Downloaded 306 times







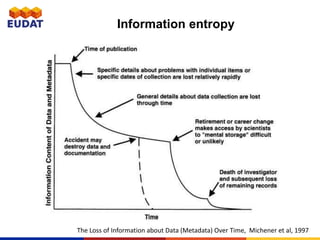




















The document provides an overview of metadata, emphasizing its importance in data discovery and understanding, as well as guidelines for creating quality metadata. It outlines types of metadata, the benefits of good practices, and the need for standardized descriptions to ensure interoperability and usability across different research communities. The document also details the EUDAT B2Find service, which facilitates metadata discovery across various data repositories.




















































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)

















