Download to read offline




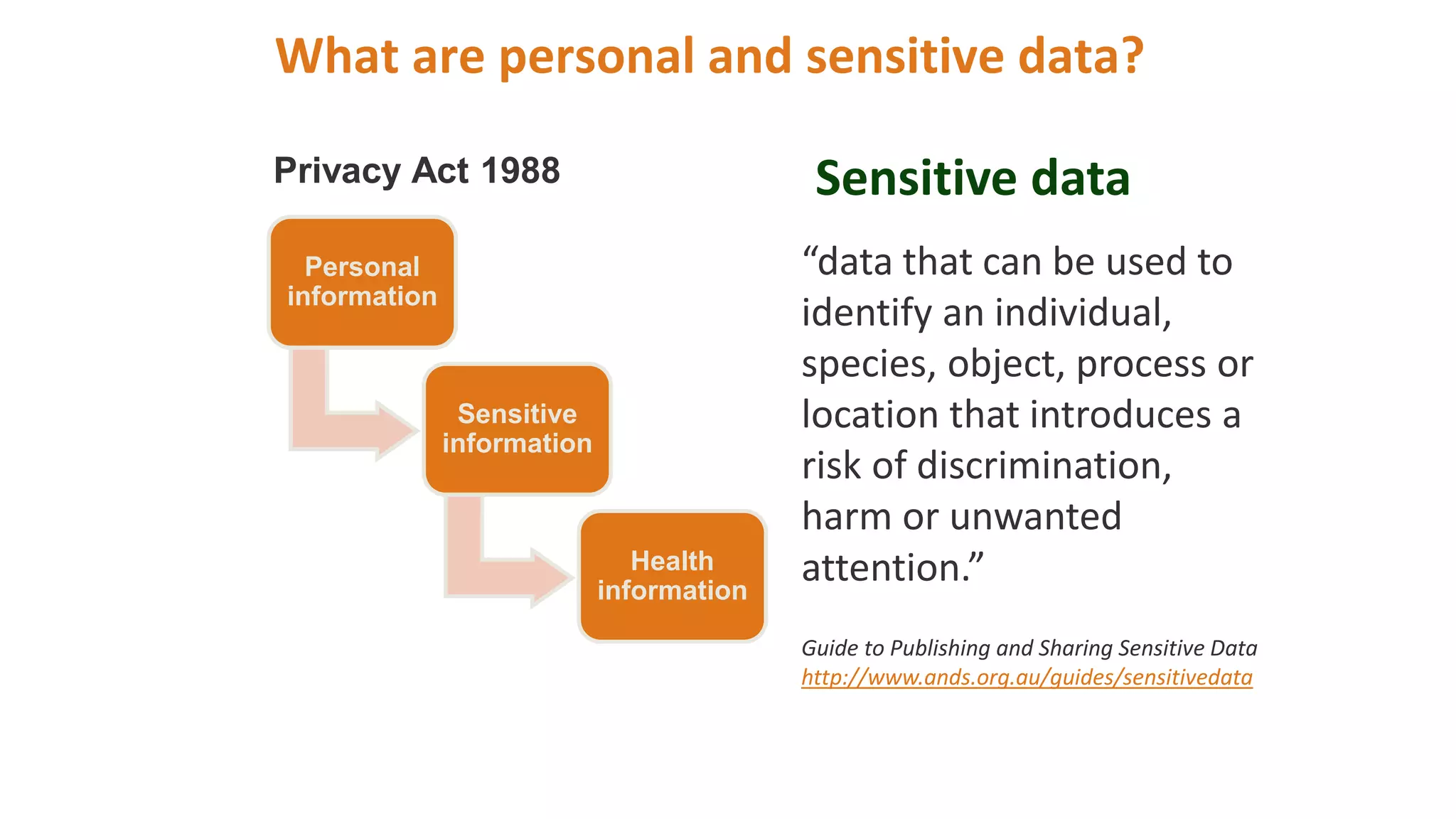



































The document outlines a course on managing and sharing research data, focusing on licensing and sensitive data management. It emphasizes the ethical aspects of data sharing, including informed consent and data de-identification strategies. Additionally, it highlights the importance of metadata in making research data discoverable, accessible, and reusable.























































































