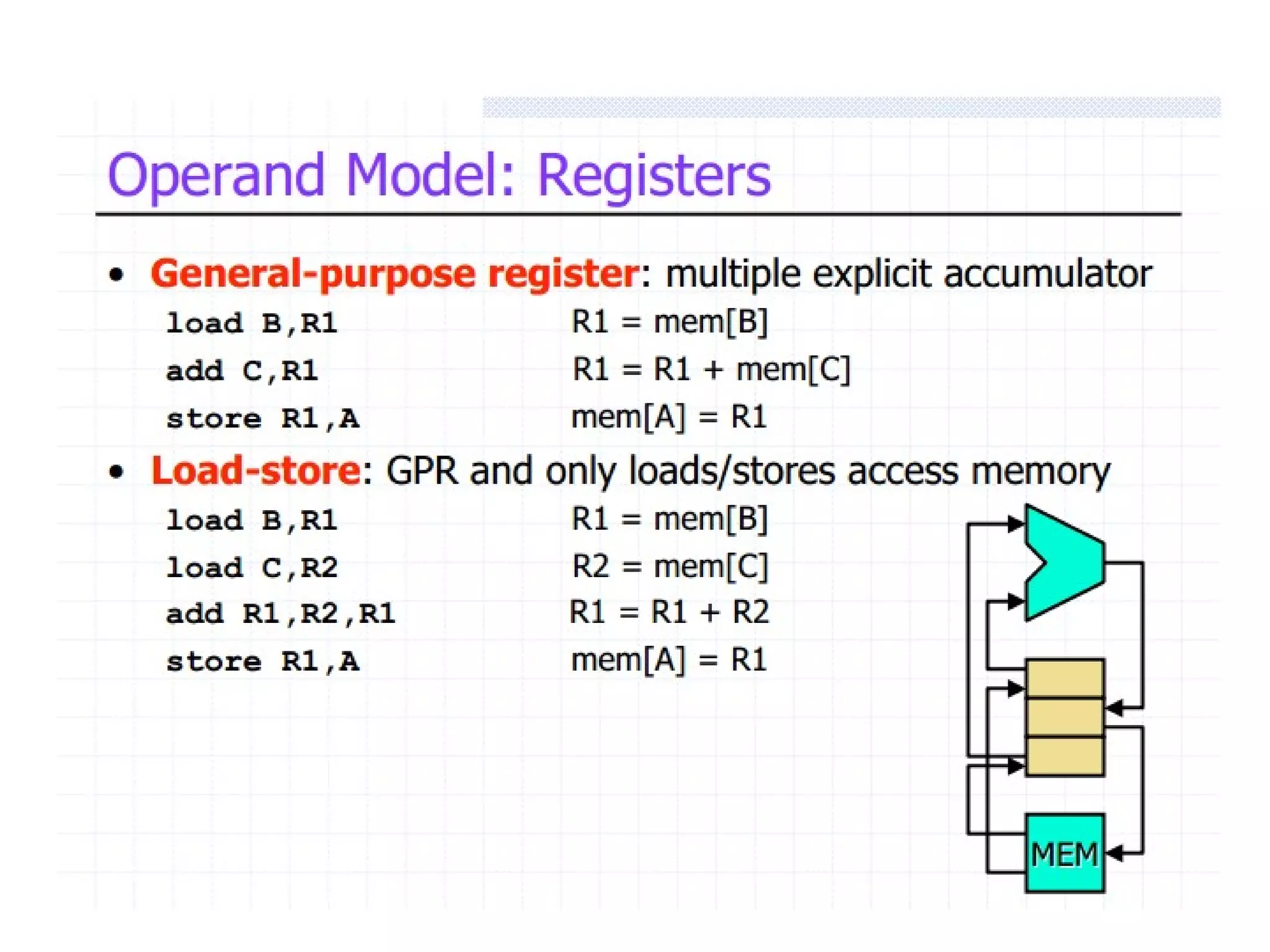








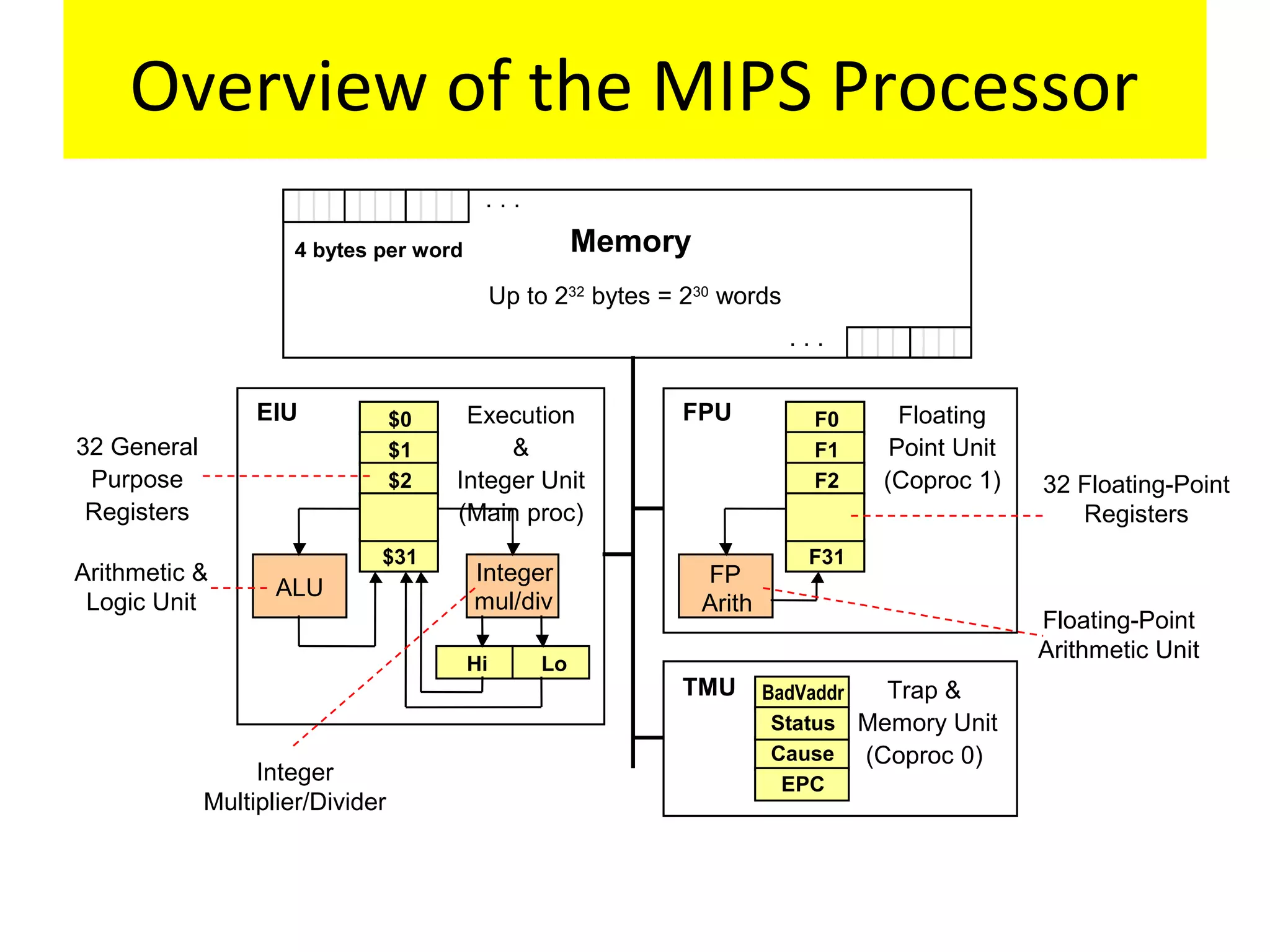
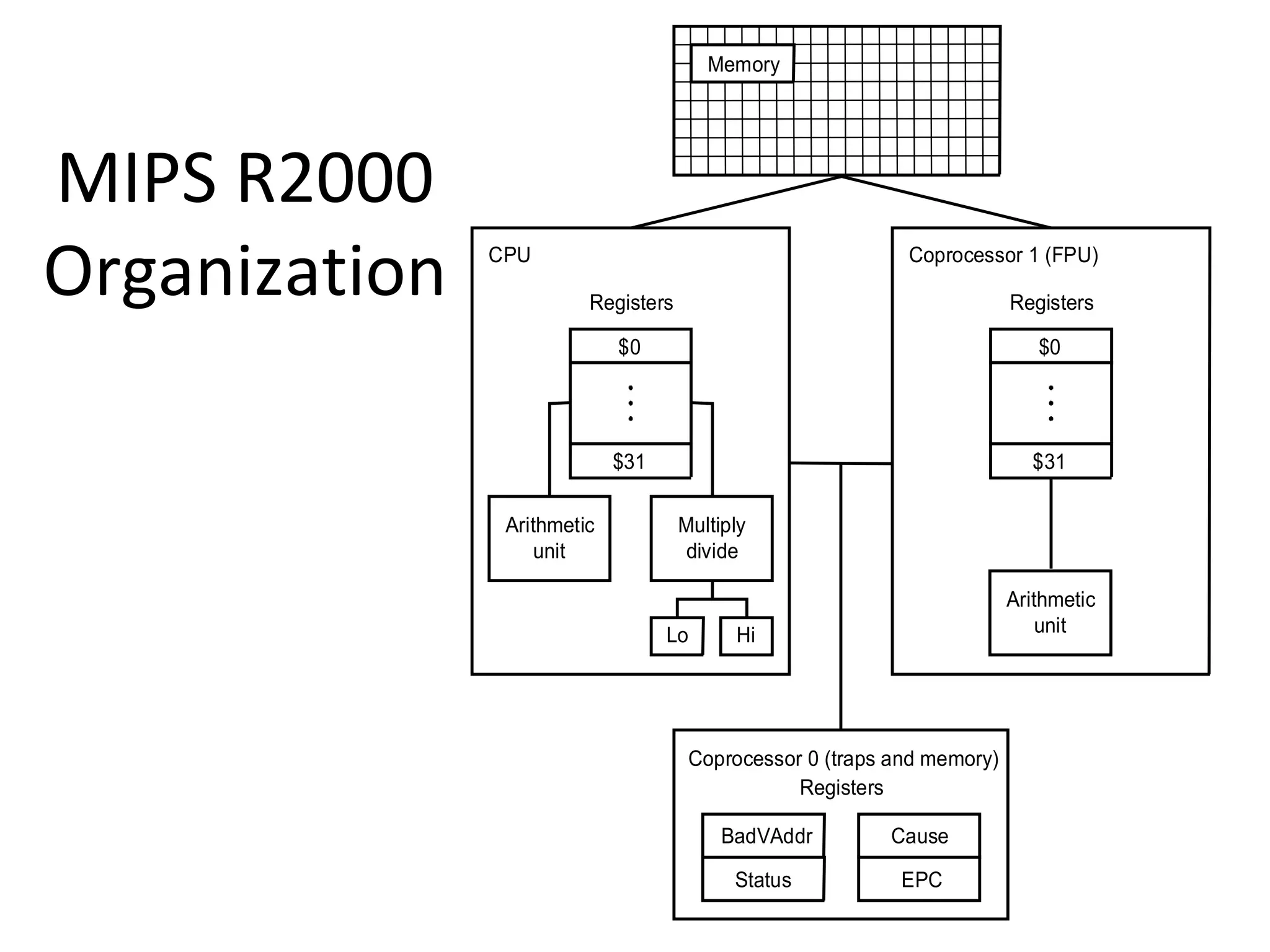


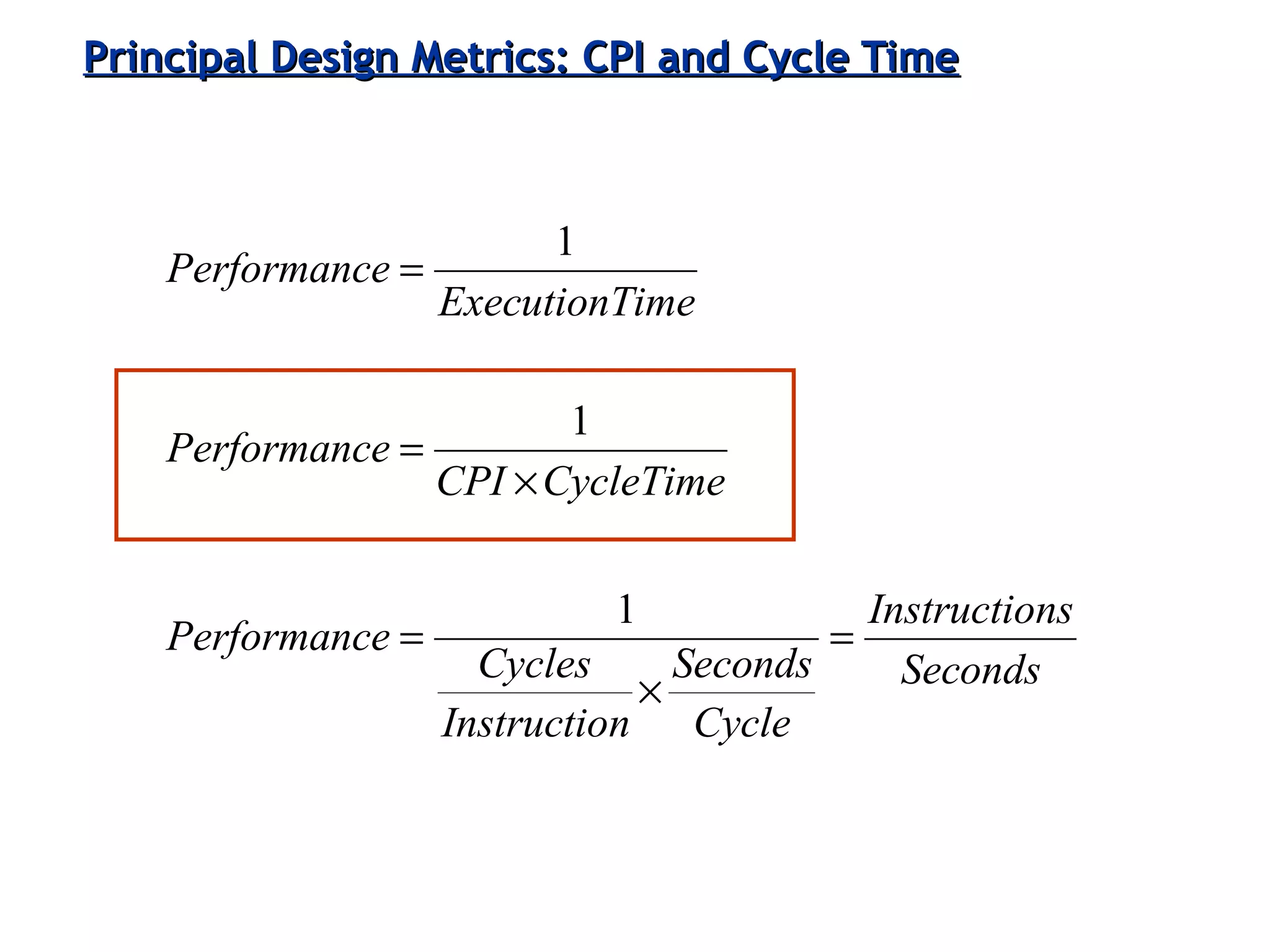
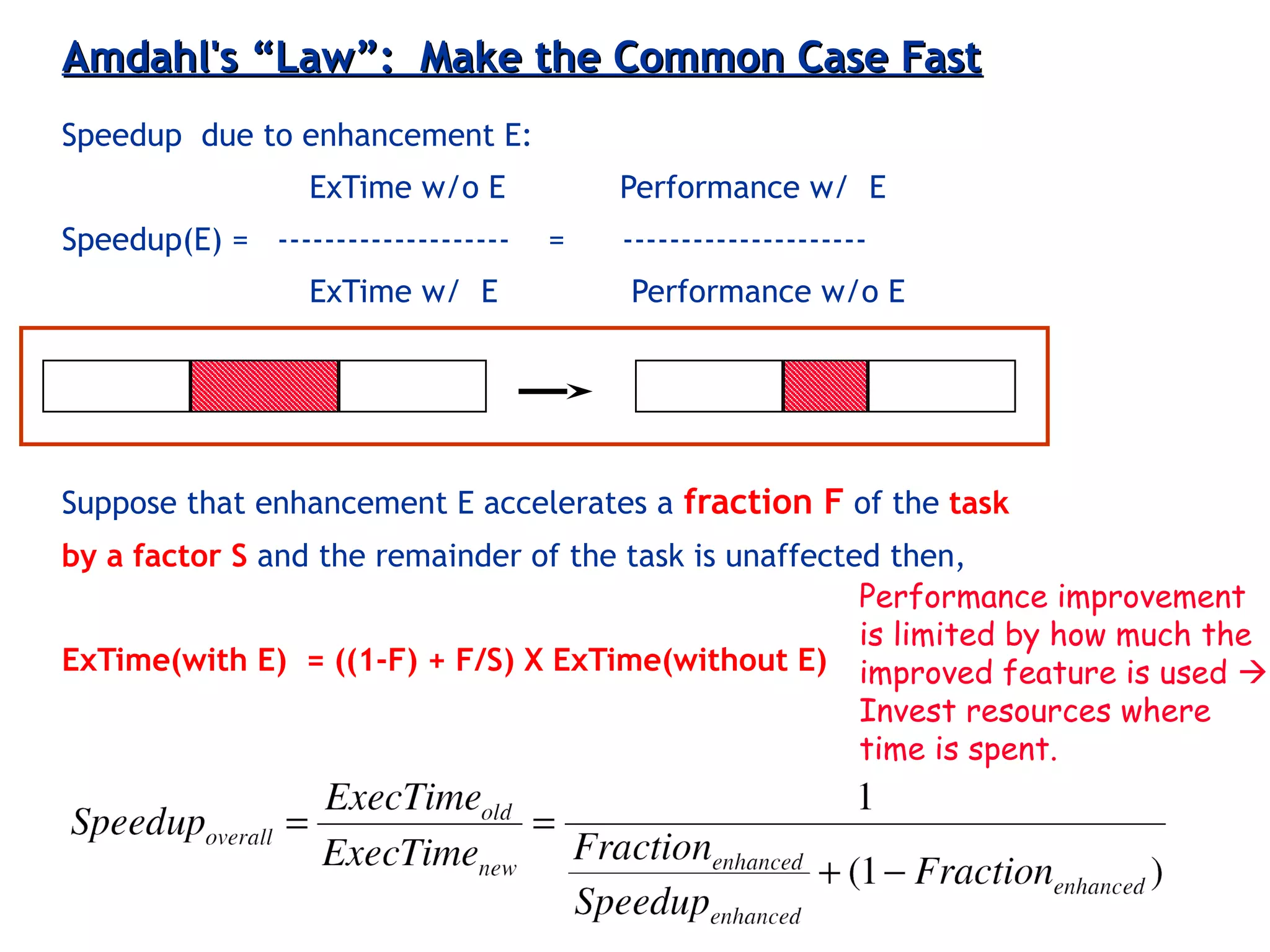

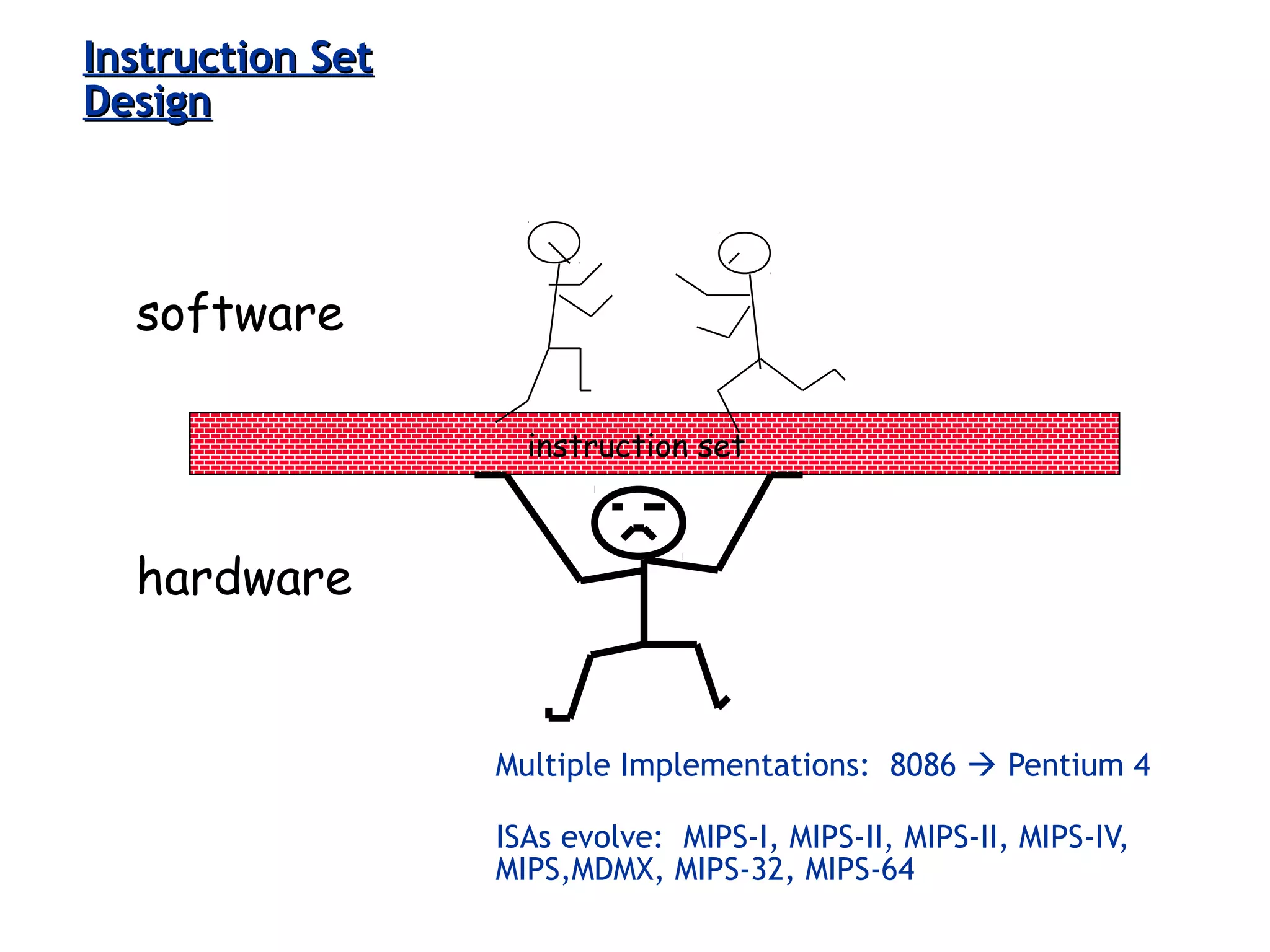

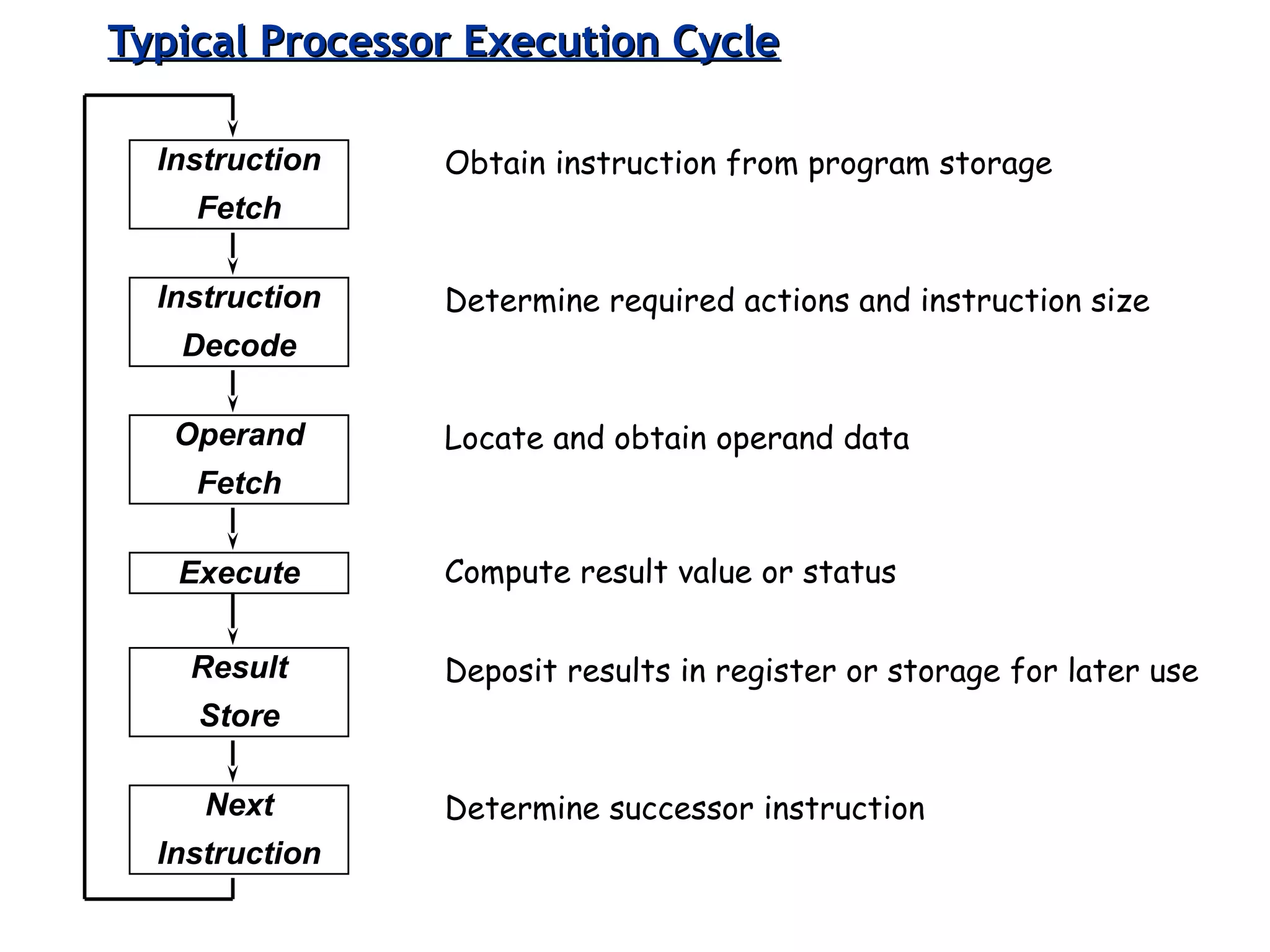
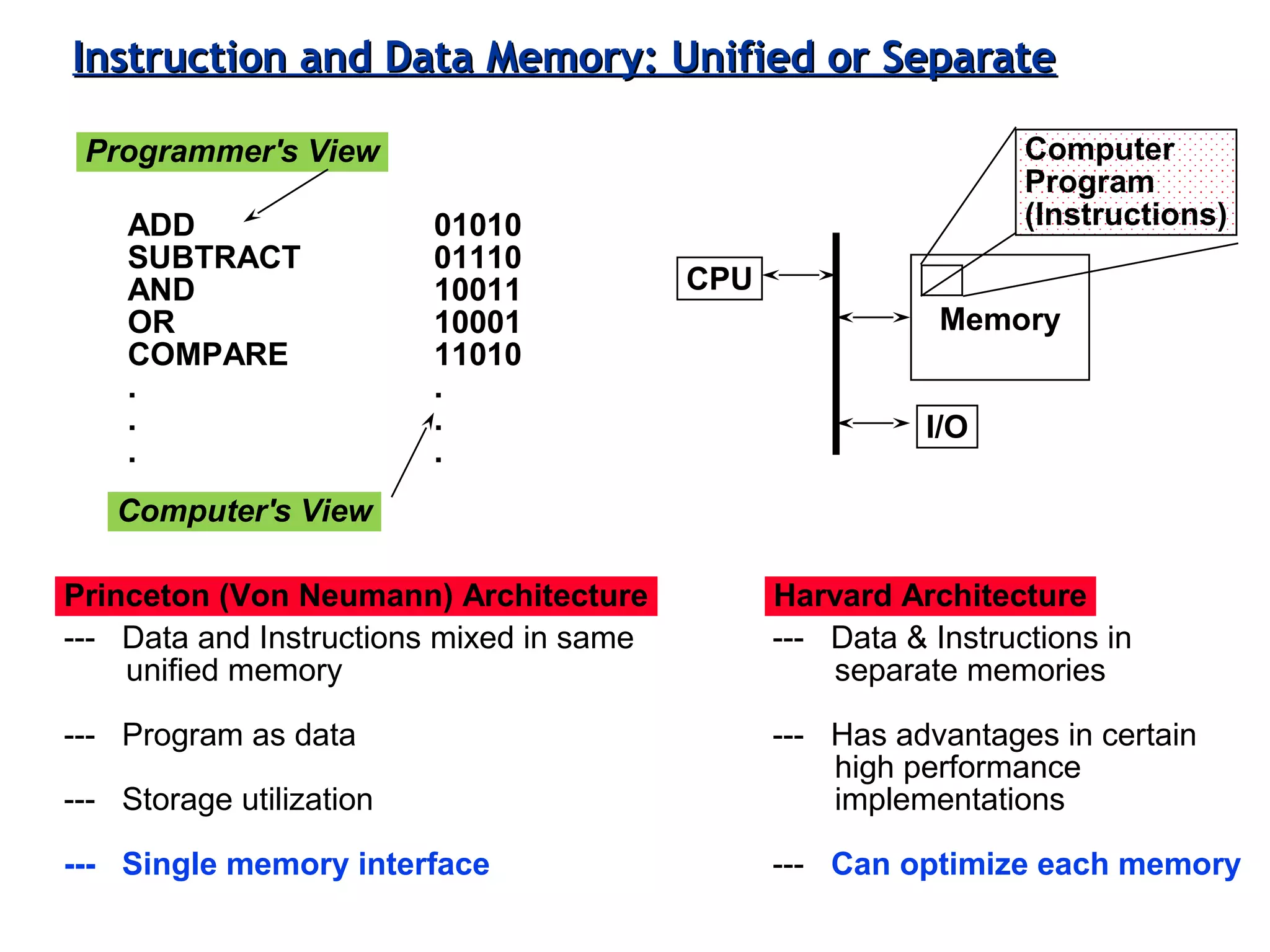
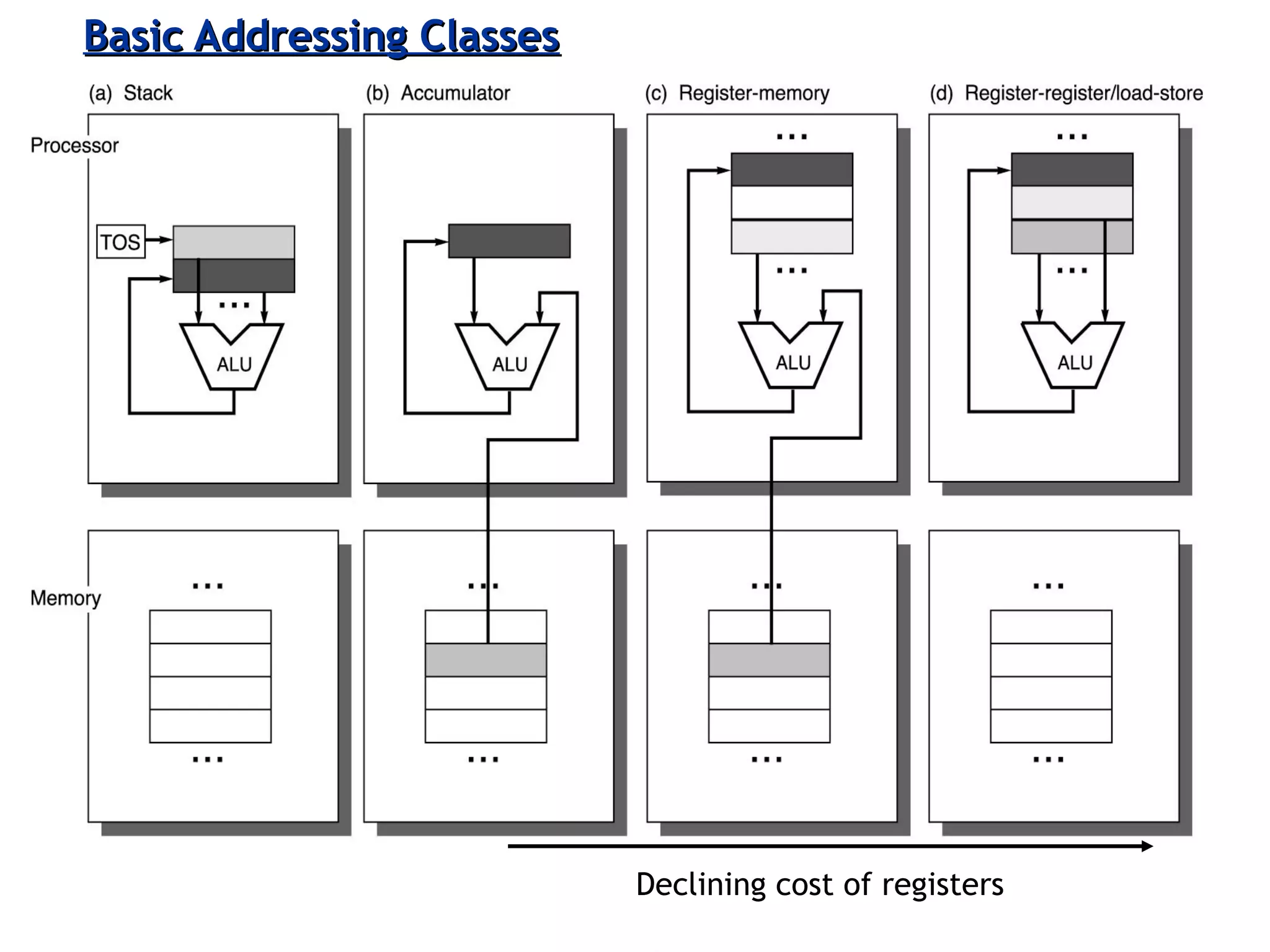

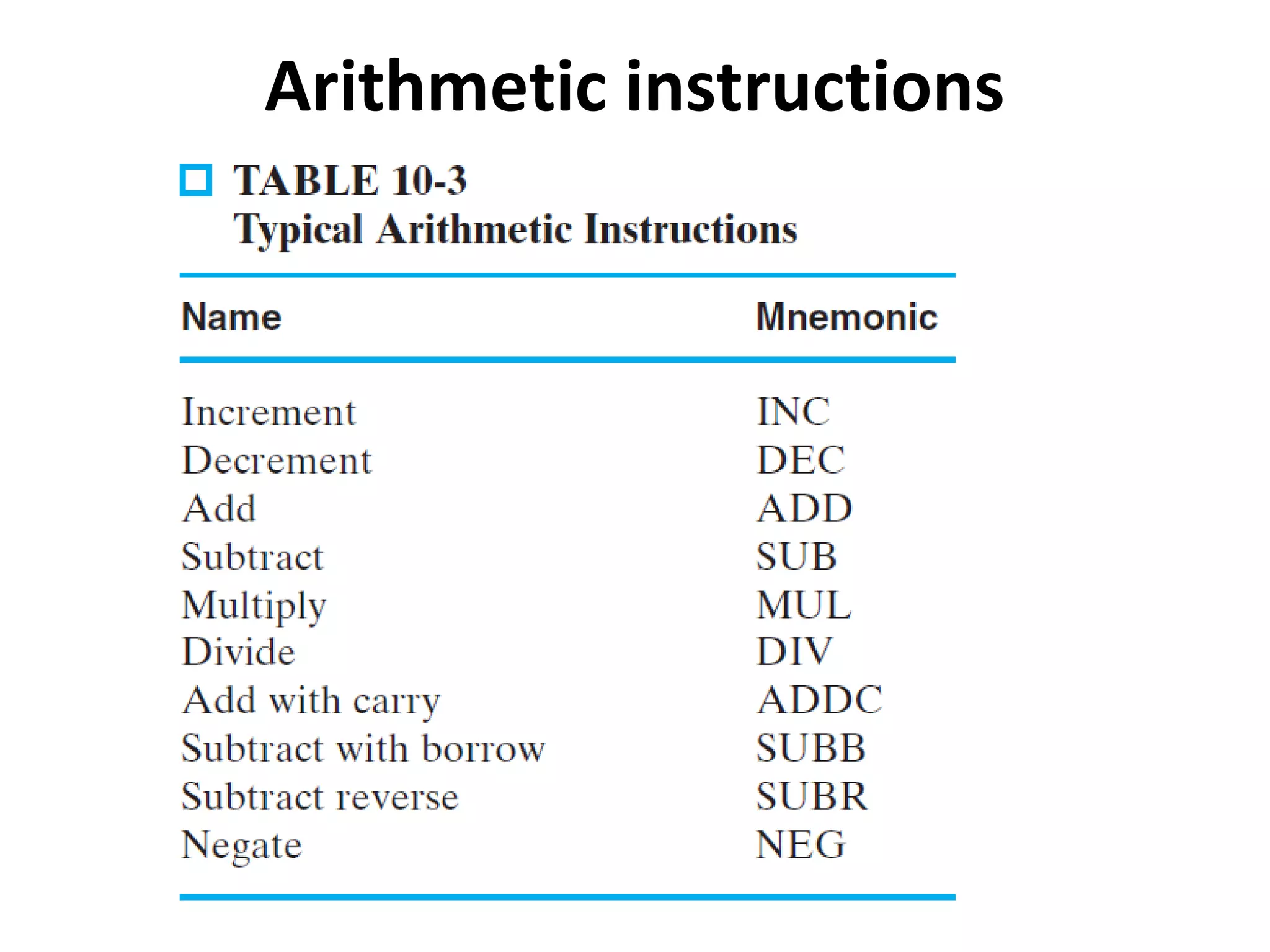
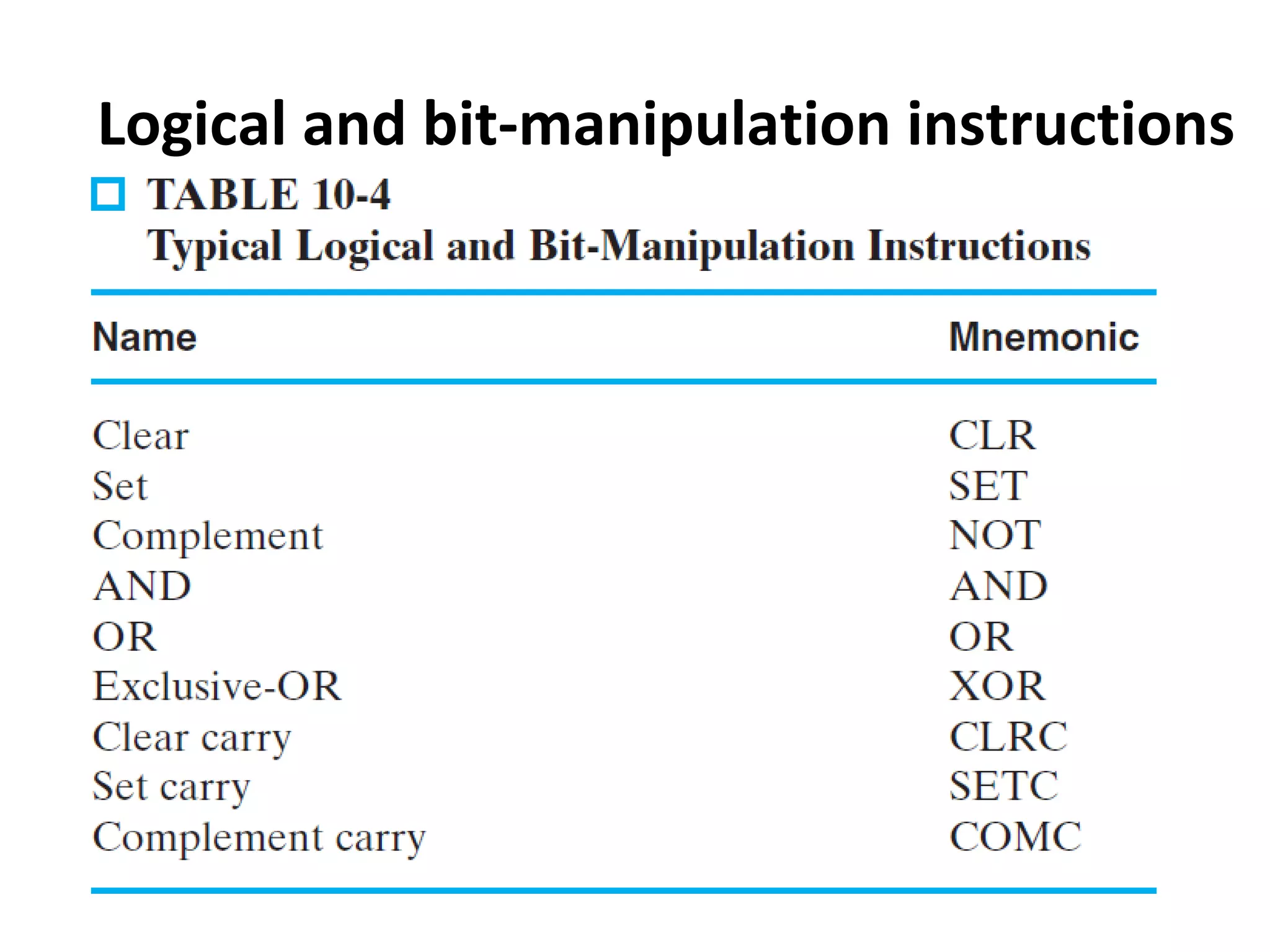
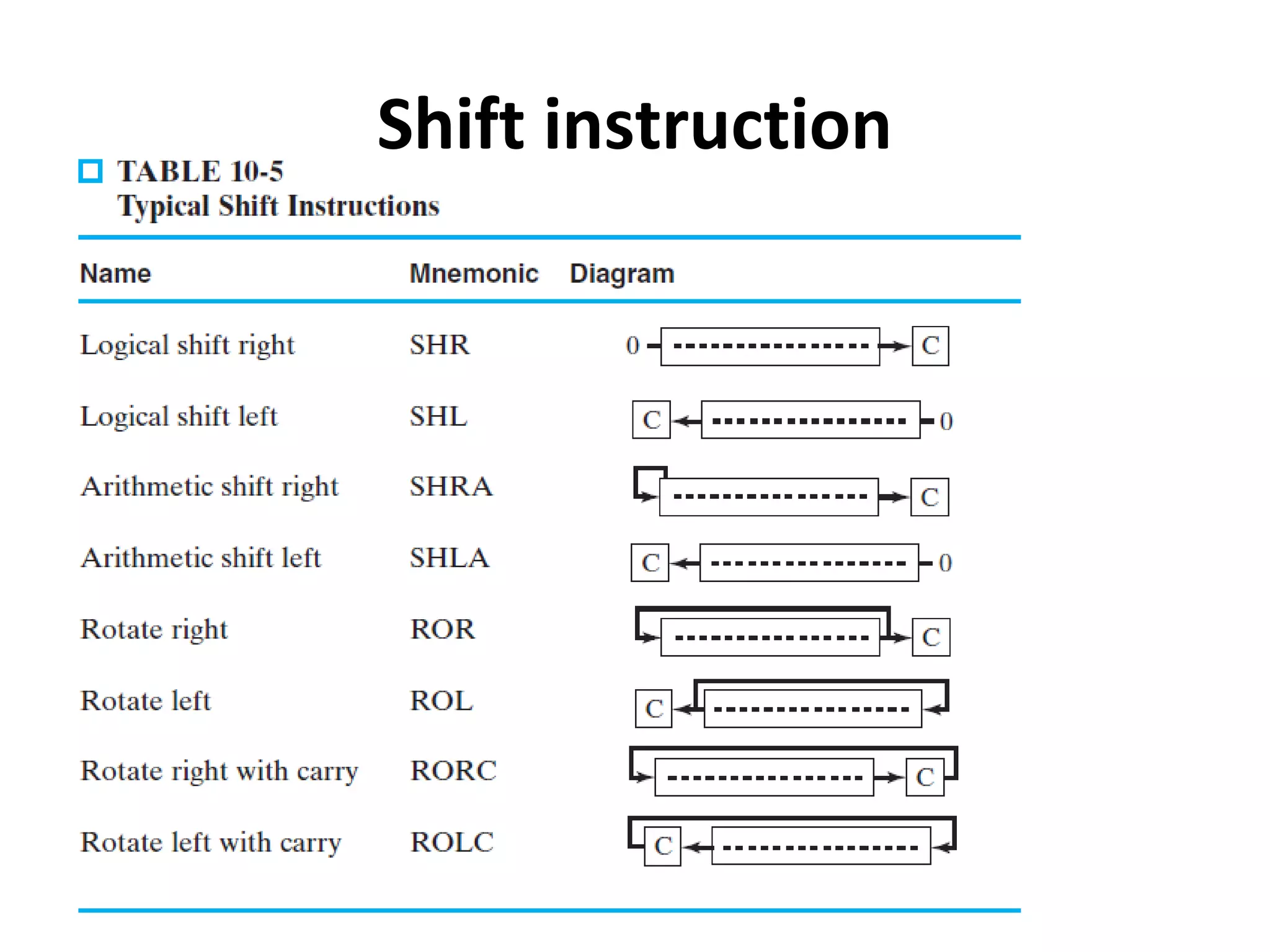
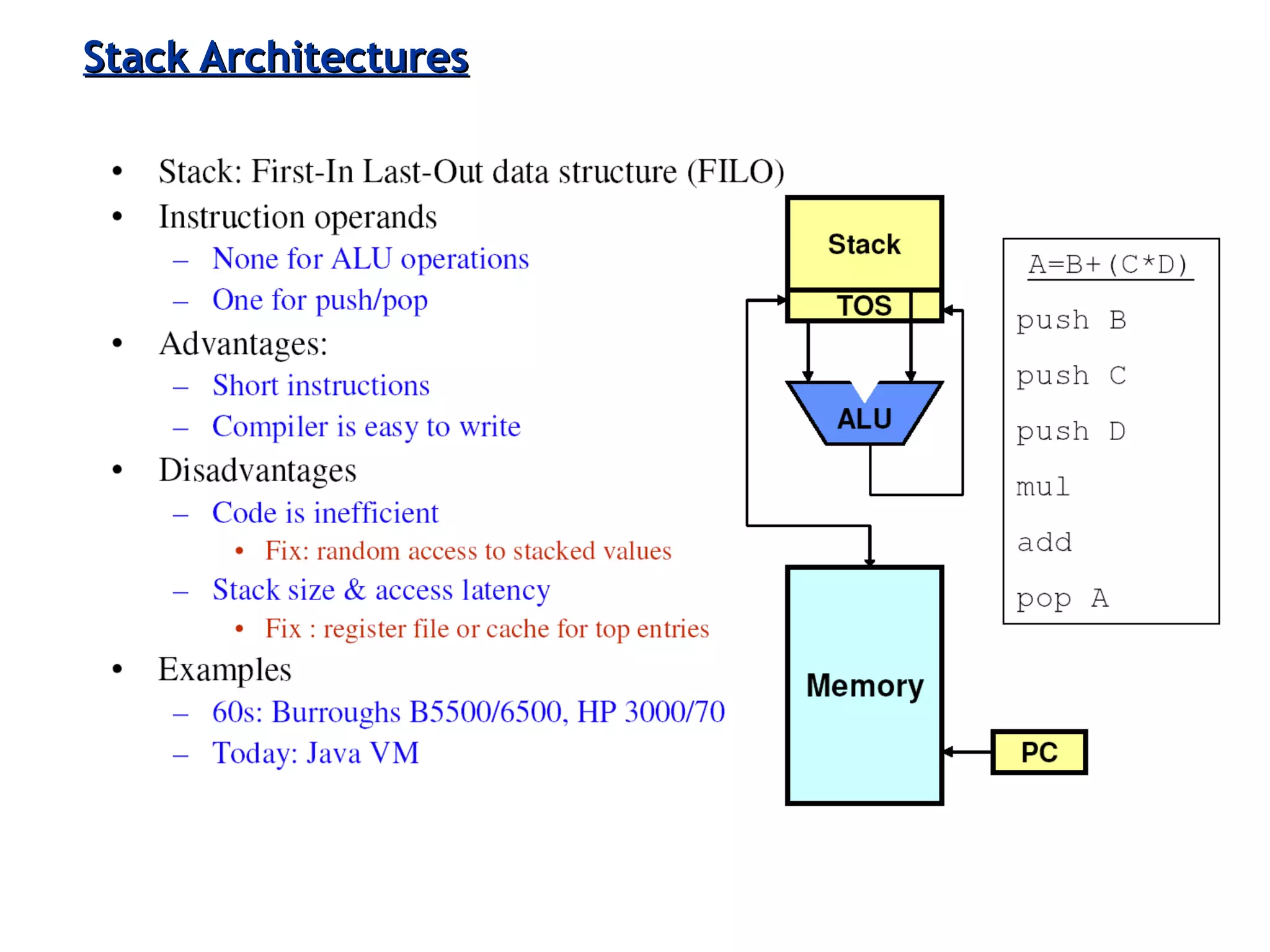
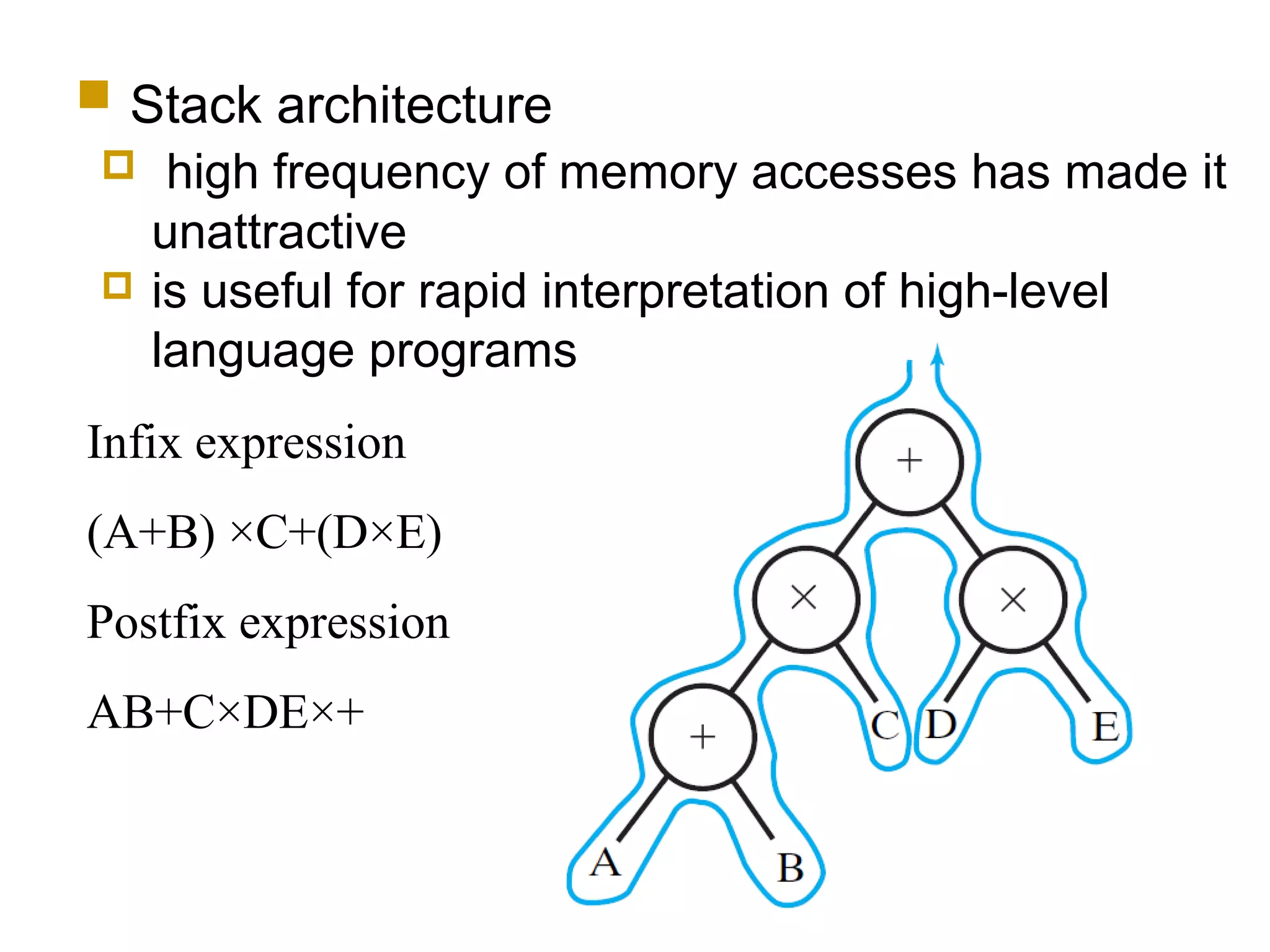
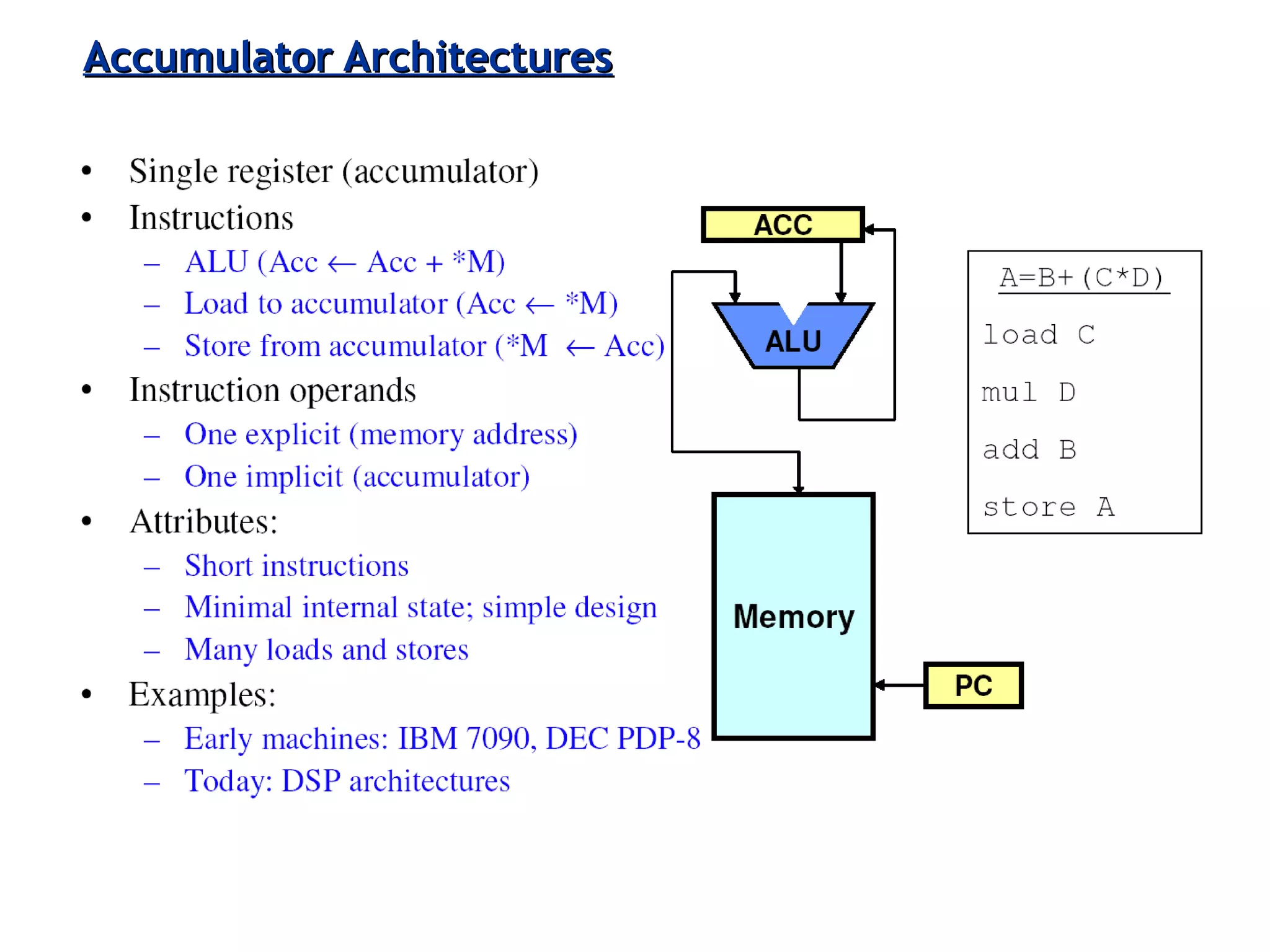
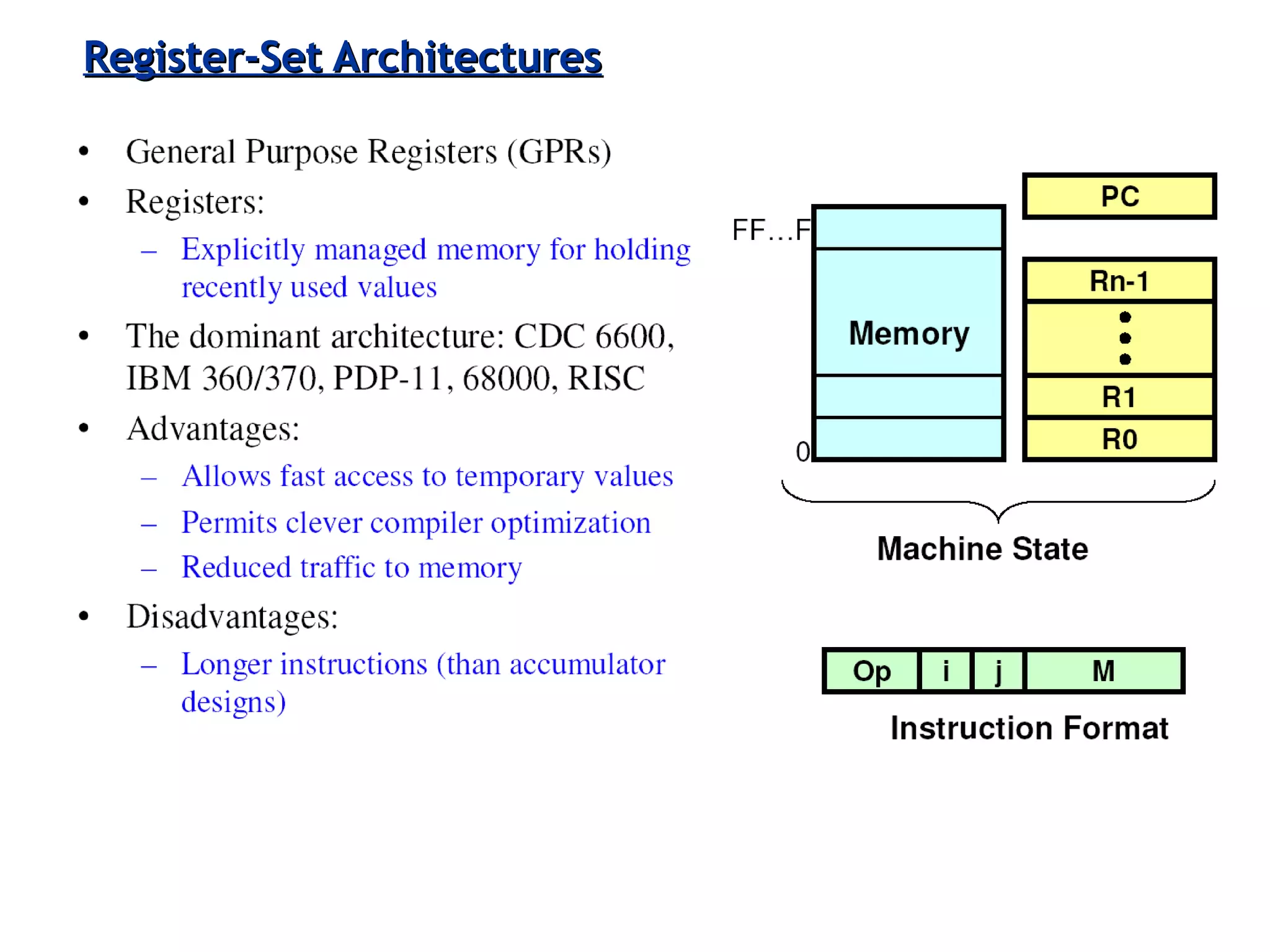
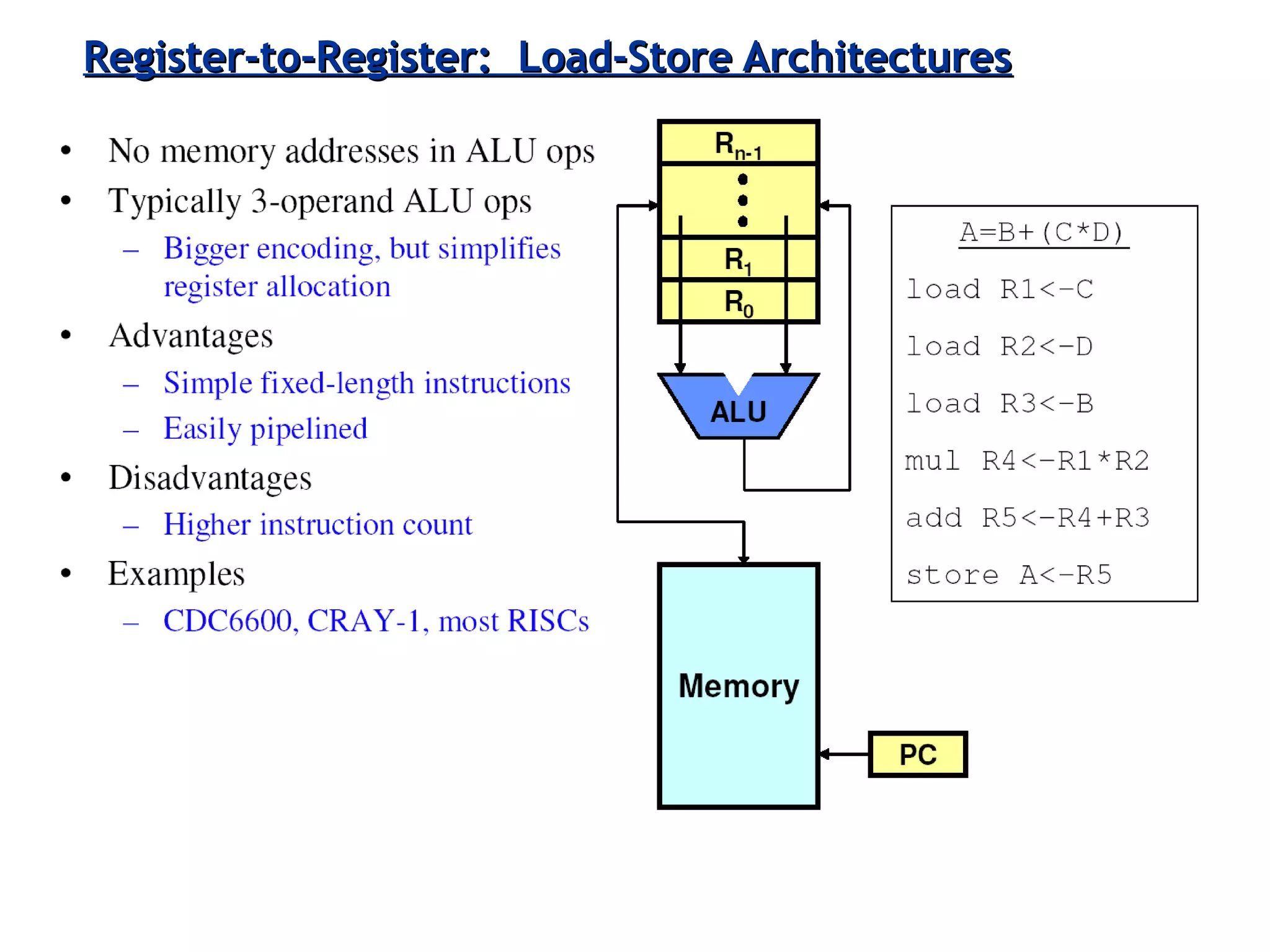
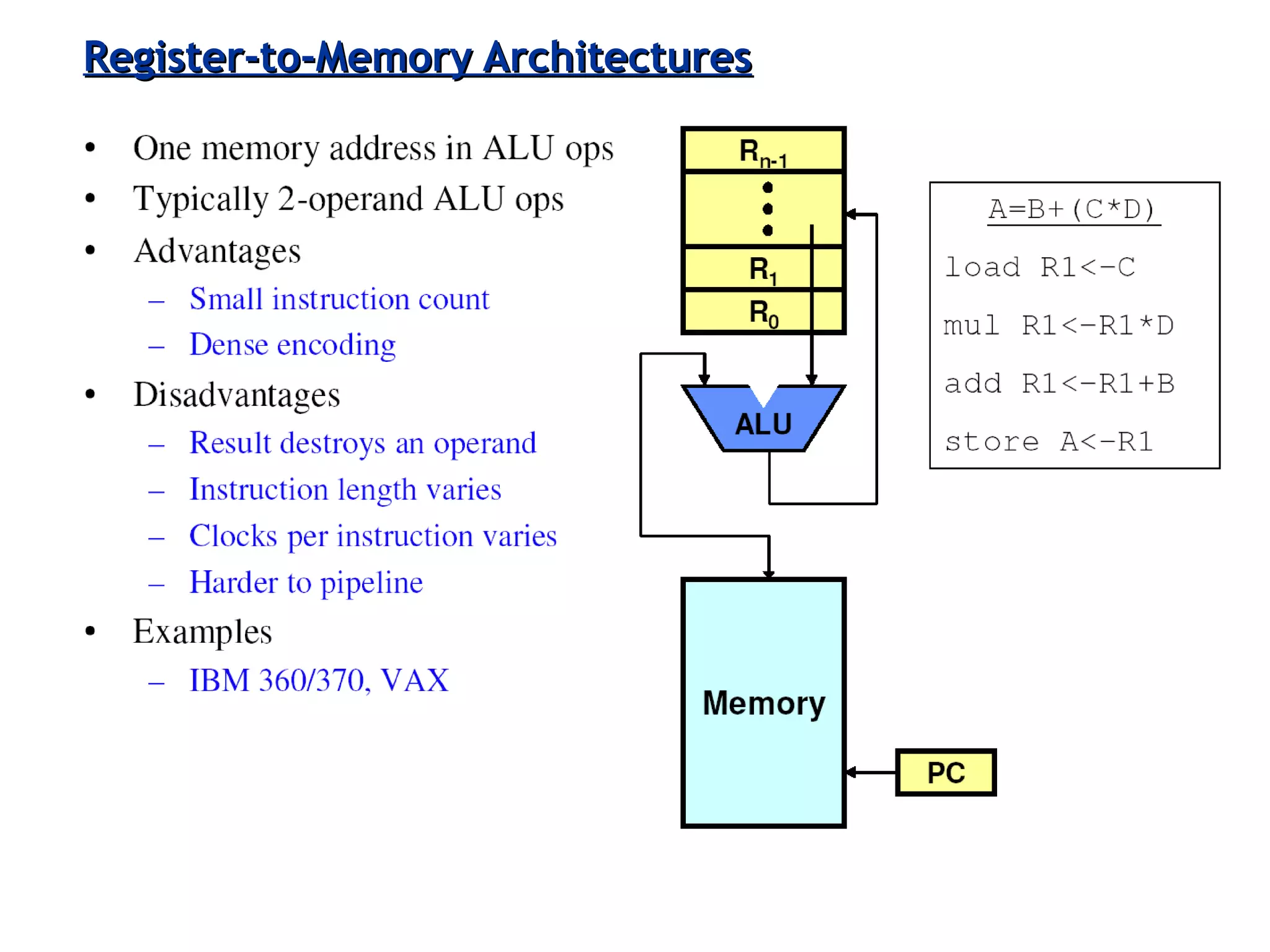


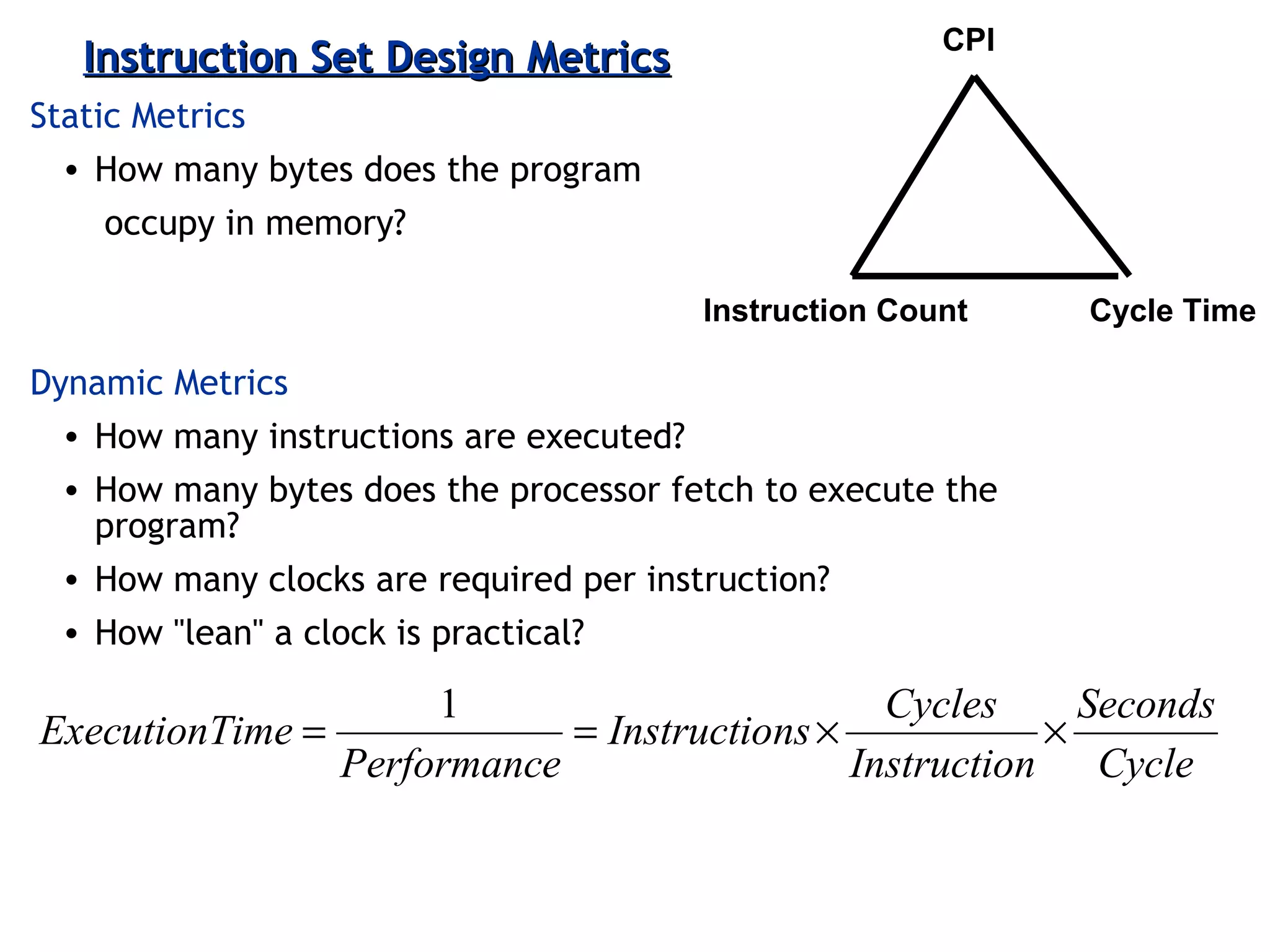






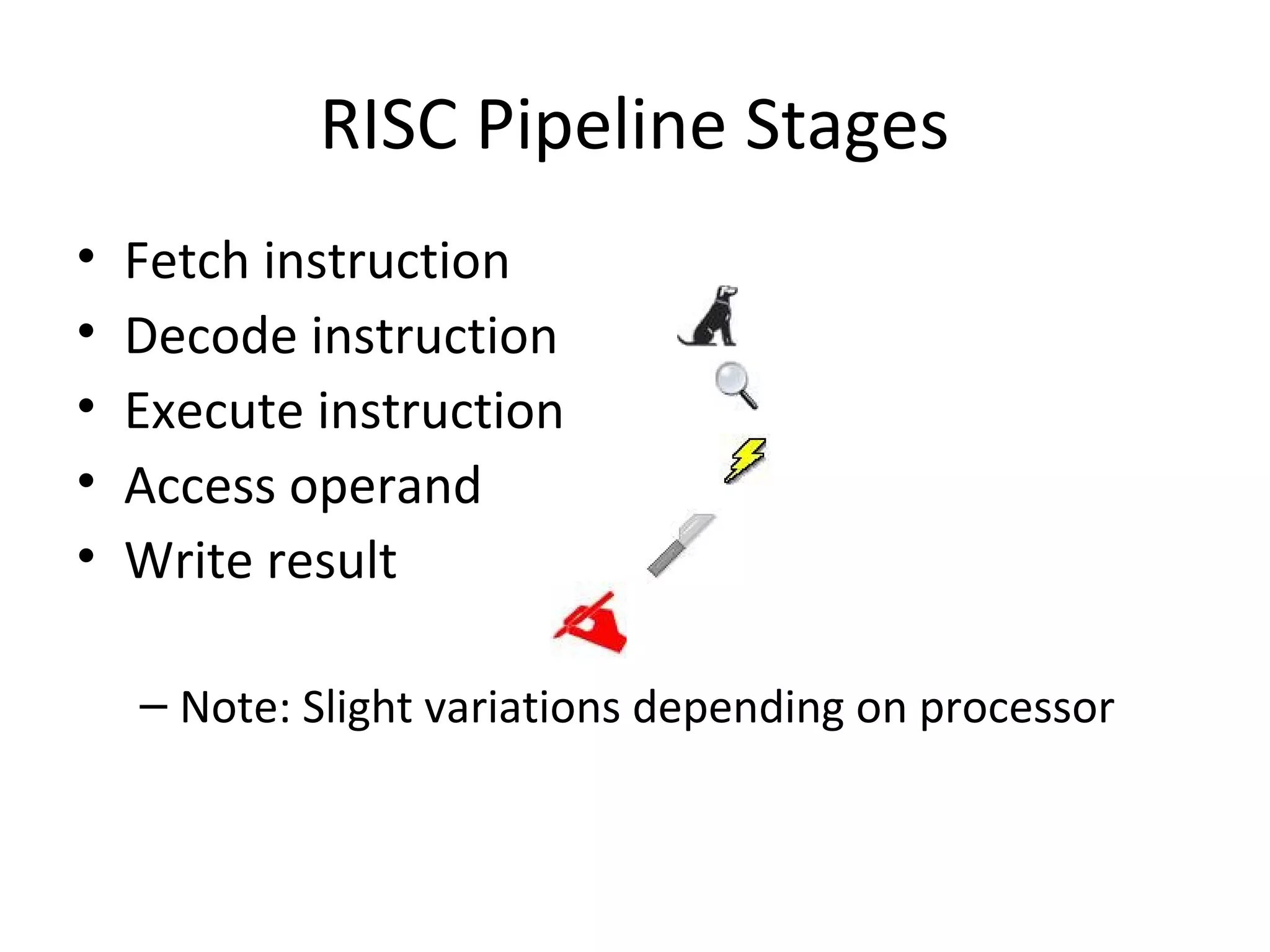
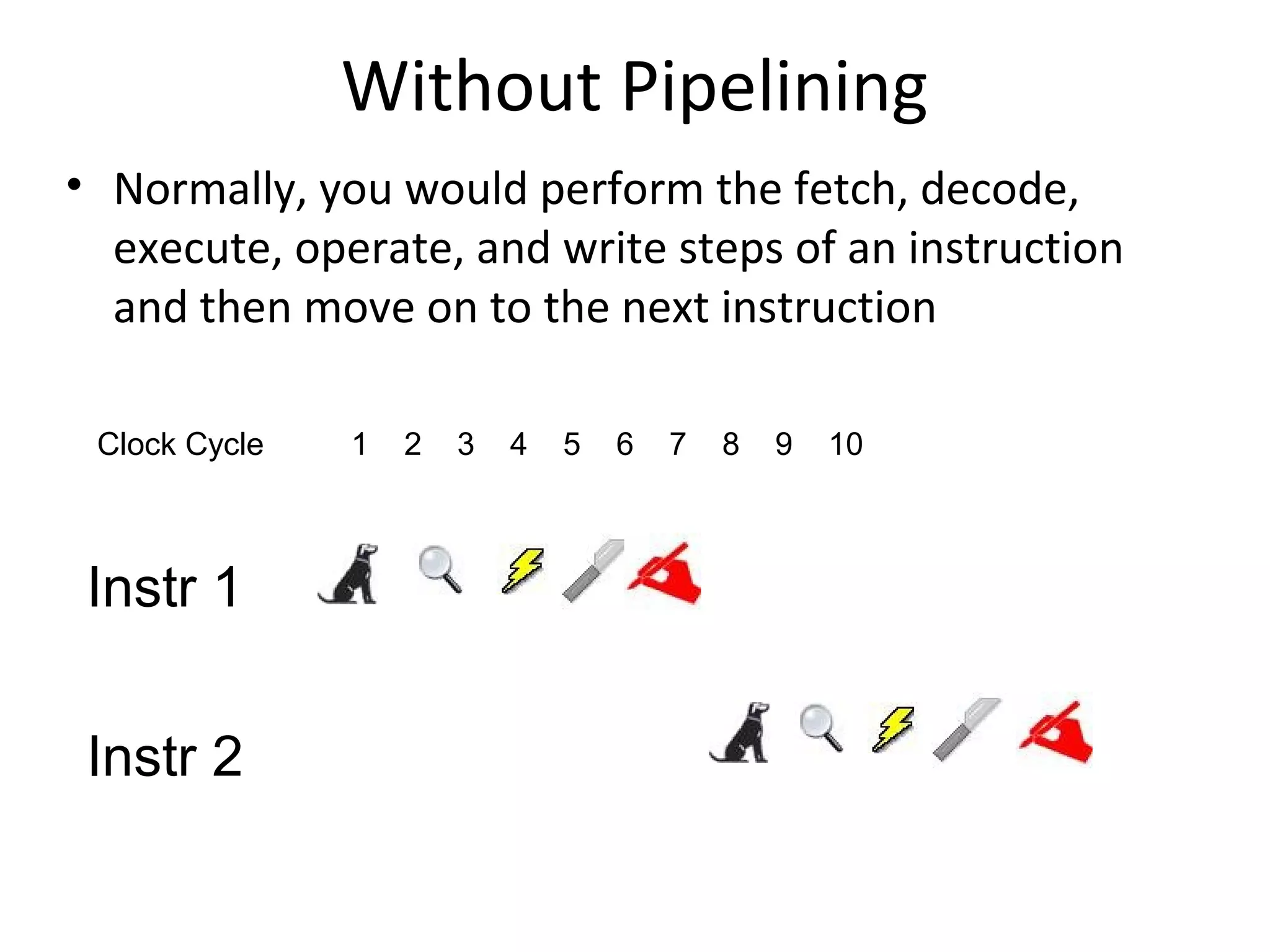
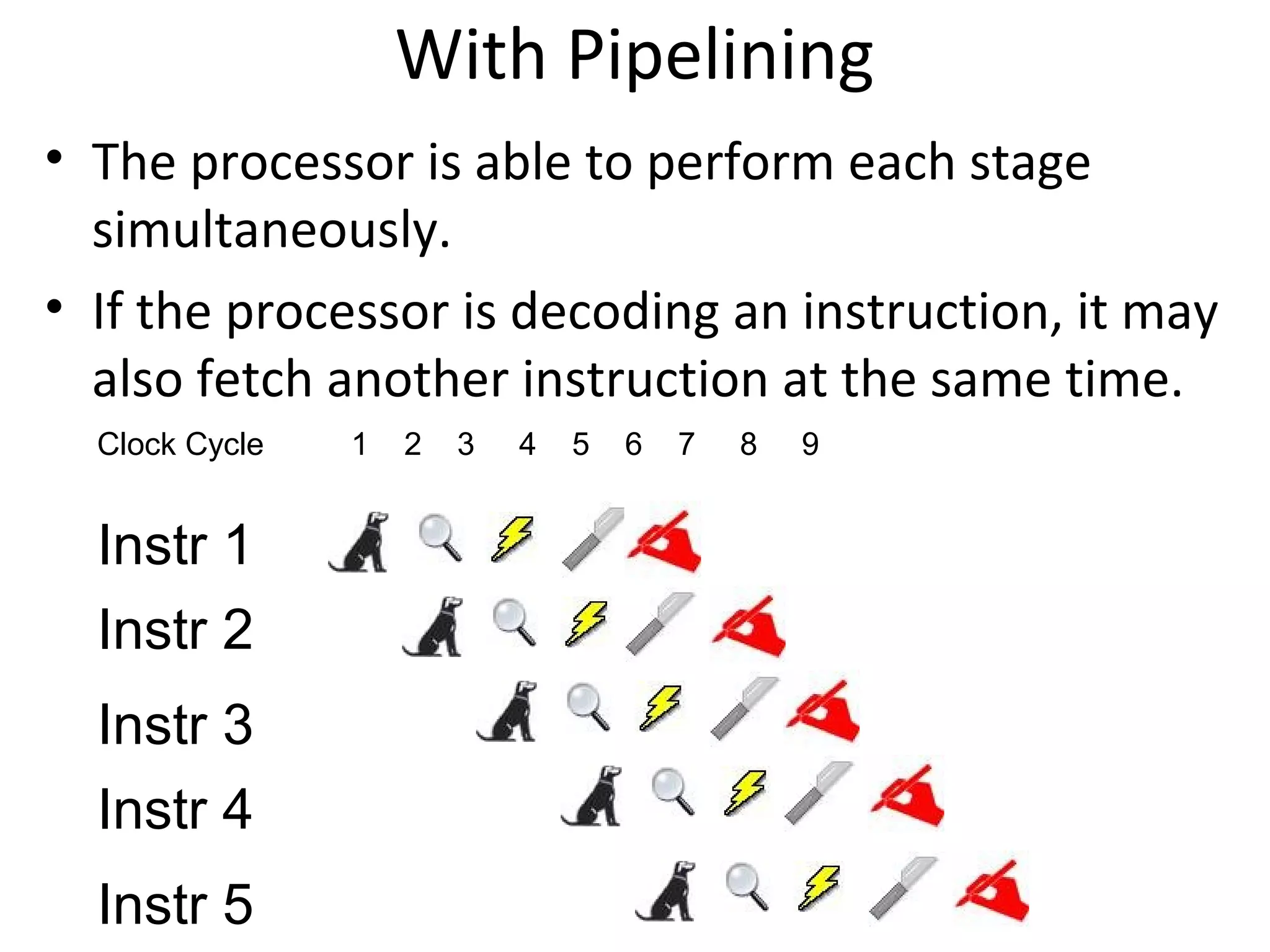



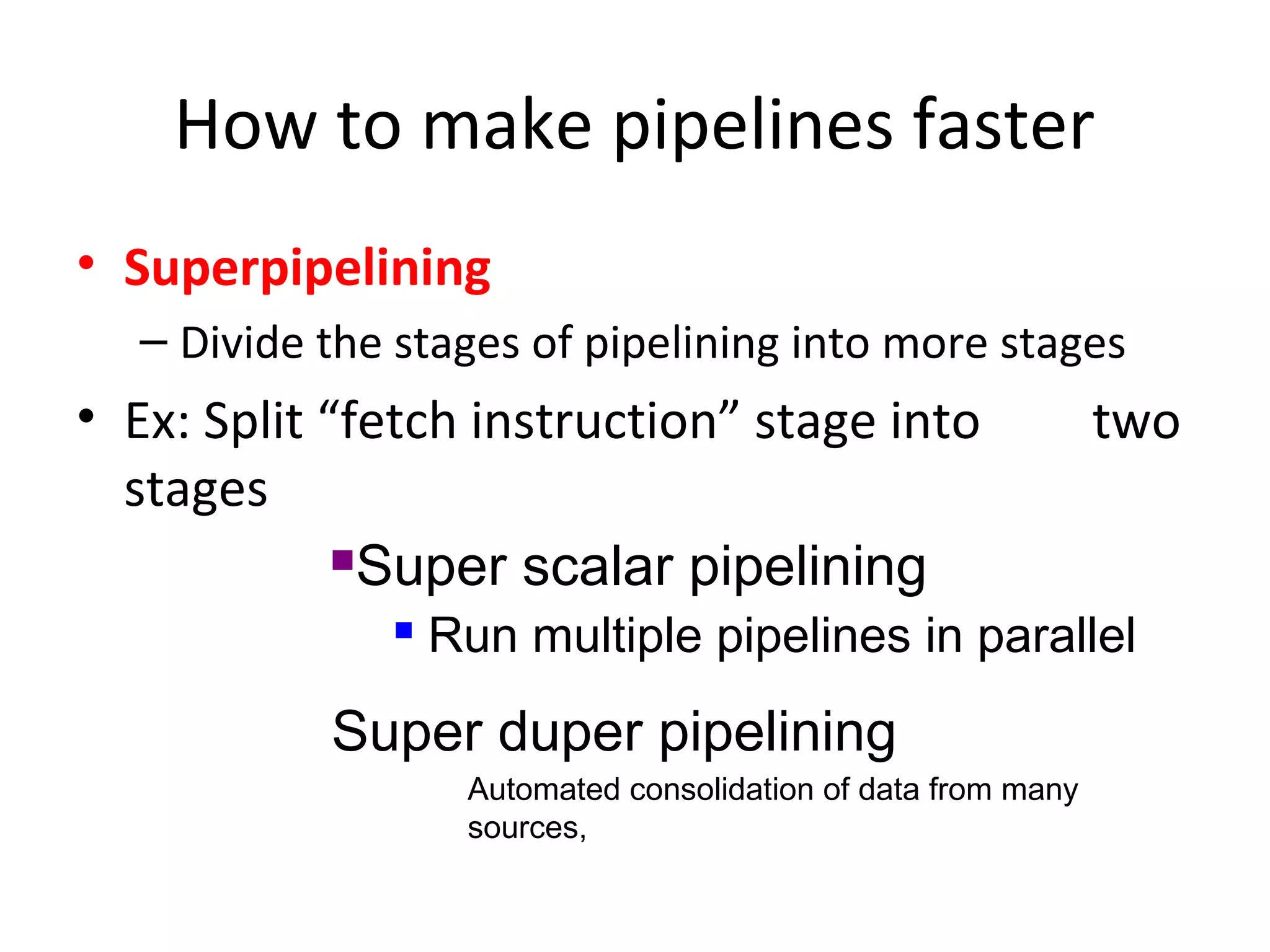





















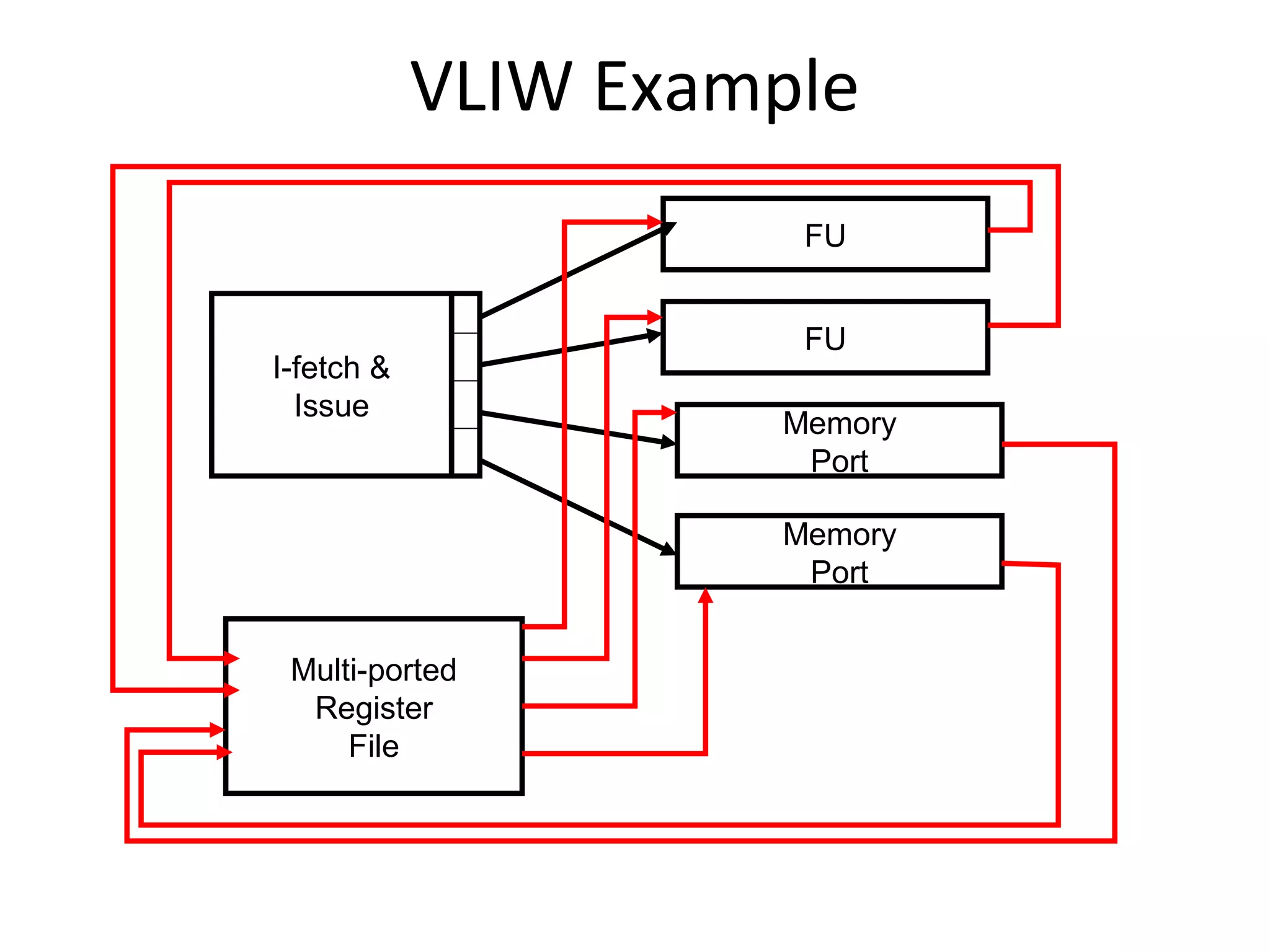
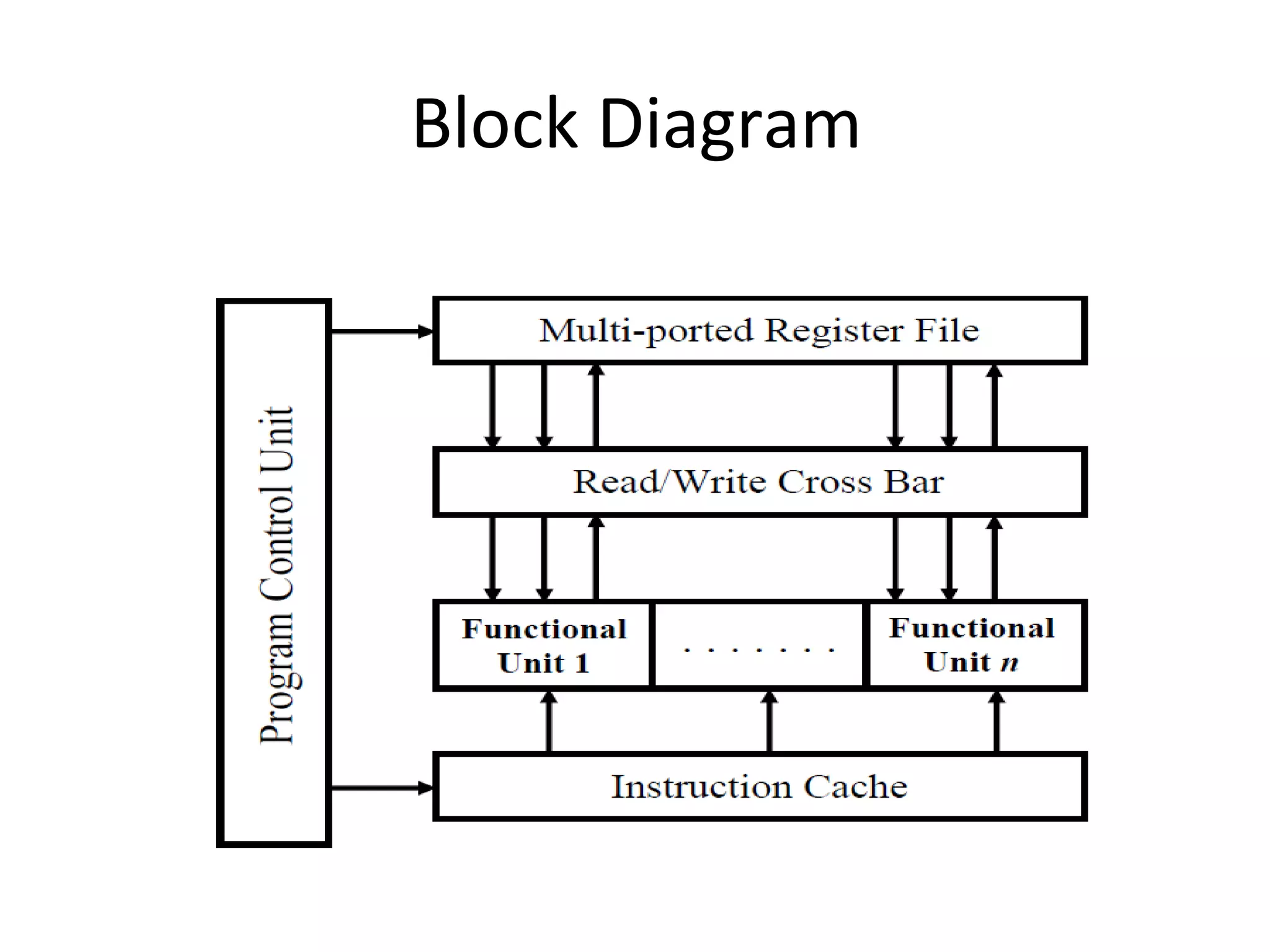



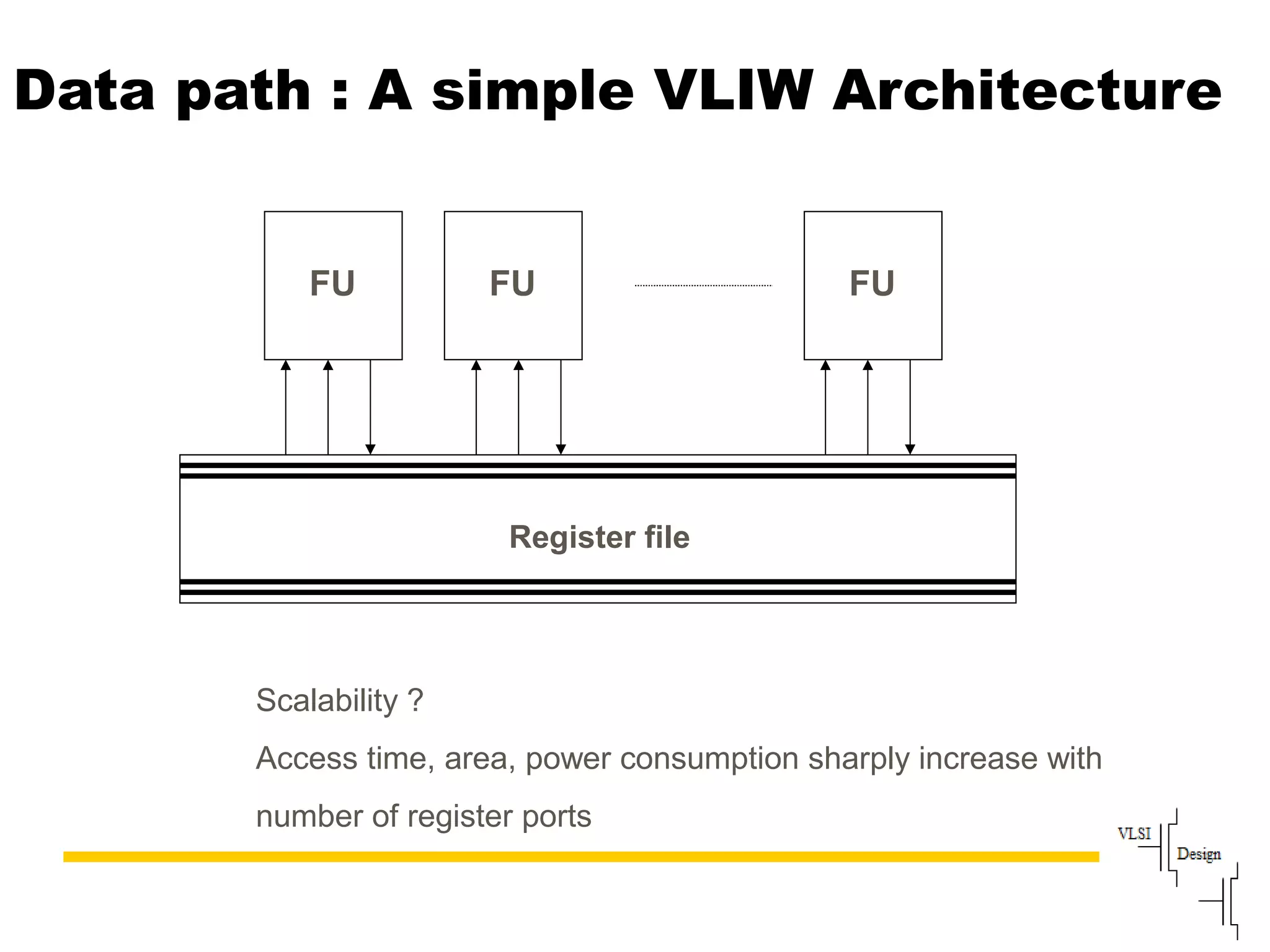
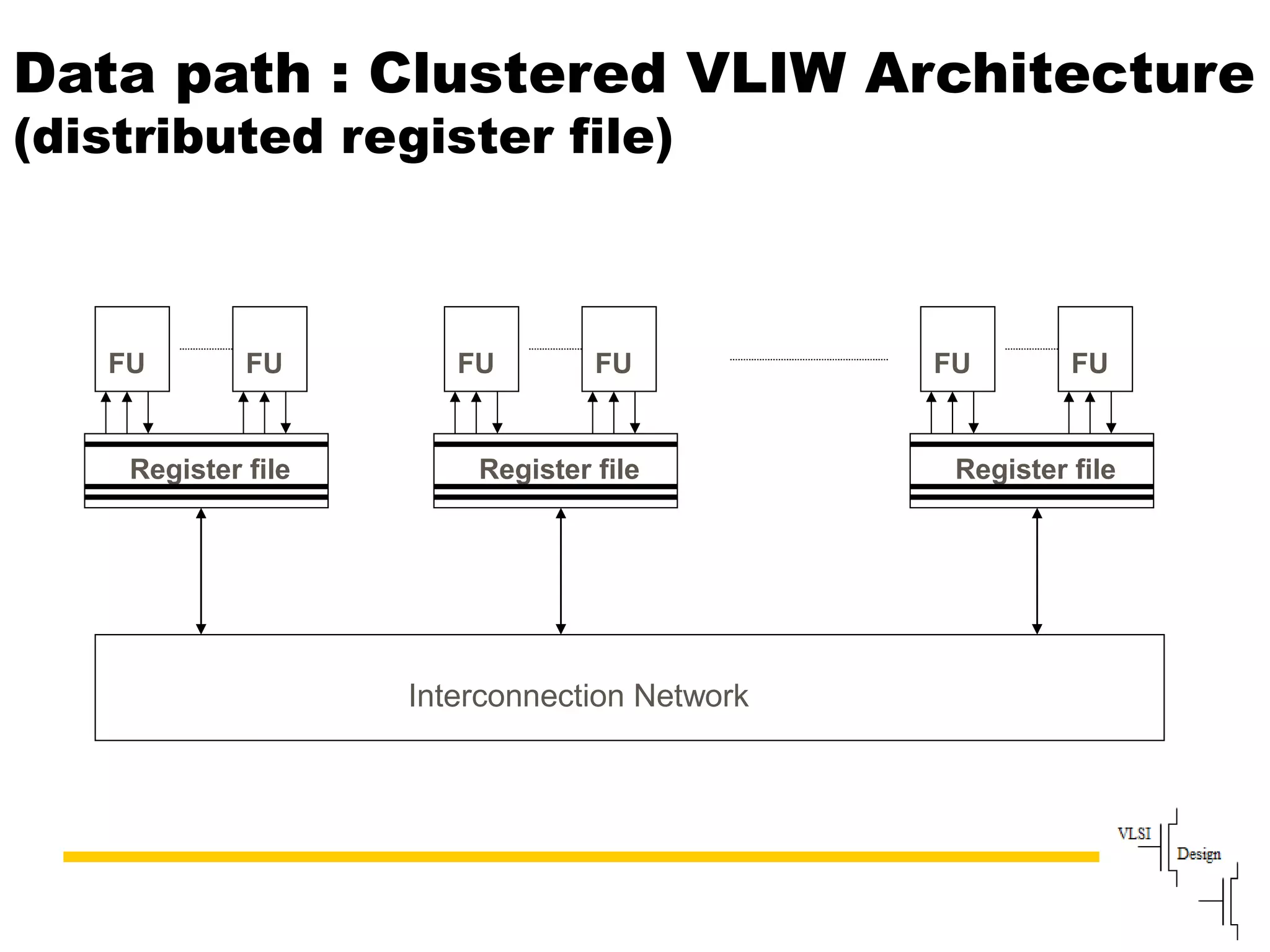

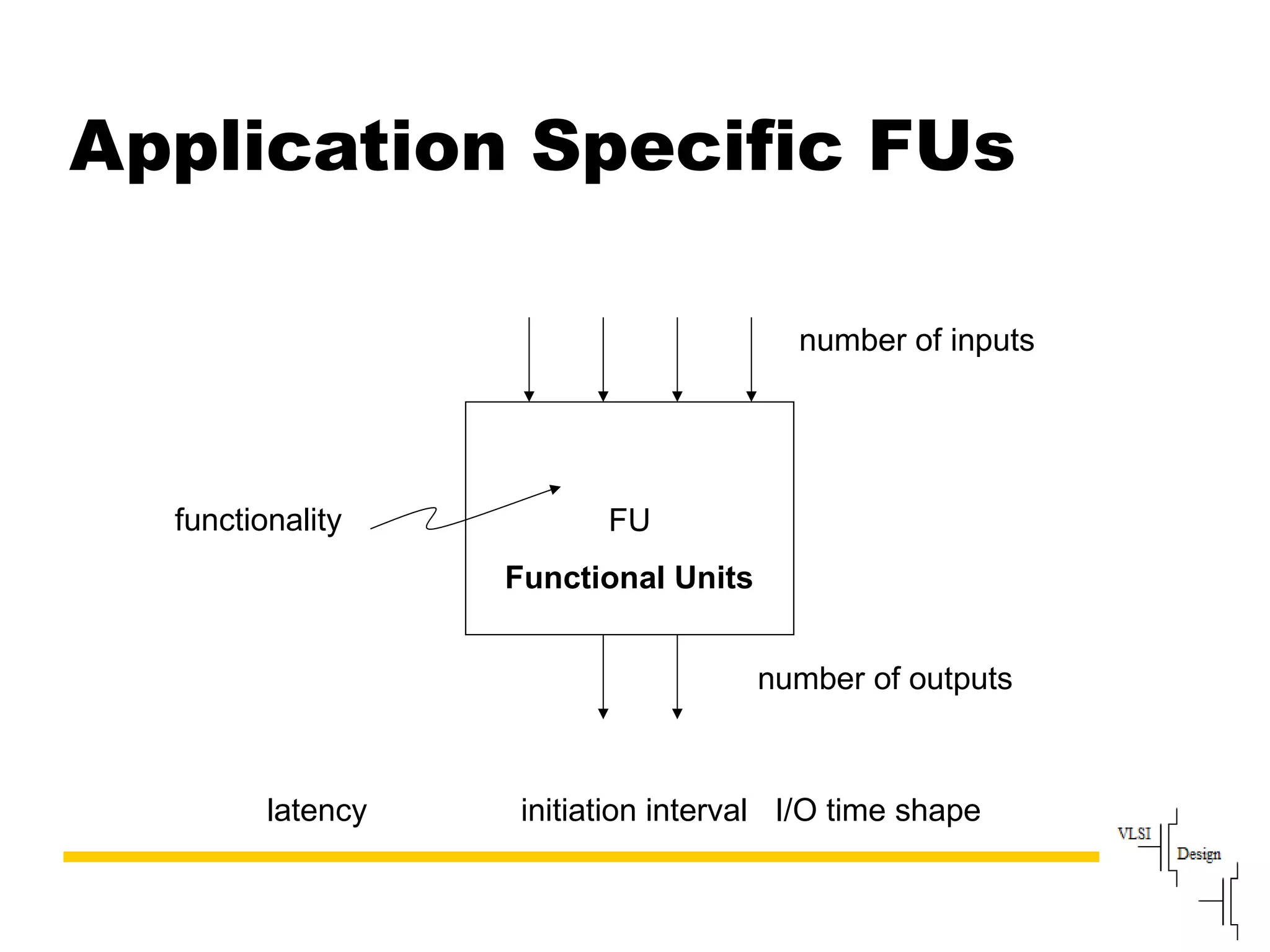


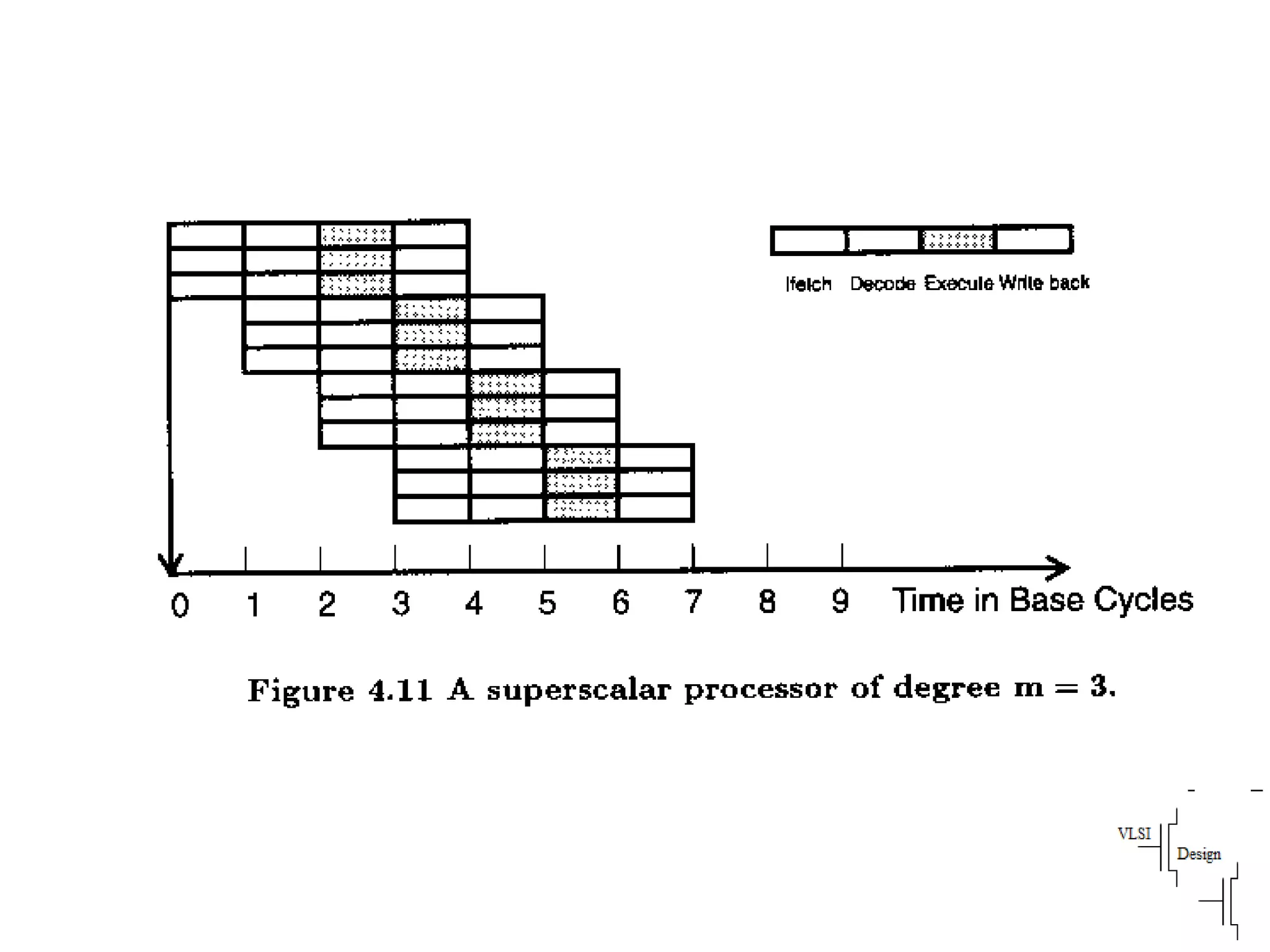
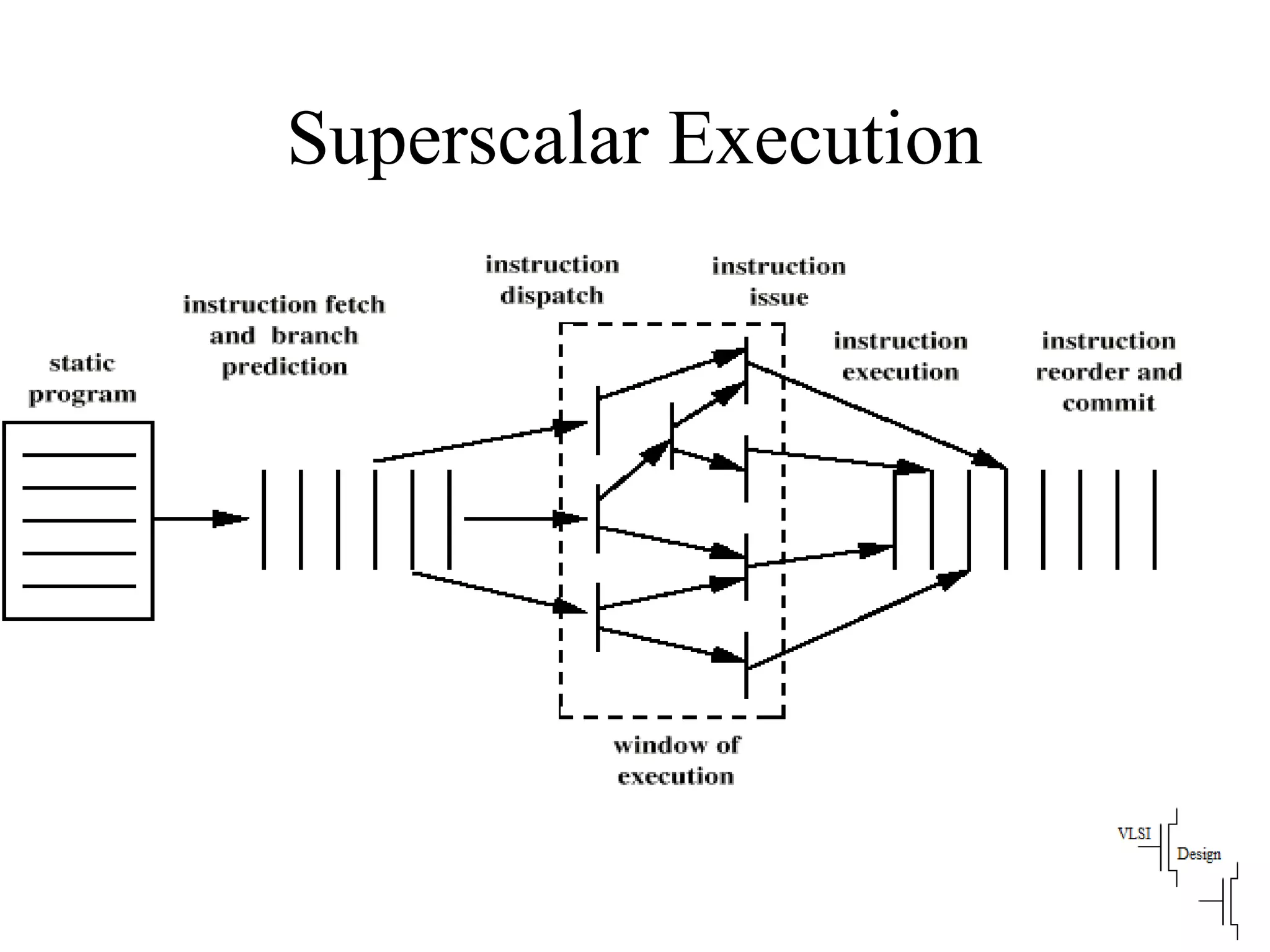

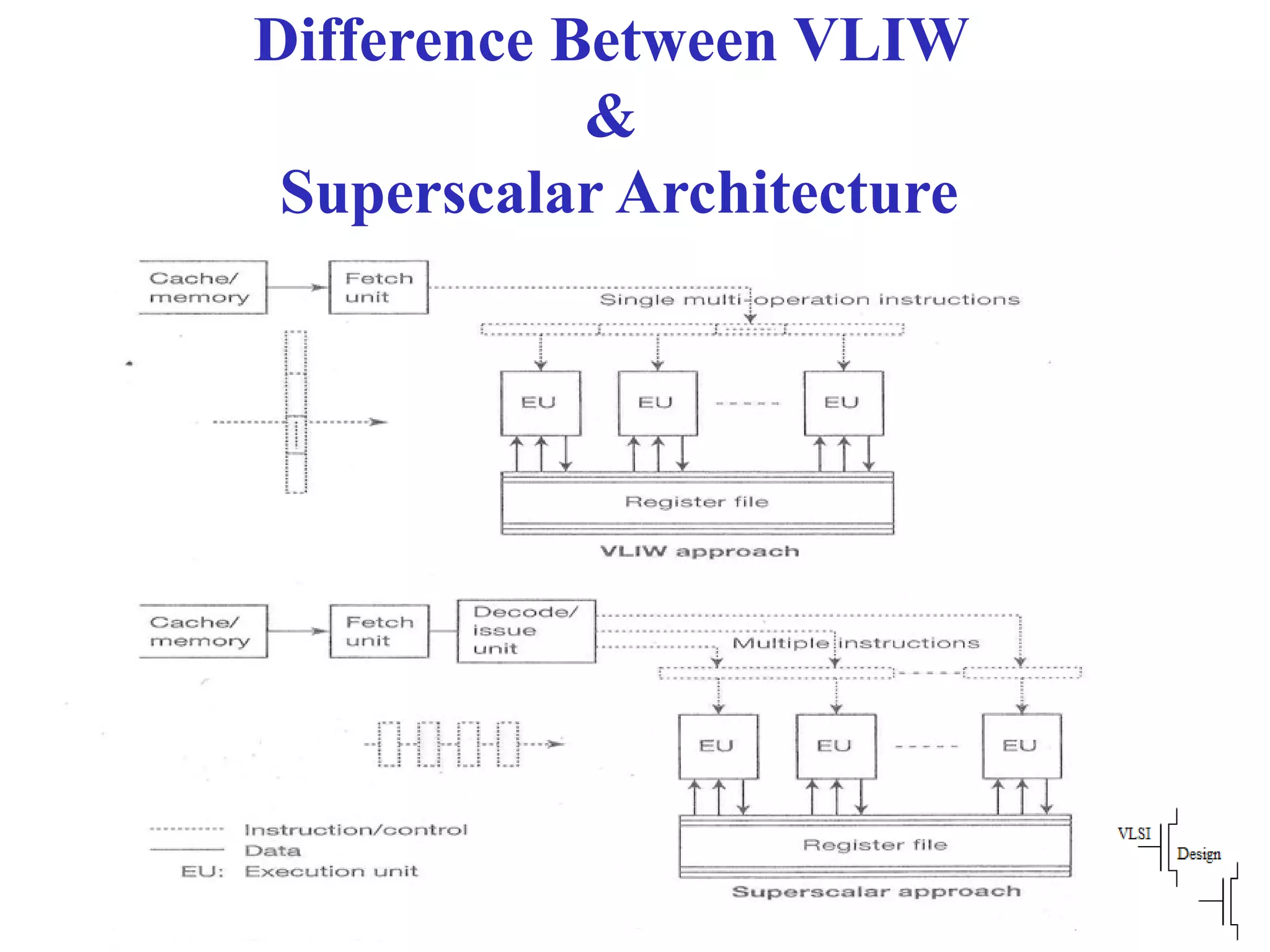


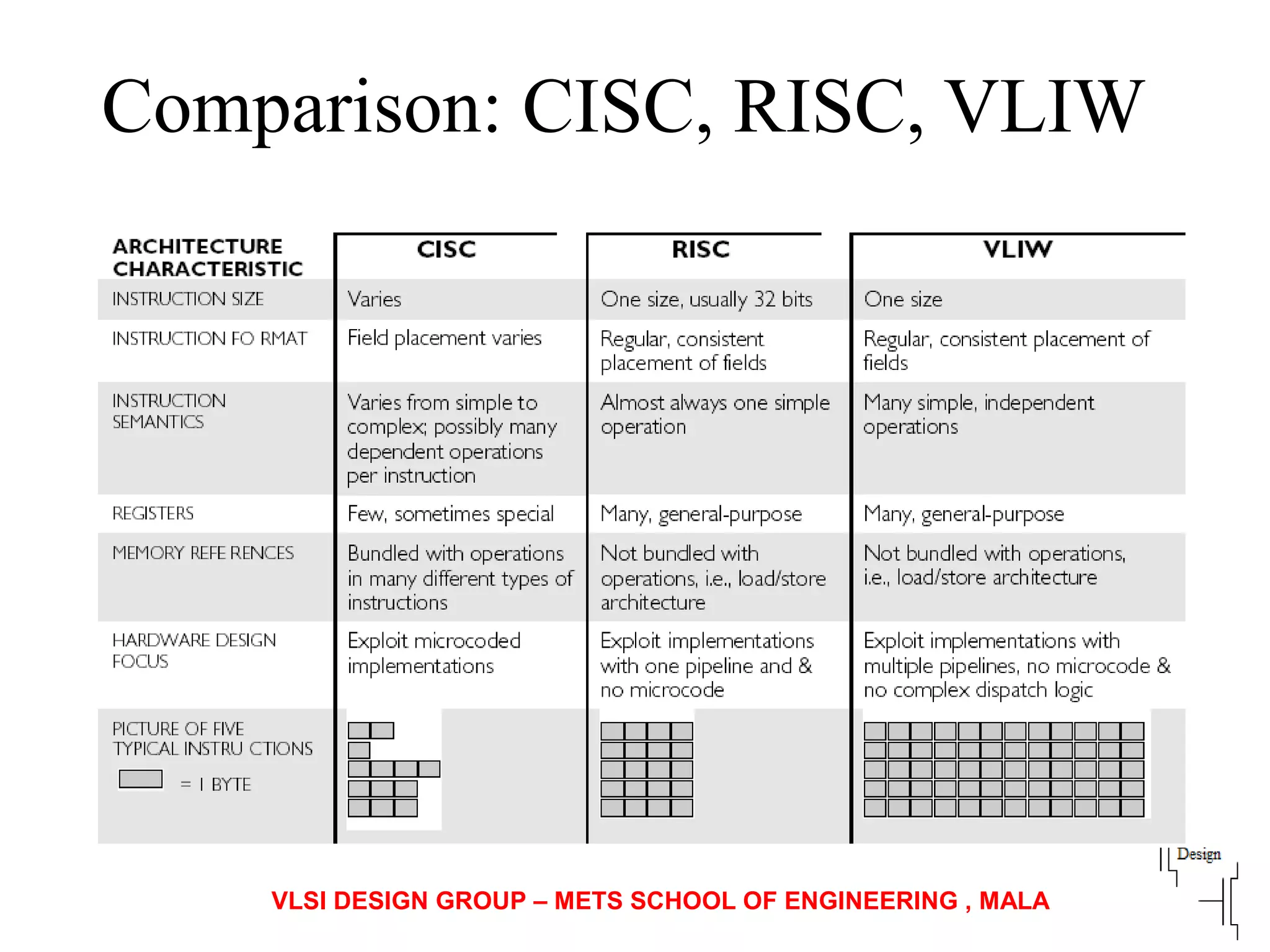
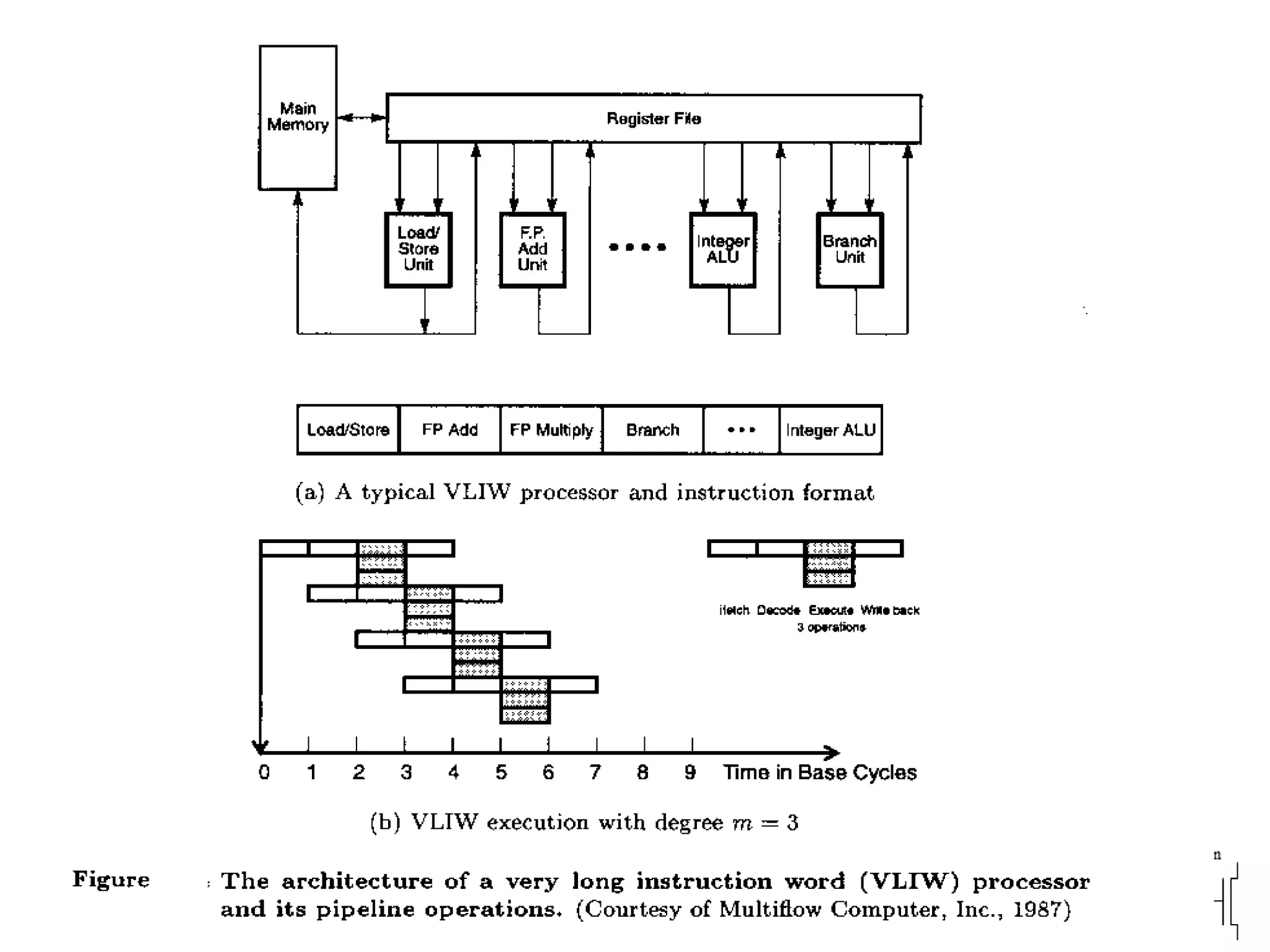


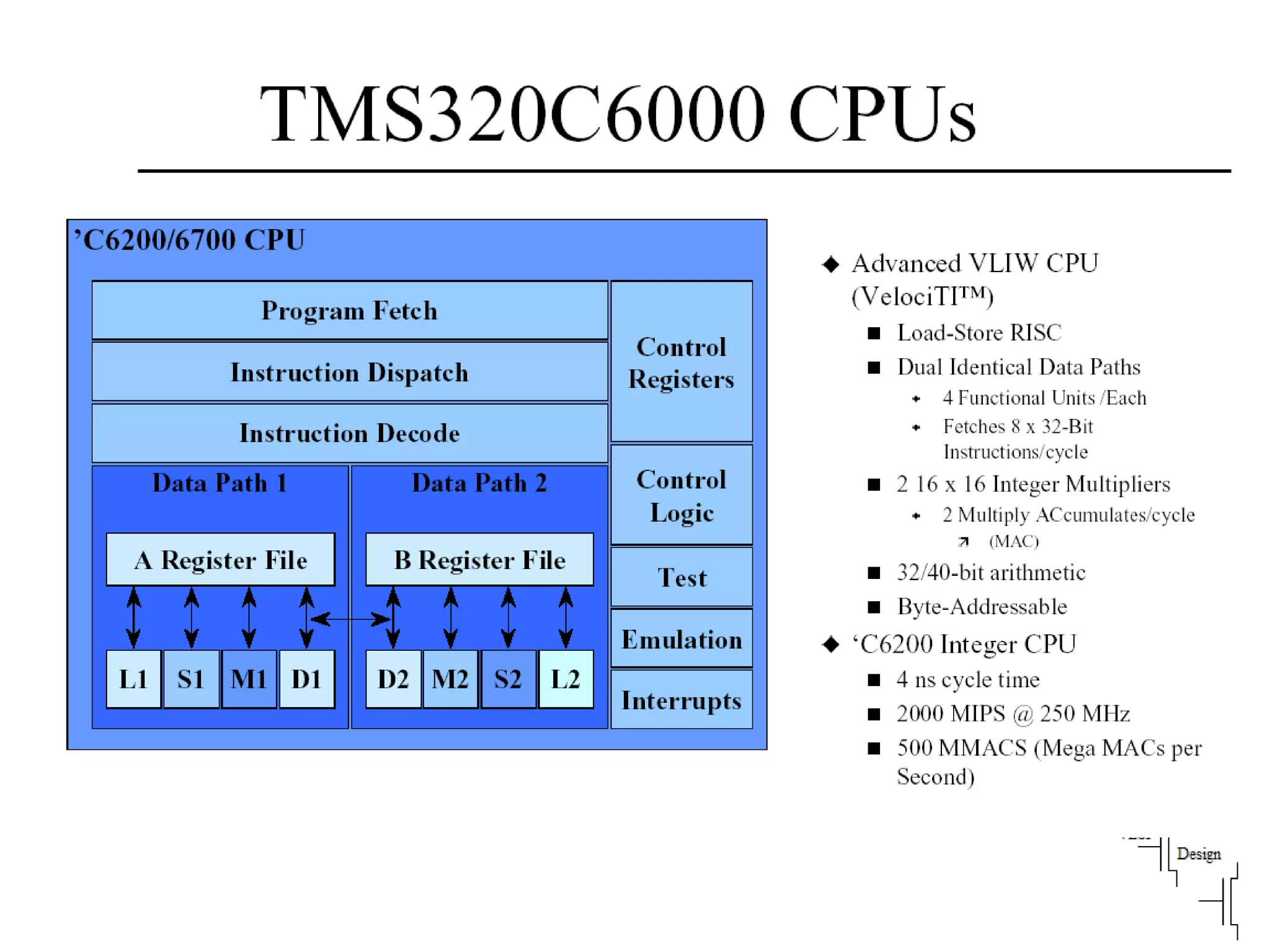



The document discusses instruction set architecture (ISA), describing it as the interface between software and hardware that defines the programming model and machine language instructions. It provides details on RISC ISAs like MIPS and how they aim to have simpler instructions, more registers, load/store architectures, and pipelining to improve performance compared to CISC ISAs. The document also discusses different types of ISA designs including stack-based, accumulator-based, and register-to-register architectures.























































































