


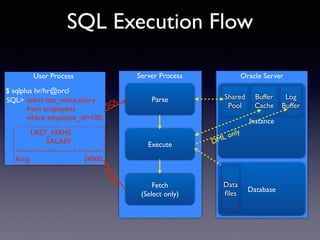
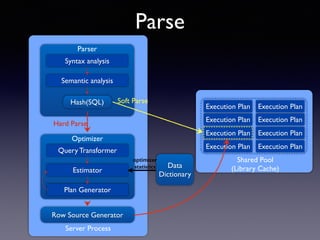
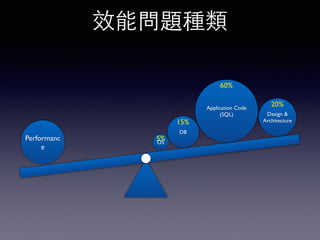
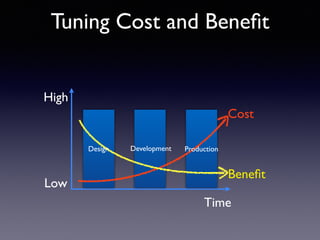
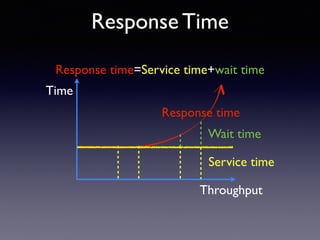
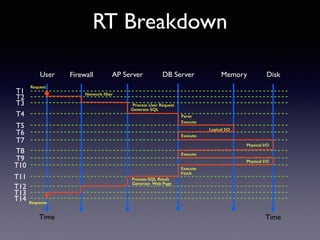





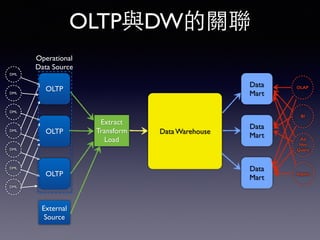



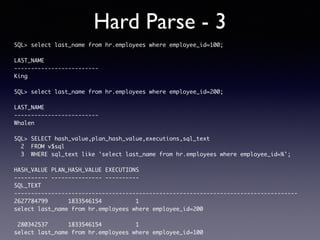



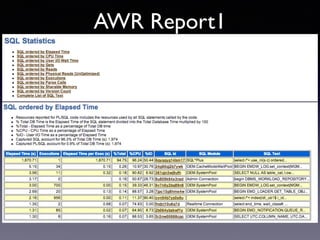


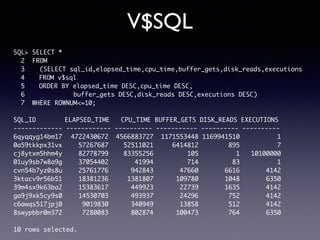
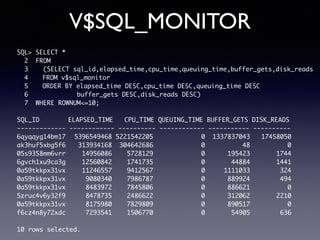
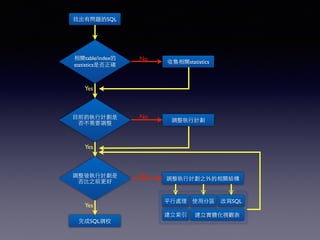
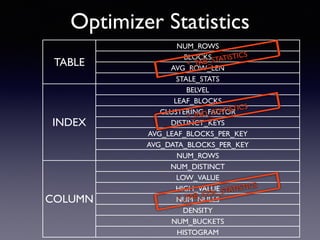



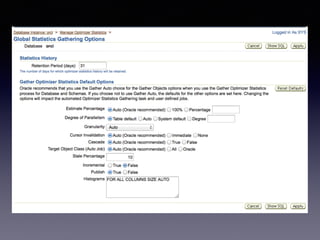



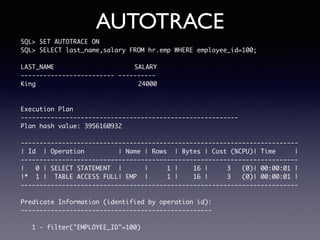
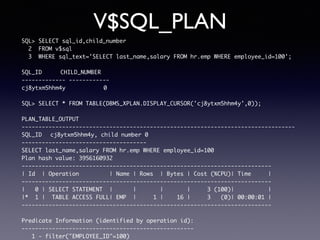

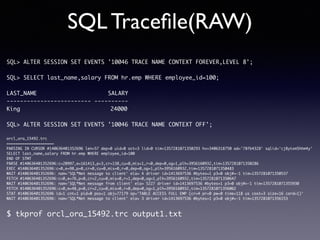
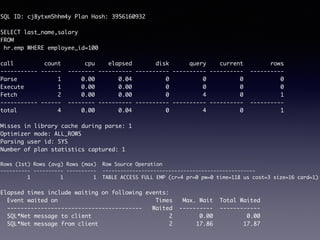
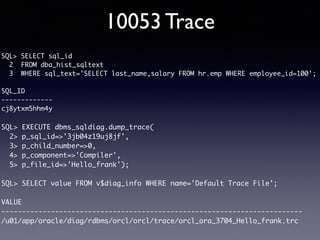

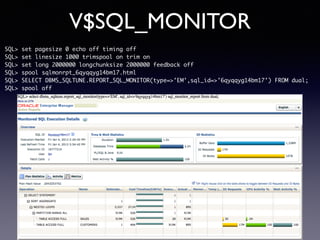


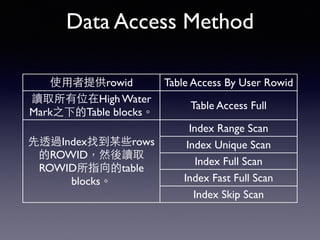
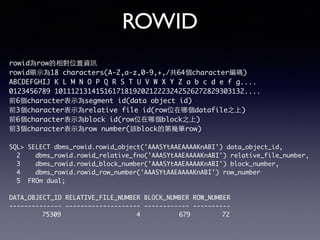


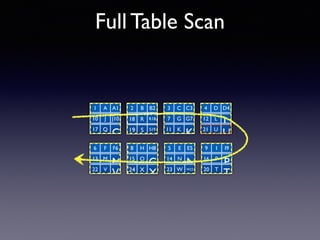
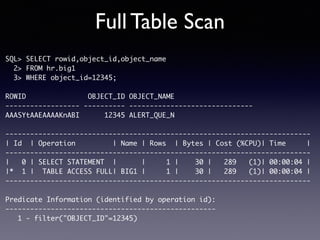
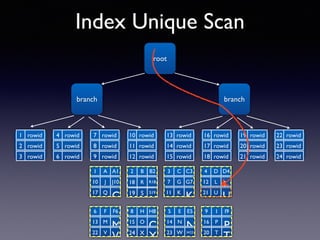
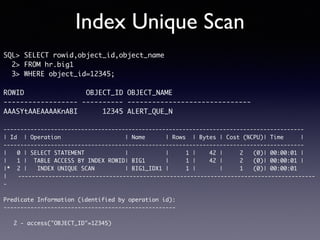
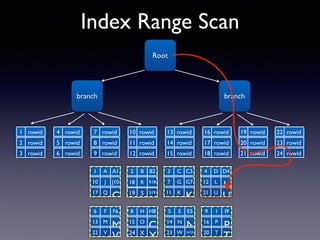
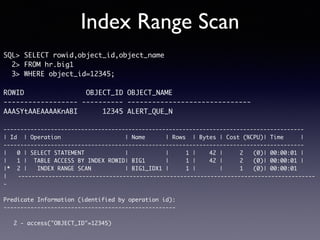
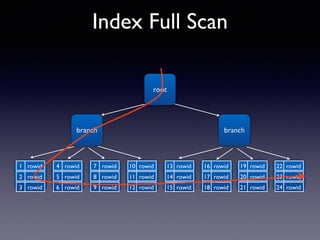

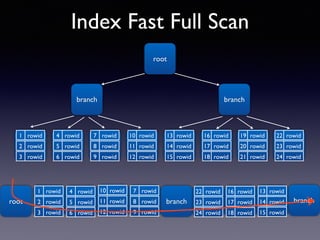





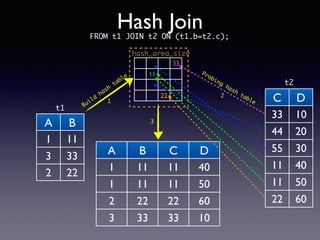

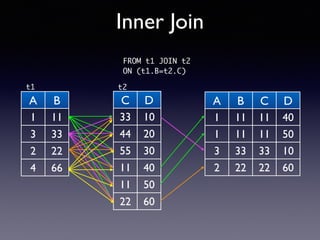
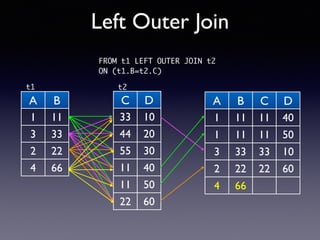
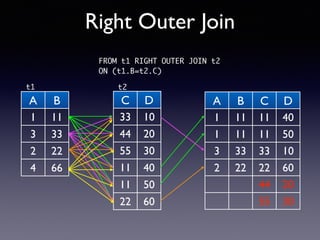
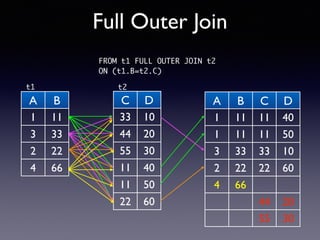
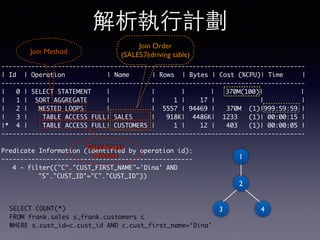
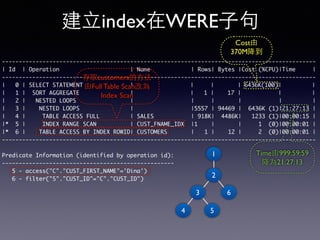
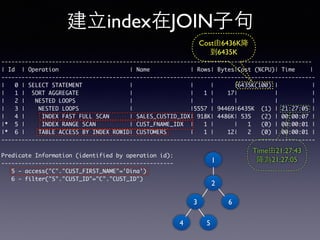
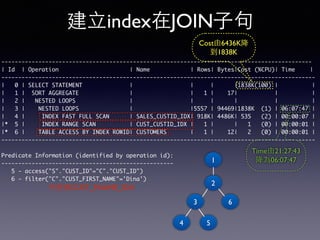
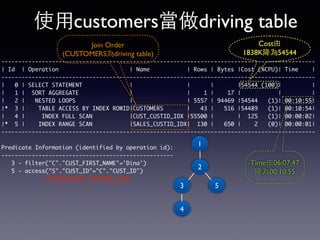
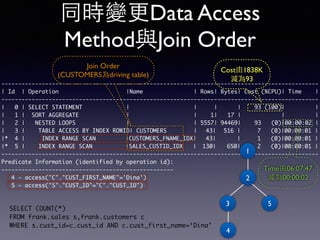
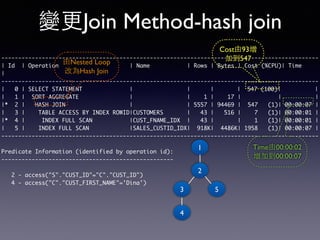
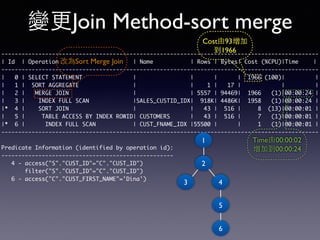






Oracle SQL tuning involves optimizing SQL statements for better performance. Key aspects of SQL tuning include identifying SQL statements with high resource consumption or response times using tools like ADDM, AWR, and V$SQL. Statements can then be tuned by gathering accurate optimizer statistics, adjusting the execution plan using hints, rewriting the SQL, or changing indexes and tables. Tuning is done at both the design and execution stages.


























































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







