Downloaded 128 times















The document discusses replication and consistency in Cassandra, focusing on the CAP theorem which balances consistency, availability, and partition tolerance. It emphasizes the importance of configuring replication strategies at the keyspace level, including simple and network topology strategies. Additionally, it addresses consistency levels for reads and writes, and how systems can maintain consistency during failures.
Christopher Bradford introduces himself as a Solutions Architect at DataStax.
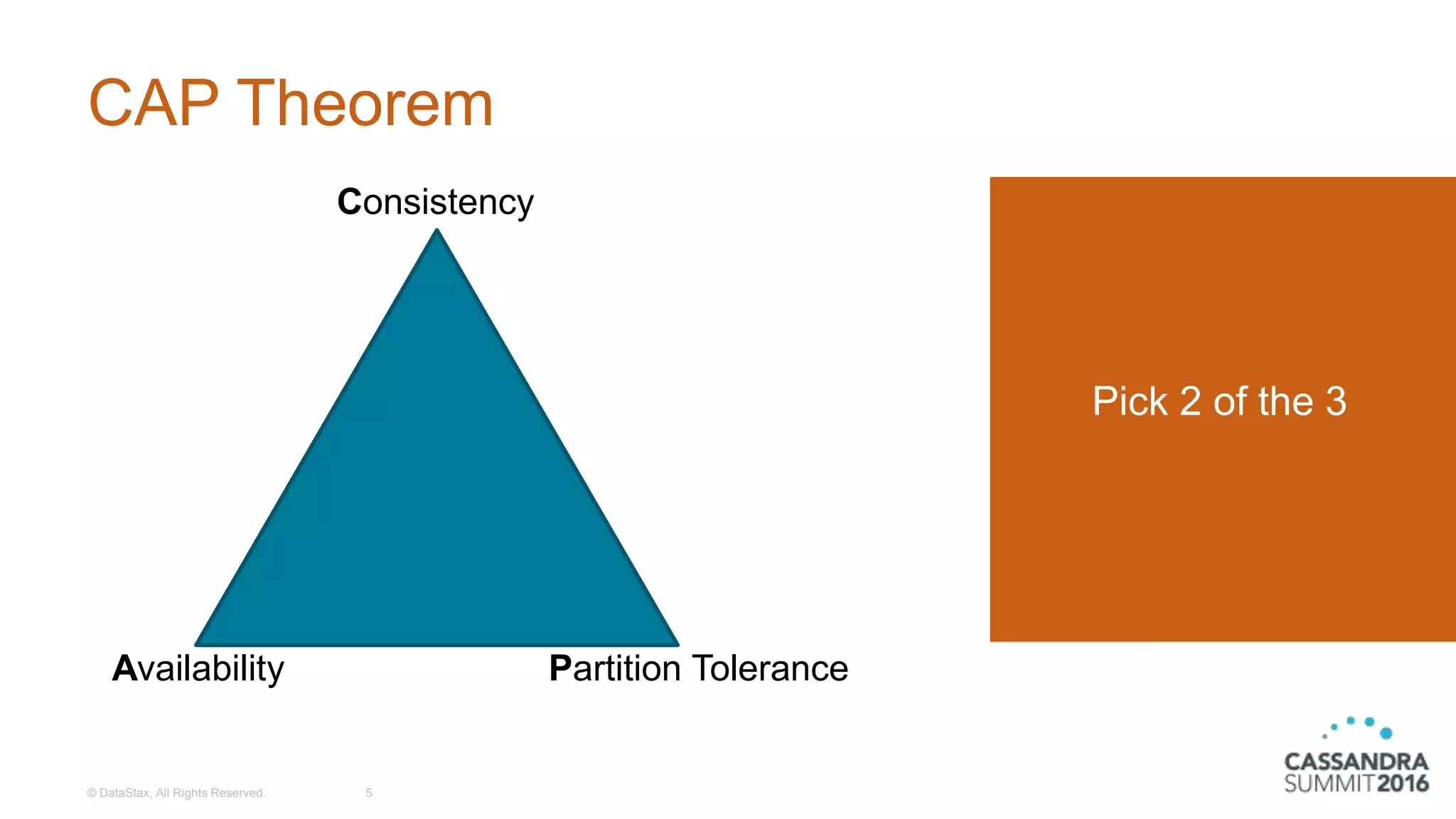
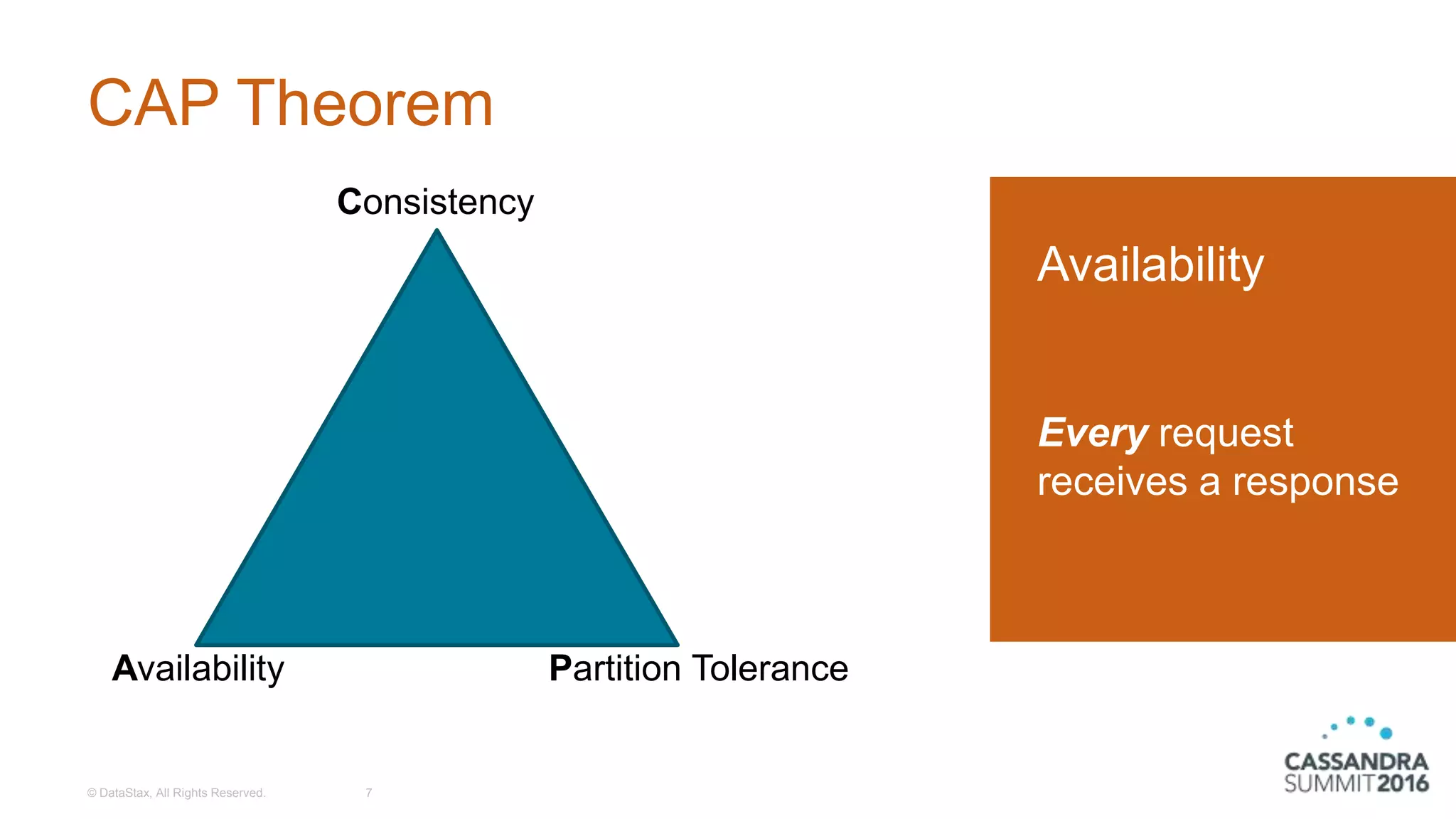
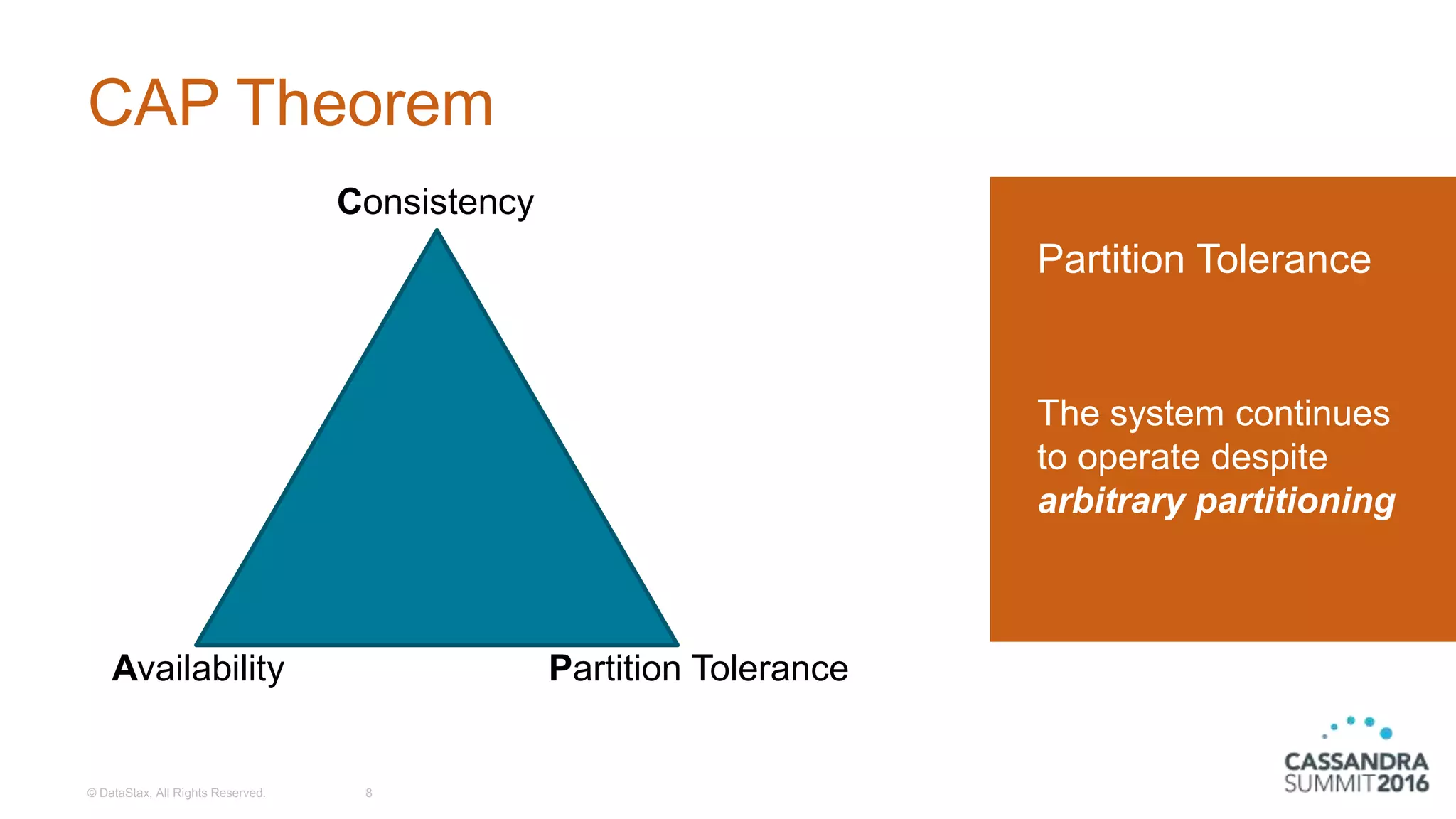
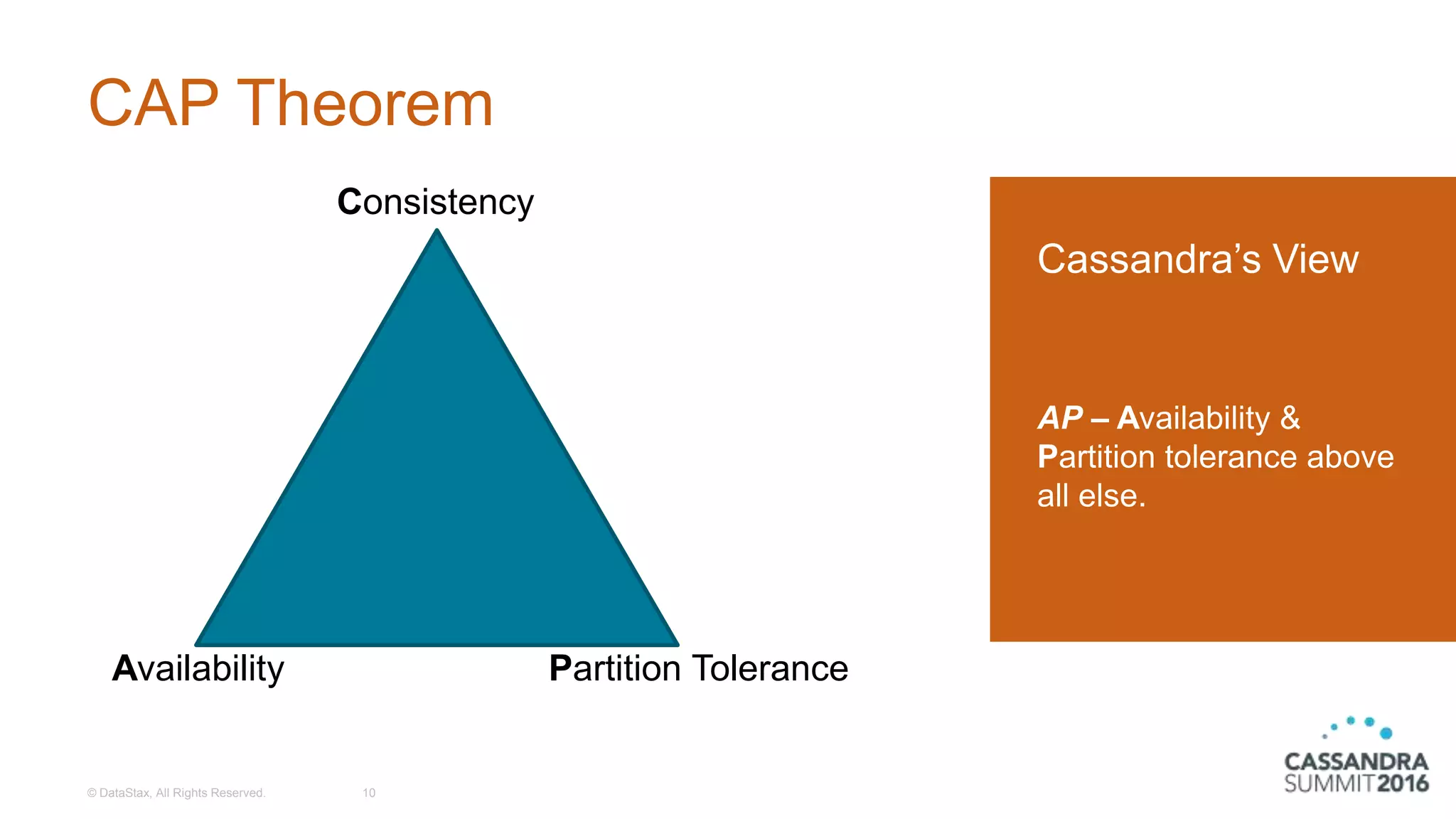
Introduction to the CAP Theorem illustrating Consistency, Availability, and Partition Tolerance.
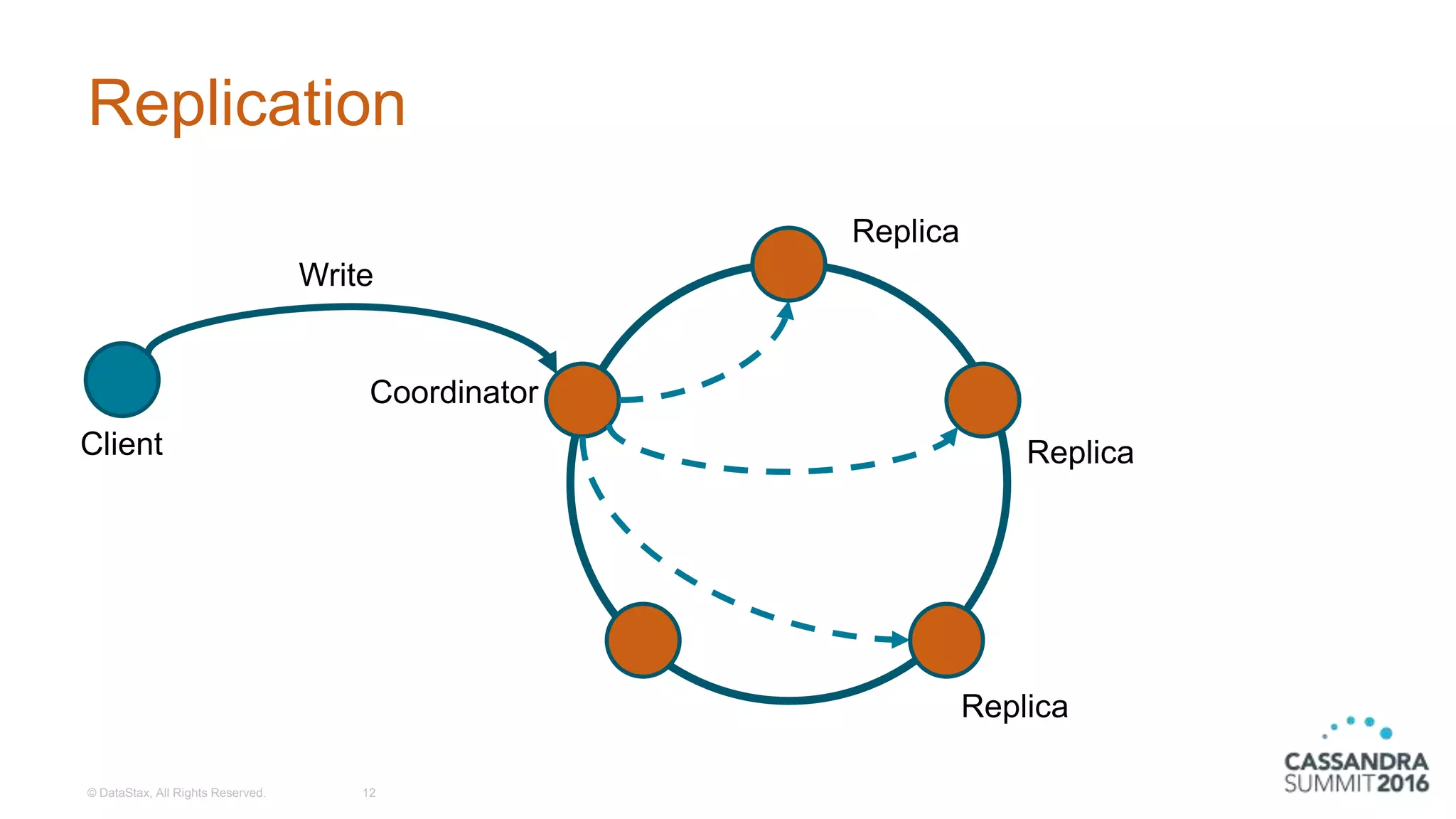
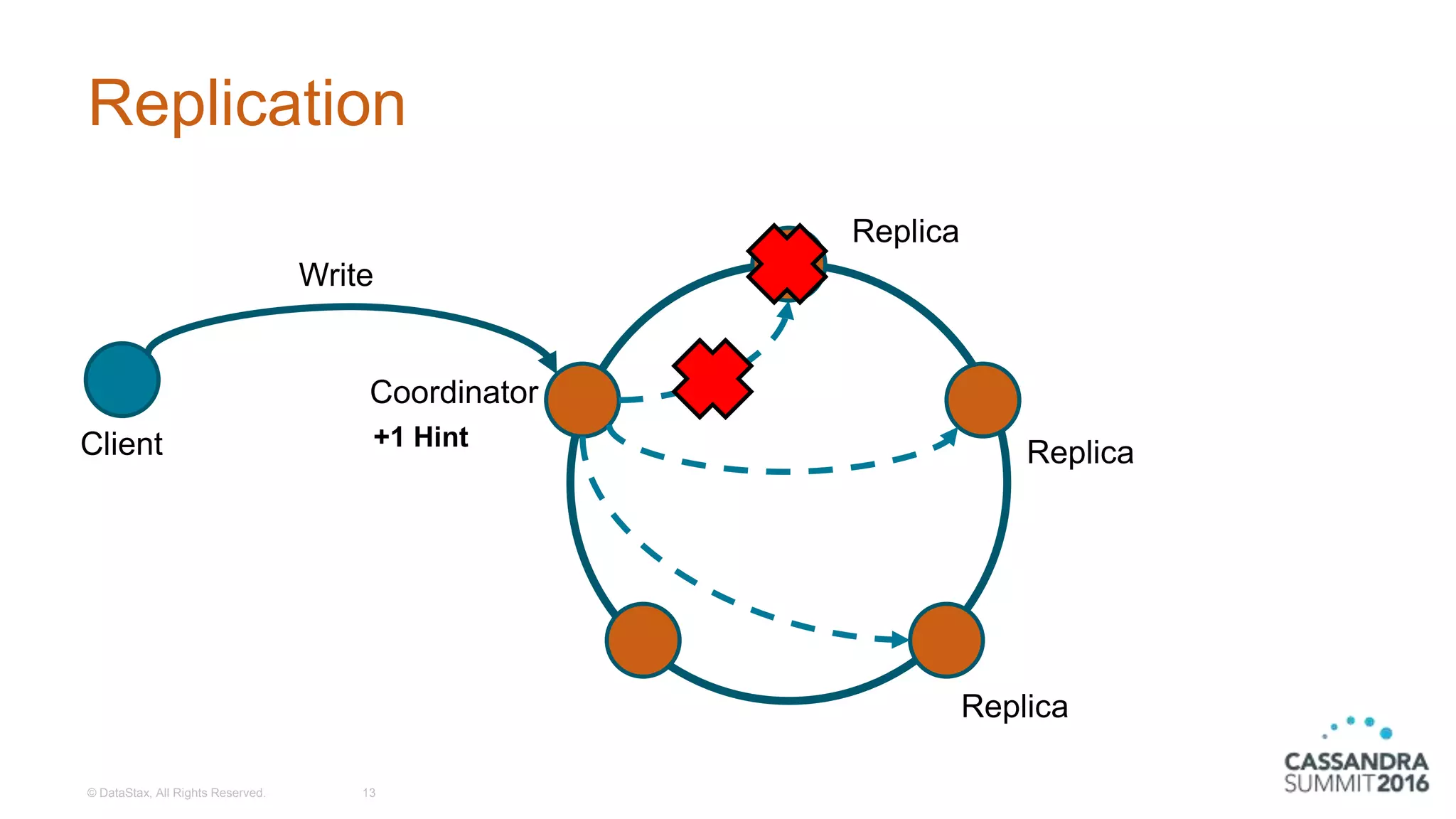
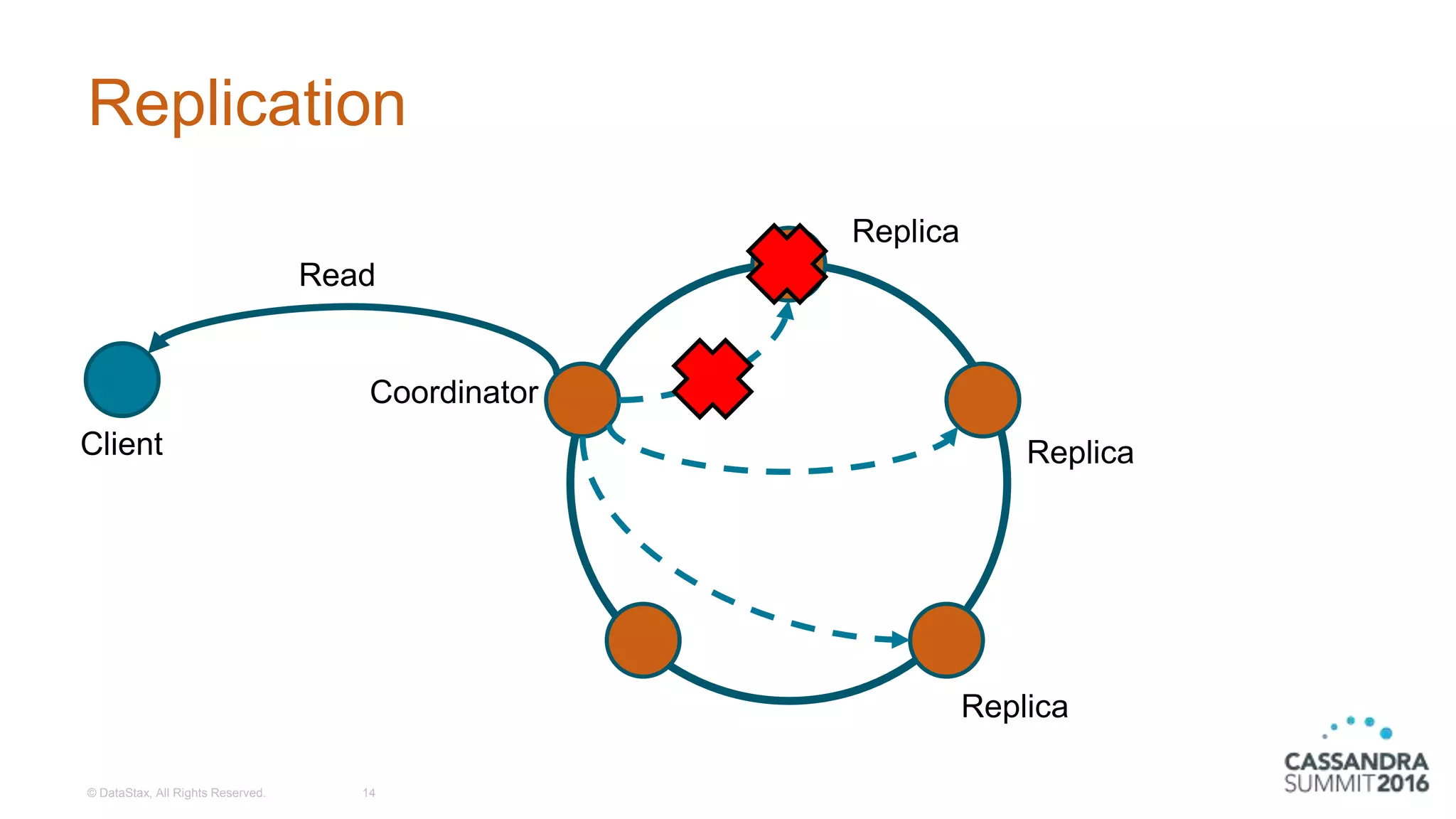
Overview of replication in Cassandra, including client interactions and write/read processes.
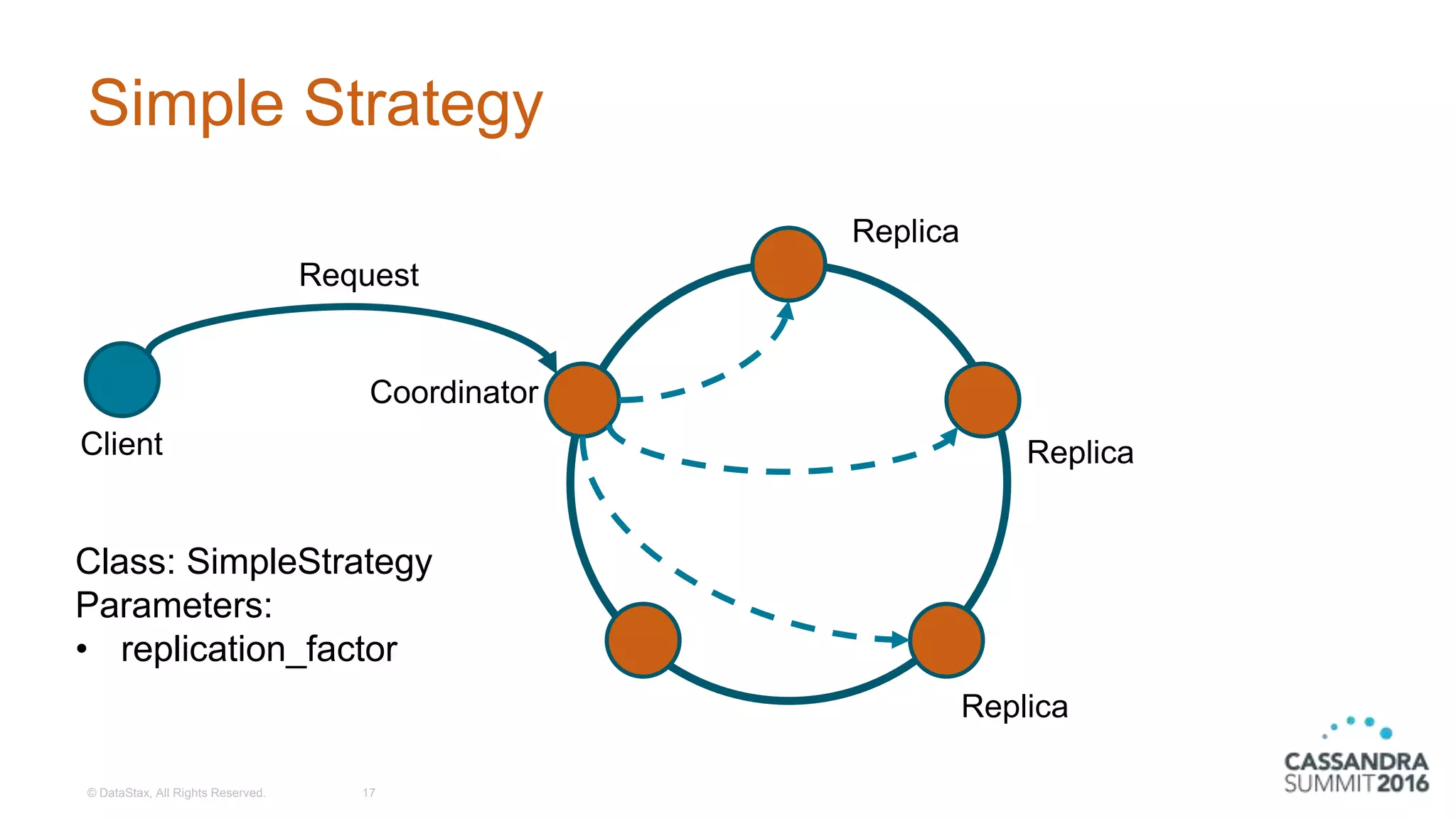
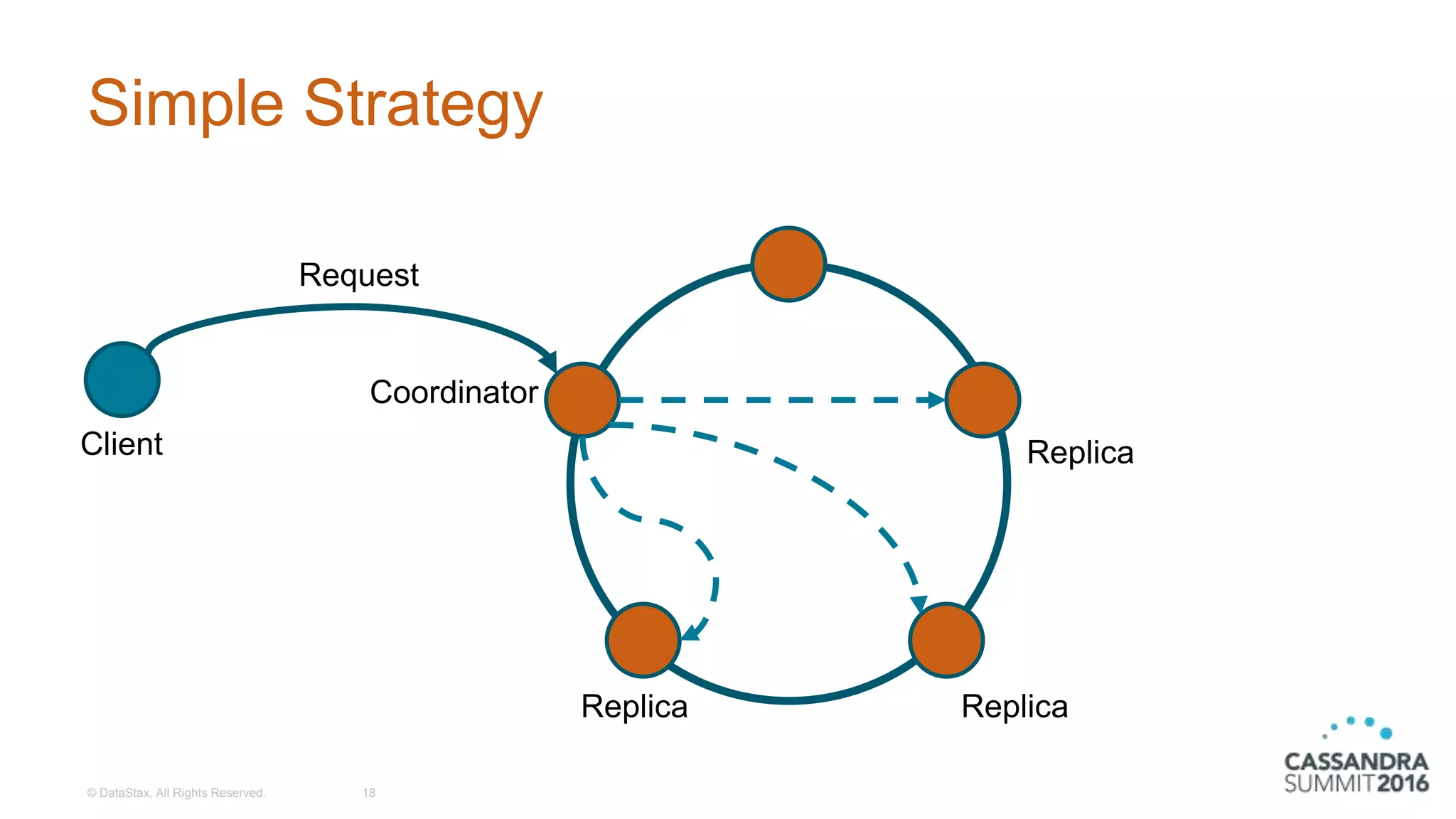
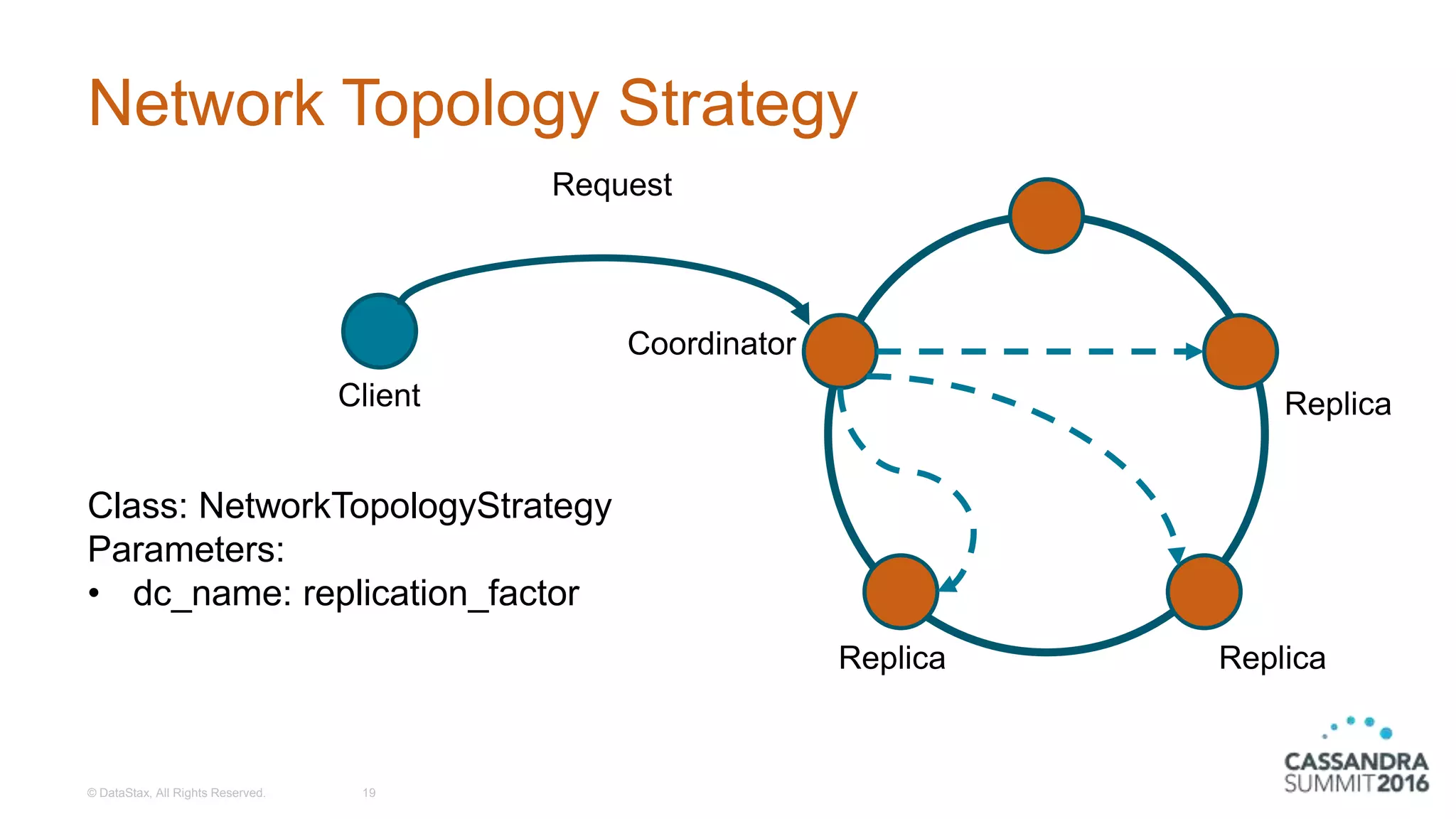
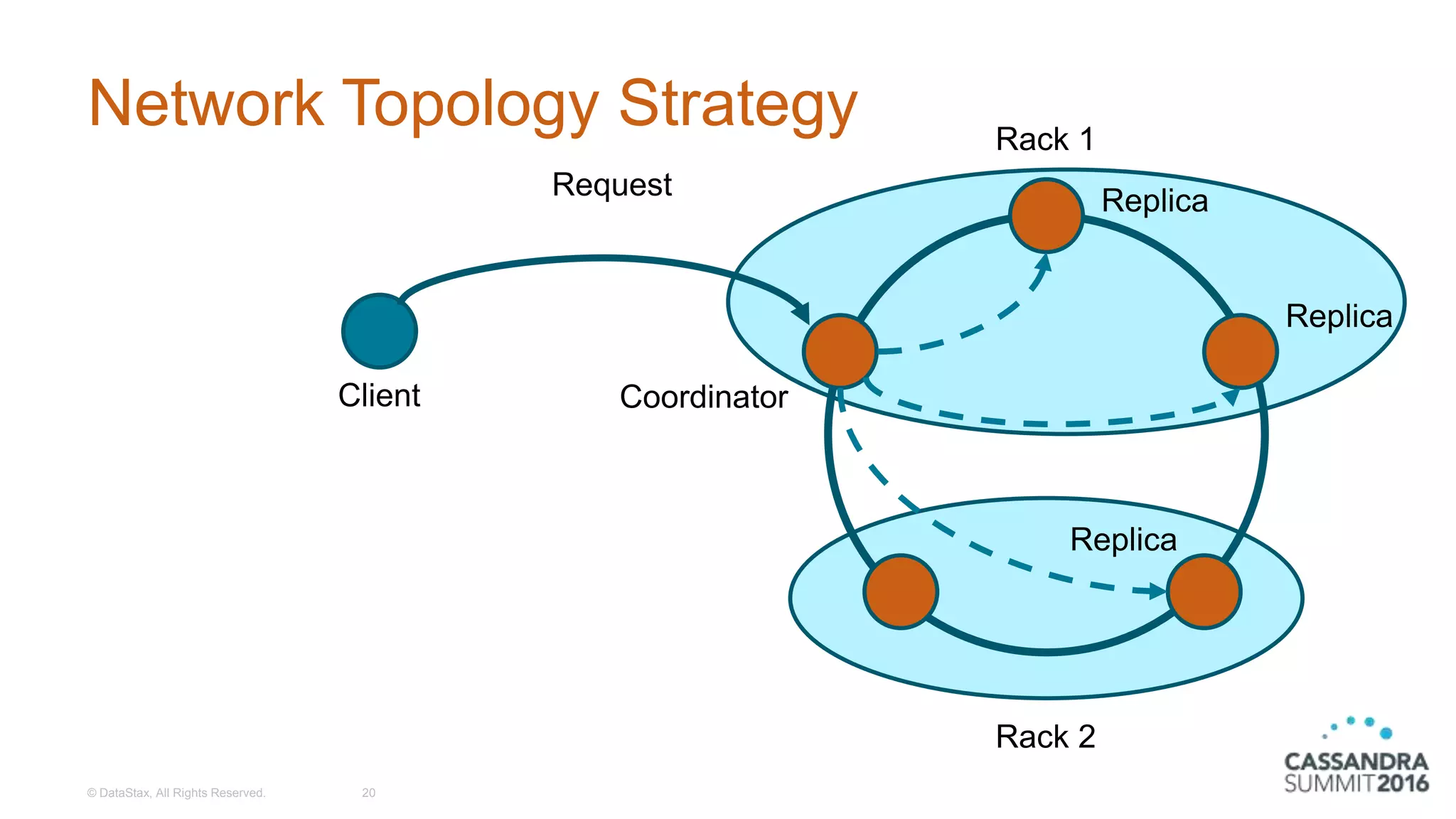
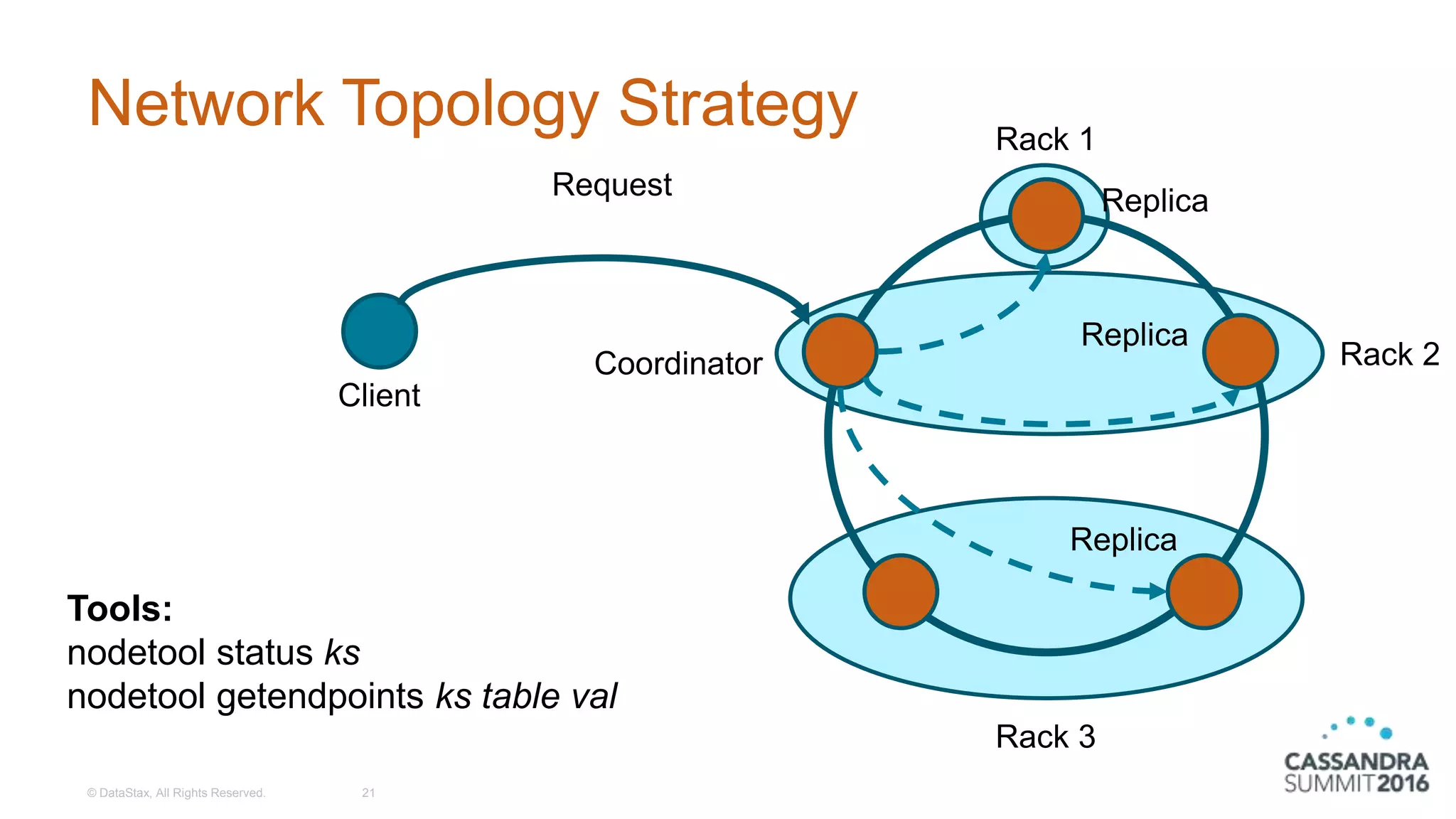
Explanation of the Simple and Network Topology replication strategies with configuration examples.
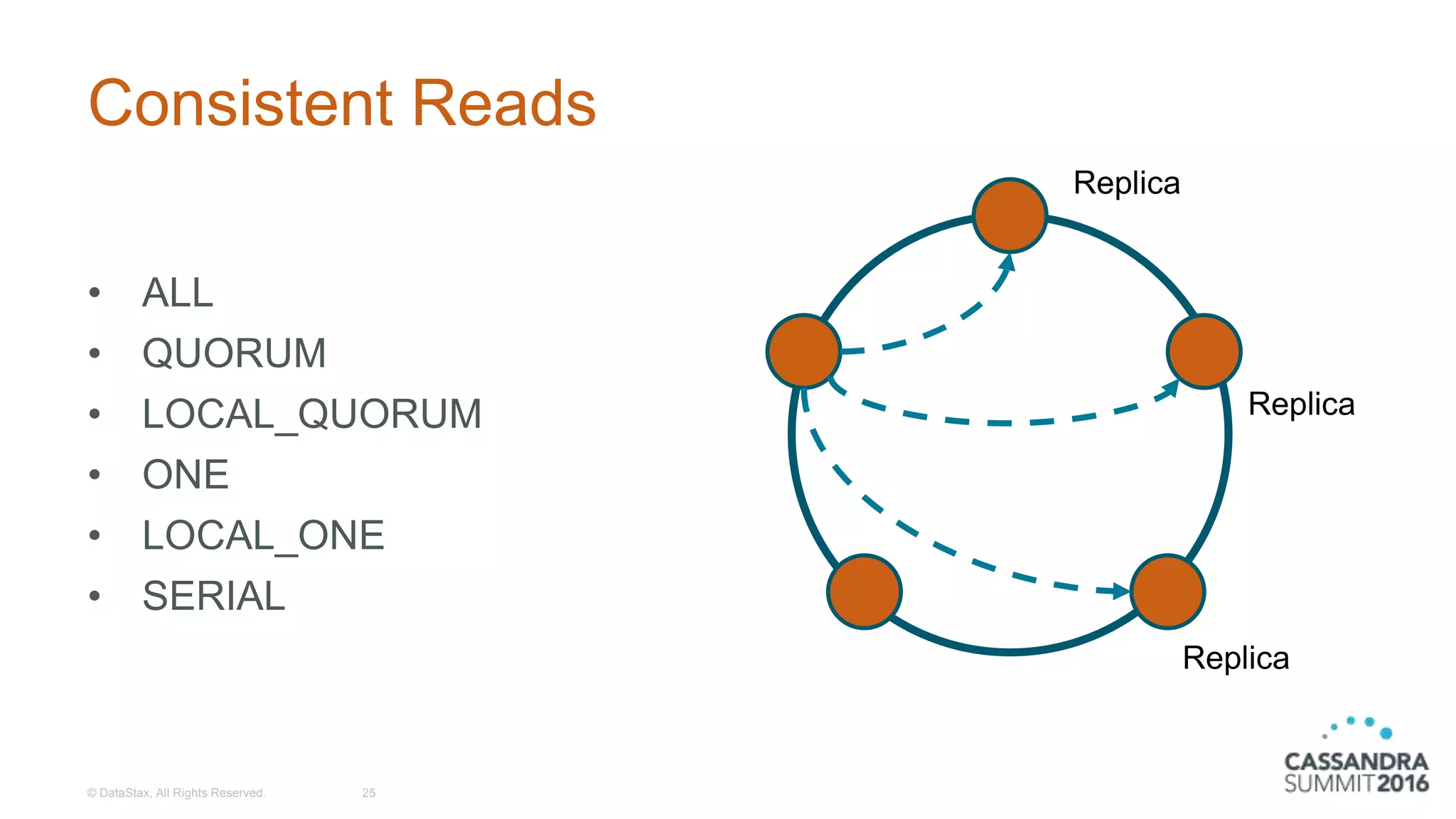
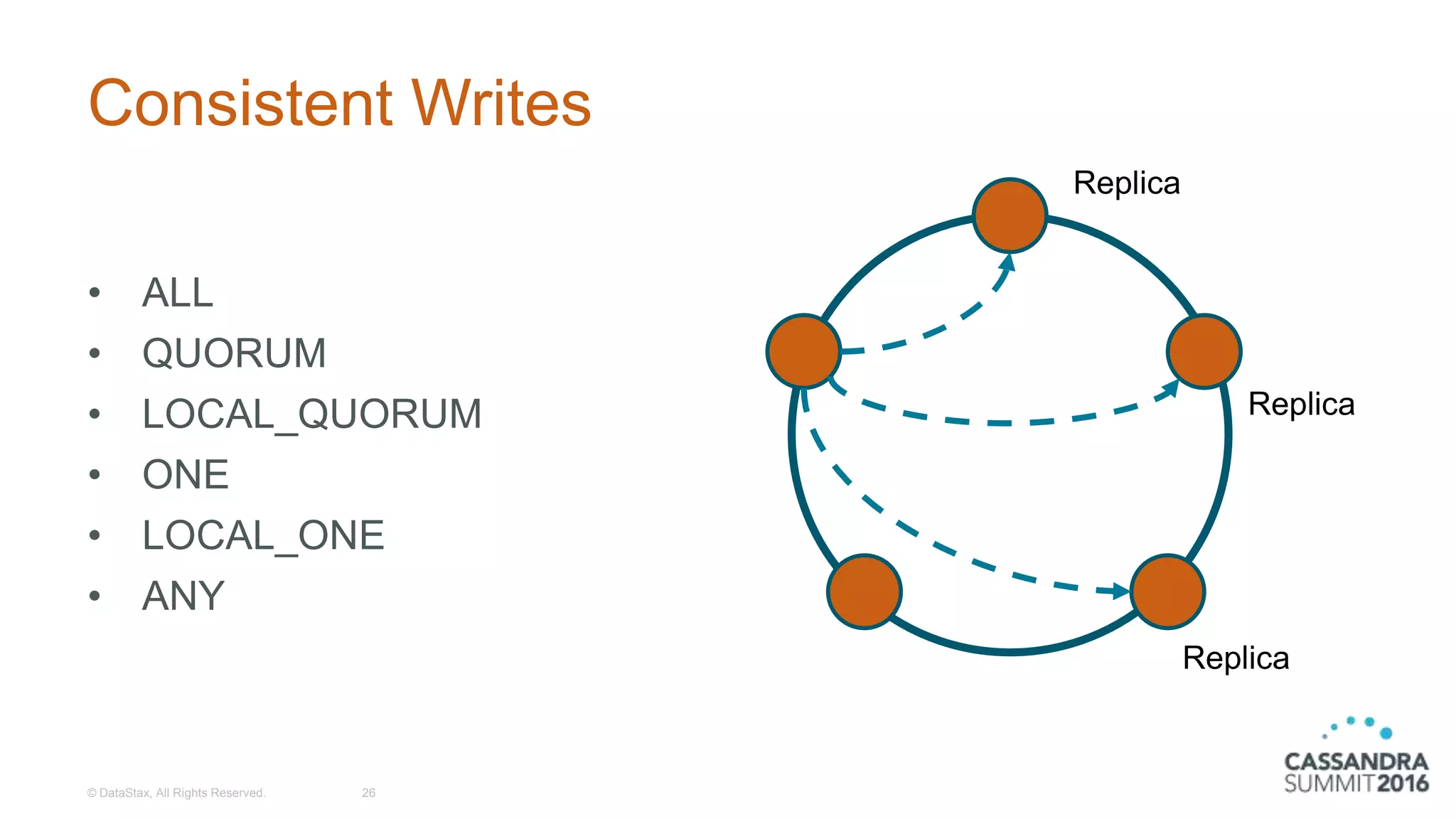
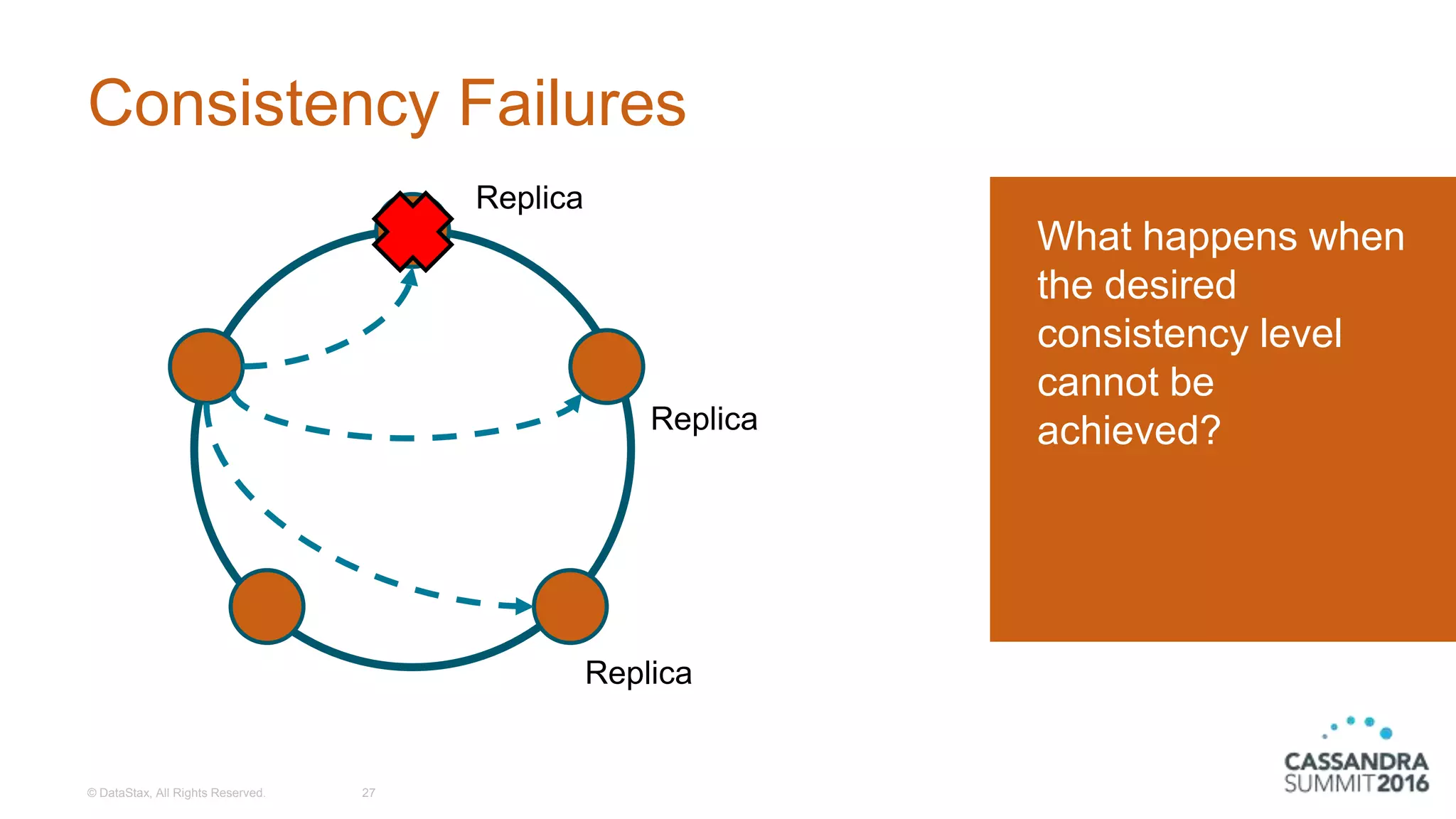
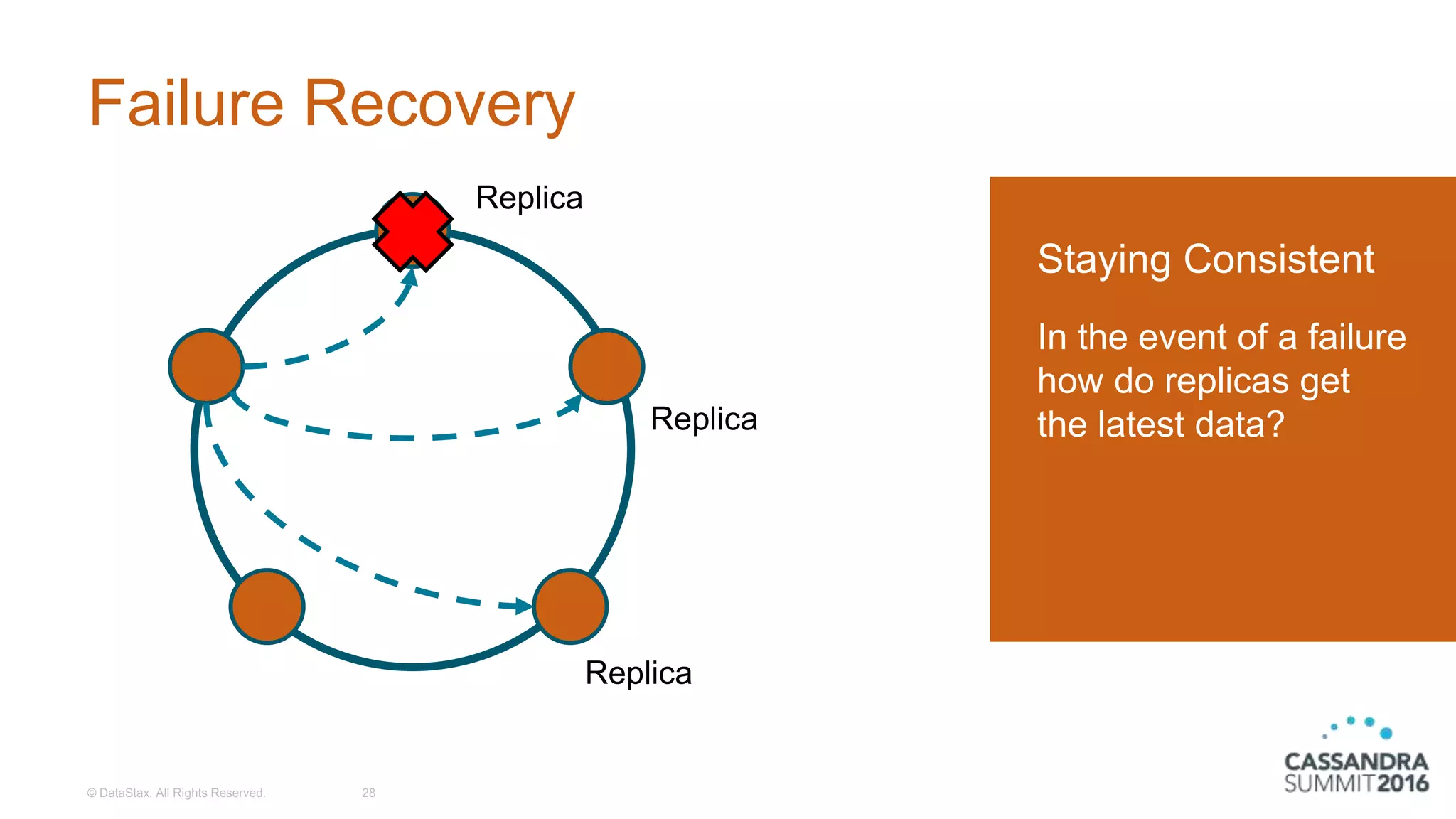
Discussion on tunable consistency, the various consistency levels, and handling consistency failures.
Wrap-up of the presentation and an invitation for questions from the audience.






























































































