



![9
GO TO EVENTS
{
"data":{
"id":"1c4da9f0-605e-4708-a8e7-0f2c97dff16e",
"type":"message_sent",
"attributes":{
"id":"e0abcd6c-c027-489f-95bf-24796e421e8b",
"conversation_id":"47596e76-0fb4-4155-9aeb-6a5ba14c9cef",
"product_id":"a0ef64a5-0a4d-48b8-9124-dd57371128f5",
"from_talker_id":"5mCK6K8VCc",
"to_talker_ids":[
"def4442e-6df5-4385-938a-8180ddfb6c5e"
],
"message_id":"e0abcd6c-c027-489f-95bf-24796e421e8b",
"type":"offer",
"message":"Is this item still available?",
"belongs_to_spam_conversation":false,
"sent_at":1509235499995
}
},
"meta":{
"created_at":1509235500012,
...
}](https://image.slidesharecdn.com/sparkmeetupfinal-180418193859/75/Letgo-Data-Platform-A-global-overview-9-2048.jpg)

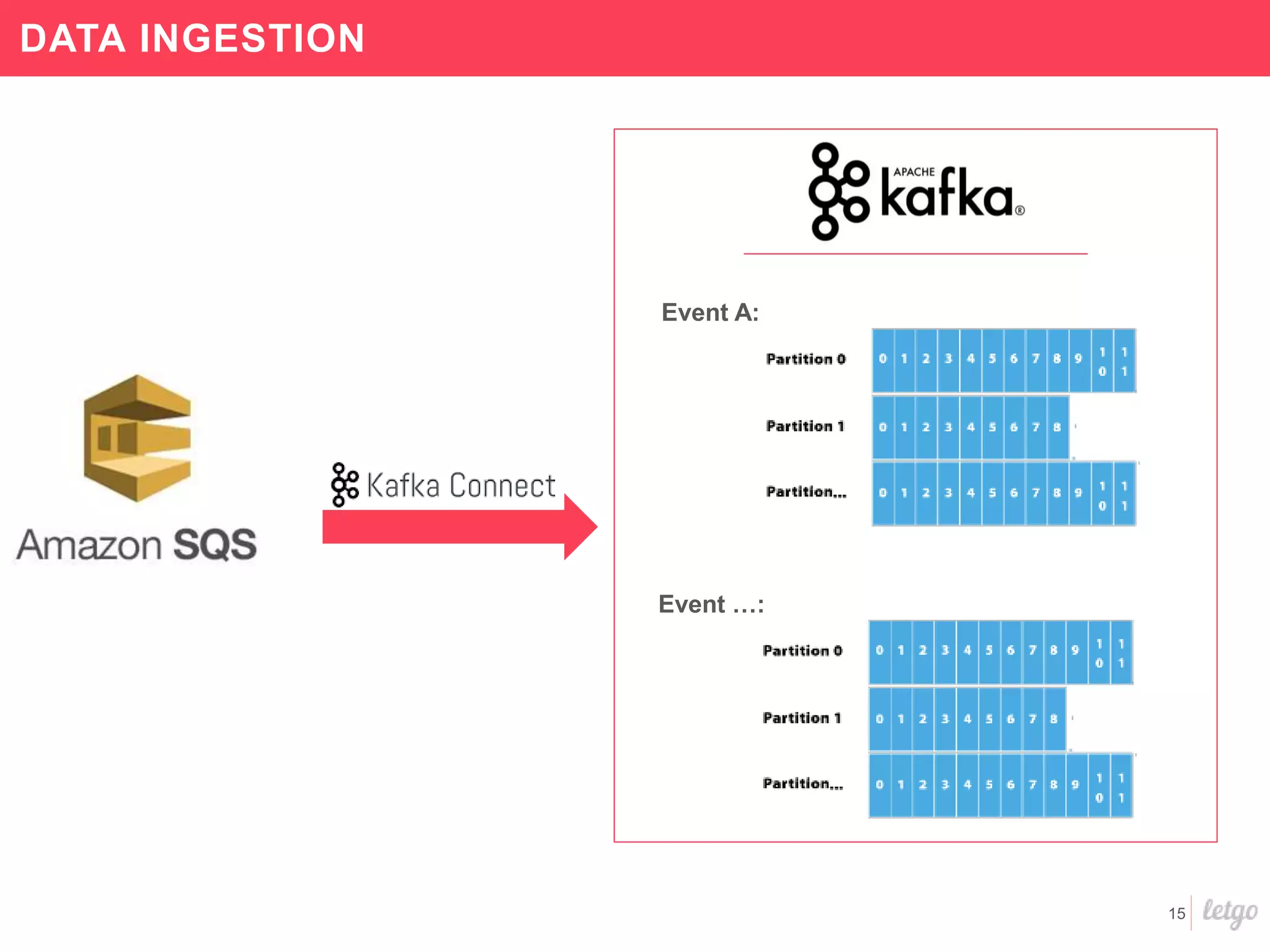
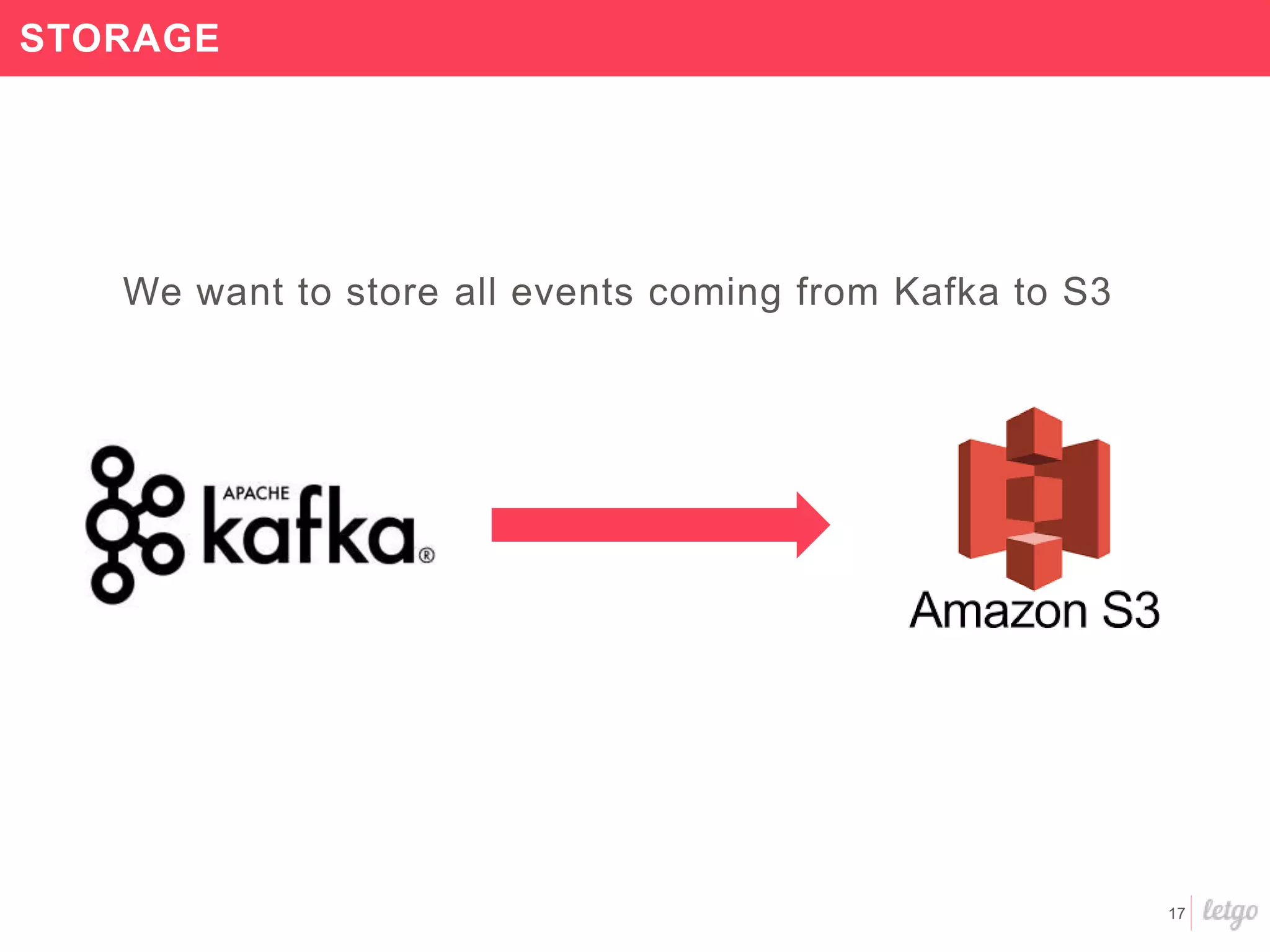





























![60
QUERYING DATA
CREATE TABLE …
USING [parquet,json,csv…]
CREATE TABLE …
STORED AS…
VS](https://image.slidesharecdn.com/sparkmeetupfinal-180418193859/75/Letgo-Data-Platform-A-global-overview-60-2048.jpg)
![61
QUERYING DATA
CREATE TABLE …
STORED AS…
VS 70%
Higher performance!
CREATE TABLE …
USING [parquet,json,csv…]](https://image.slidesharecdn.com/sparkmeetupfinal-180418193859/75/Letgo-Data-Platform-A-global-overview-61-2048.jpg)























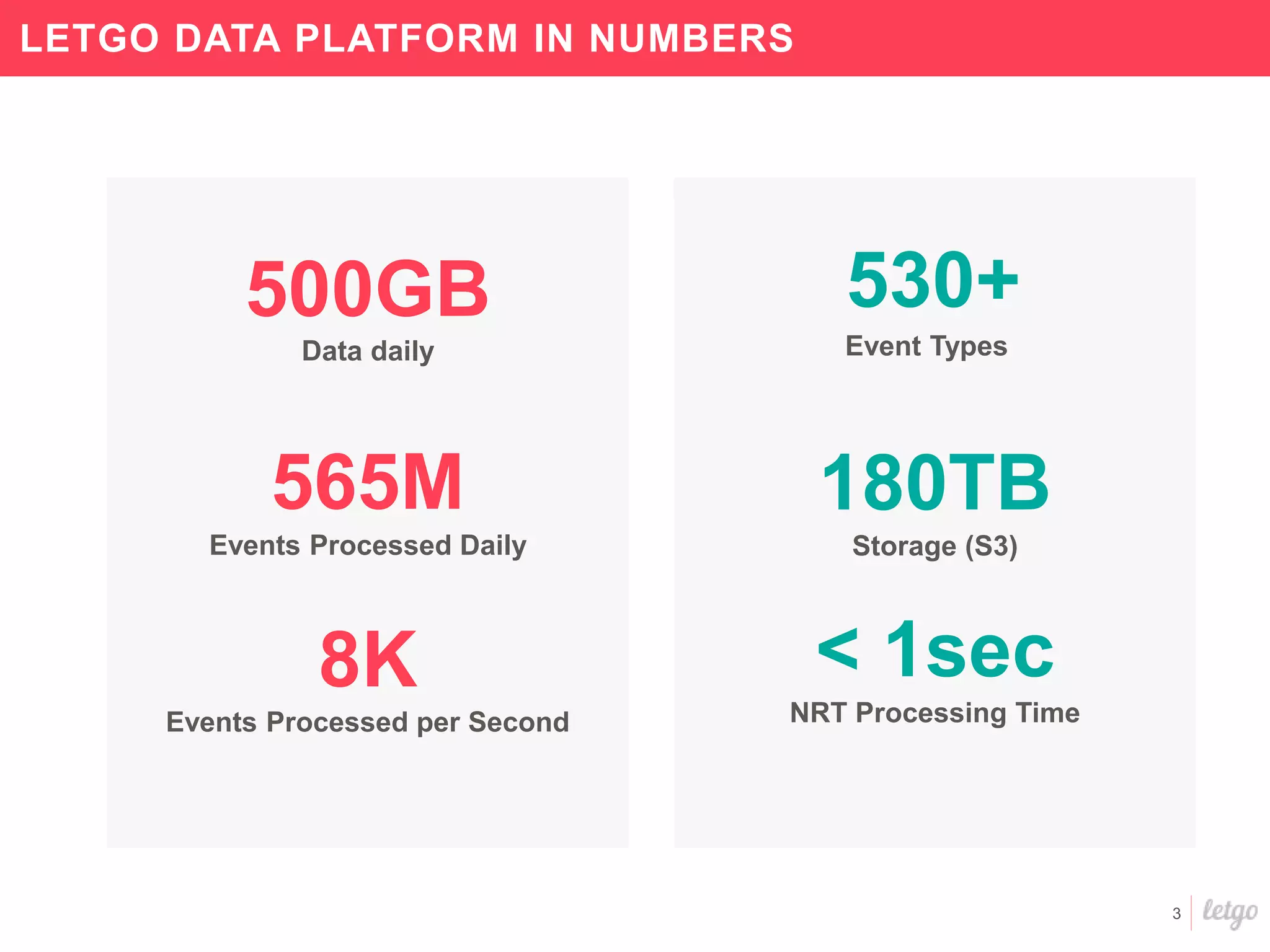
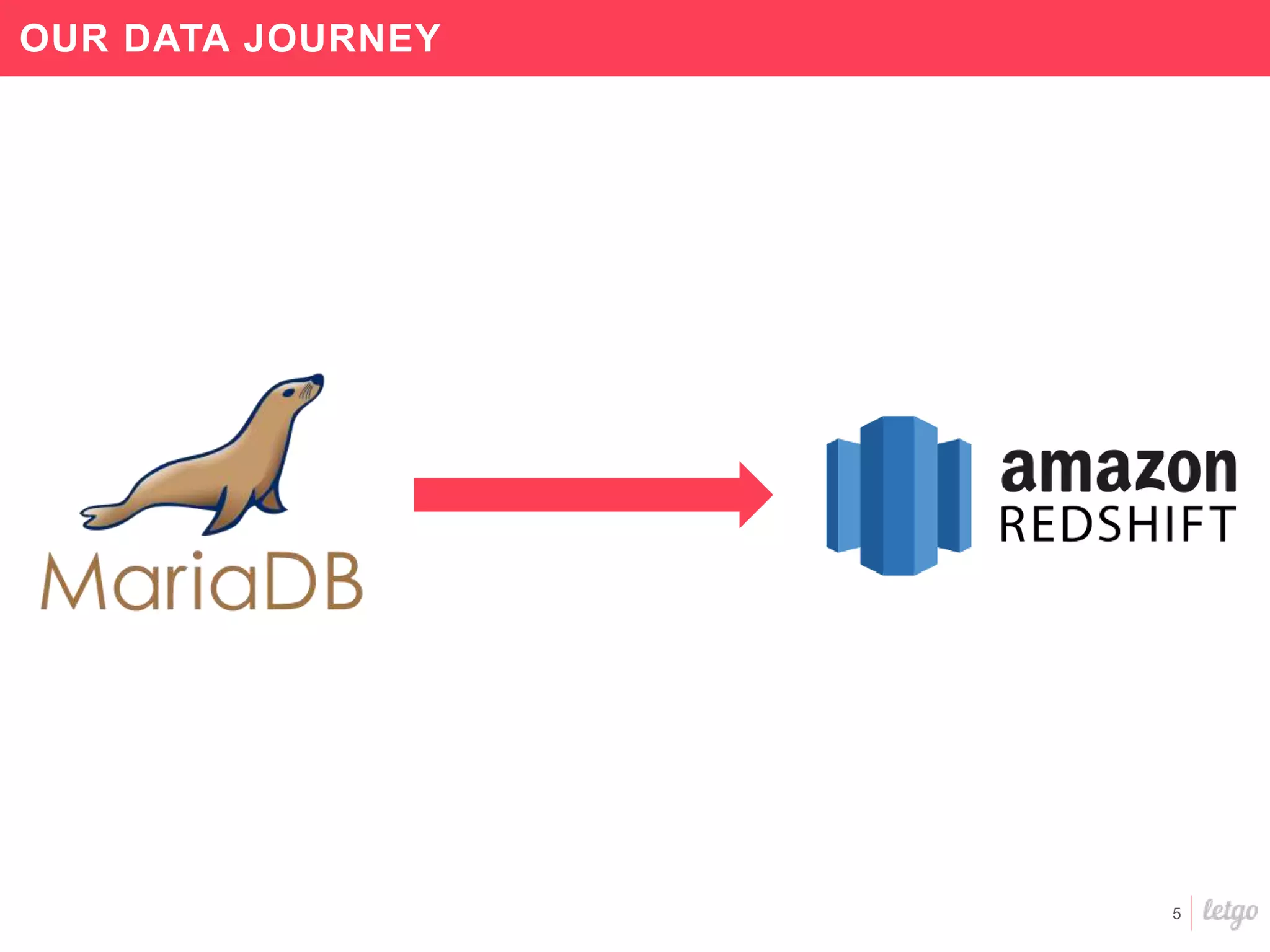
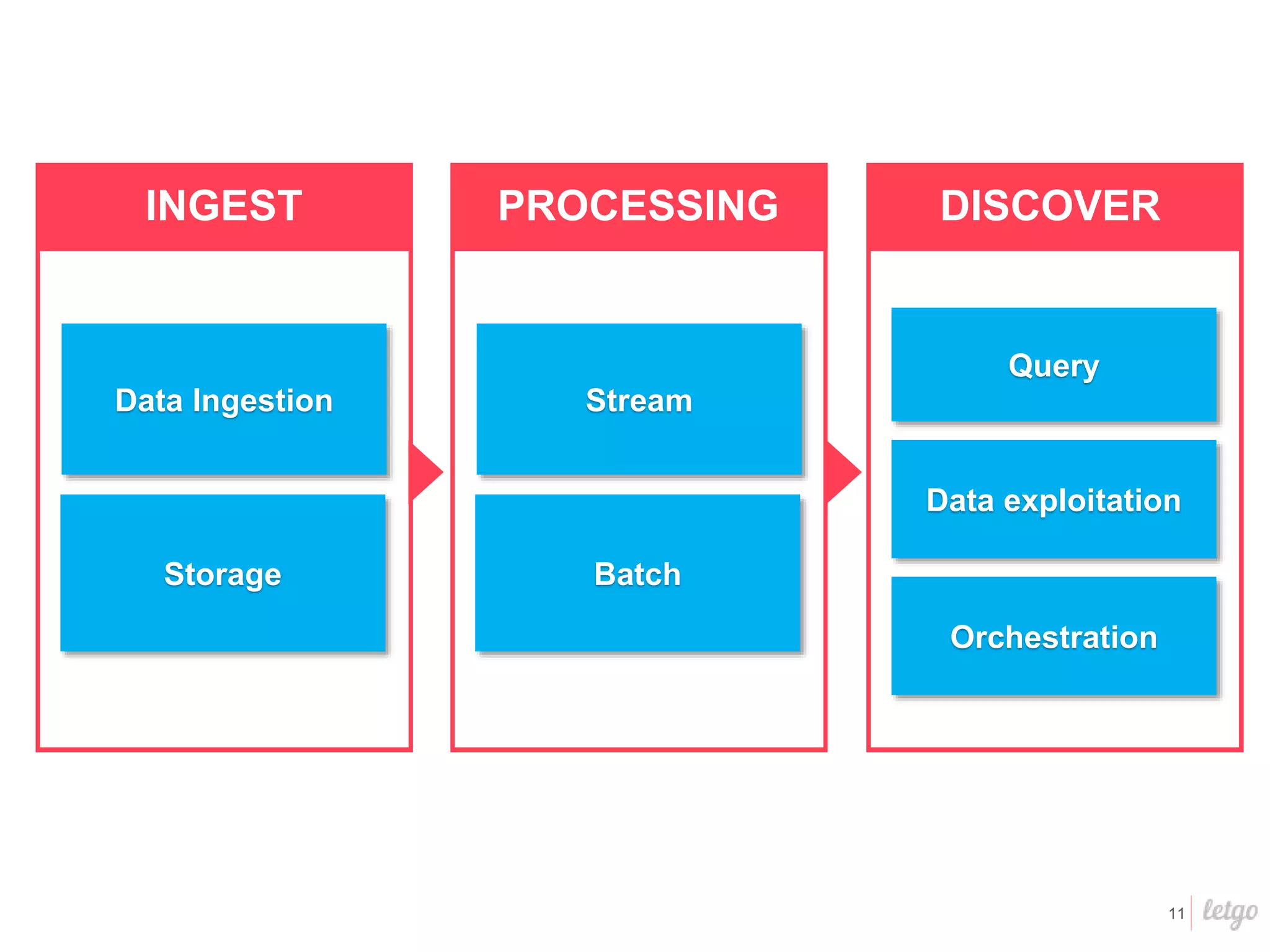
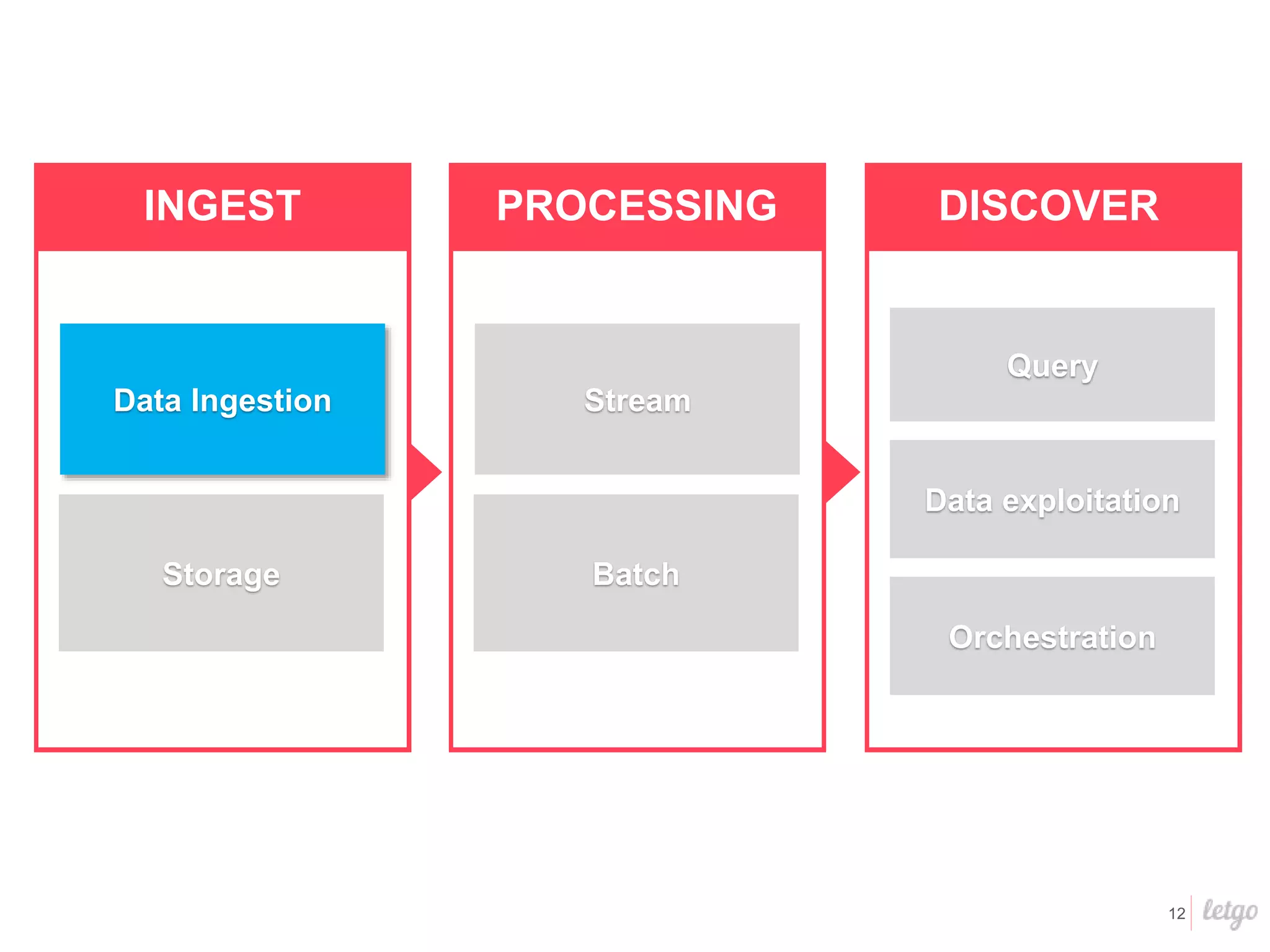
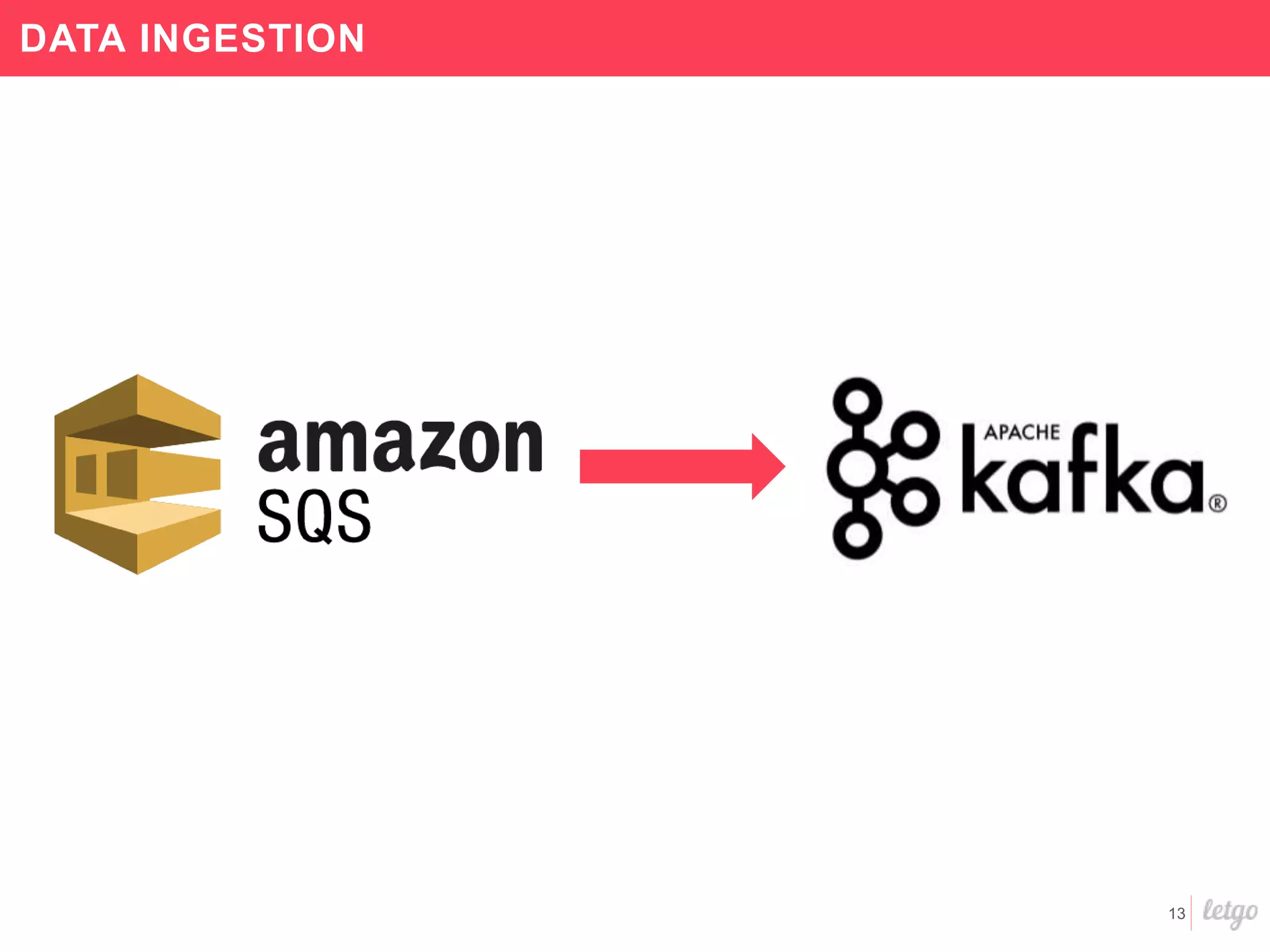
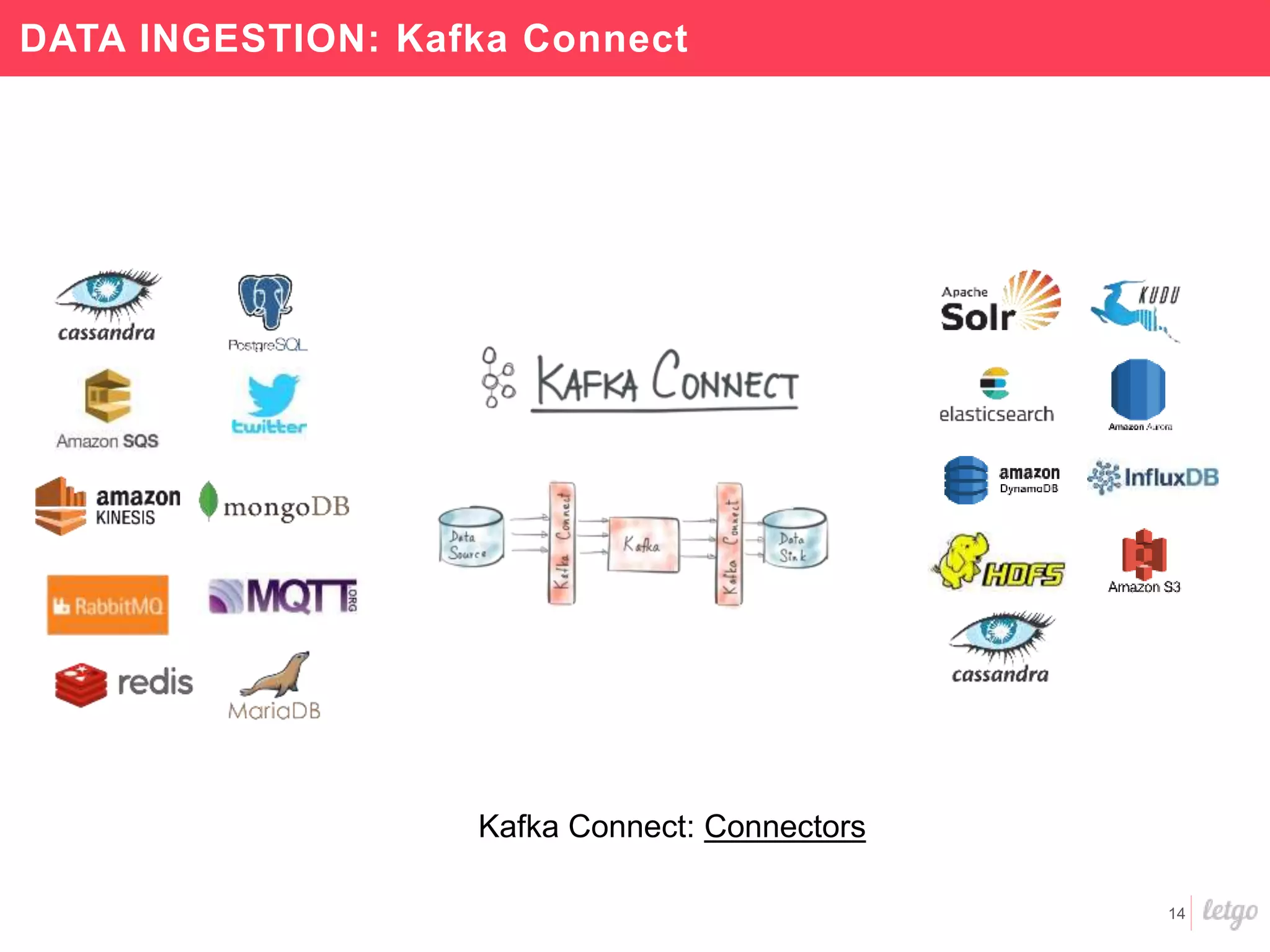
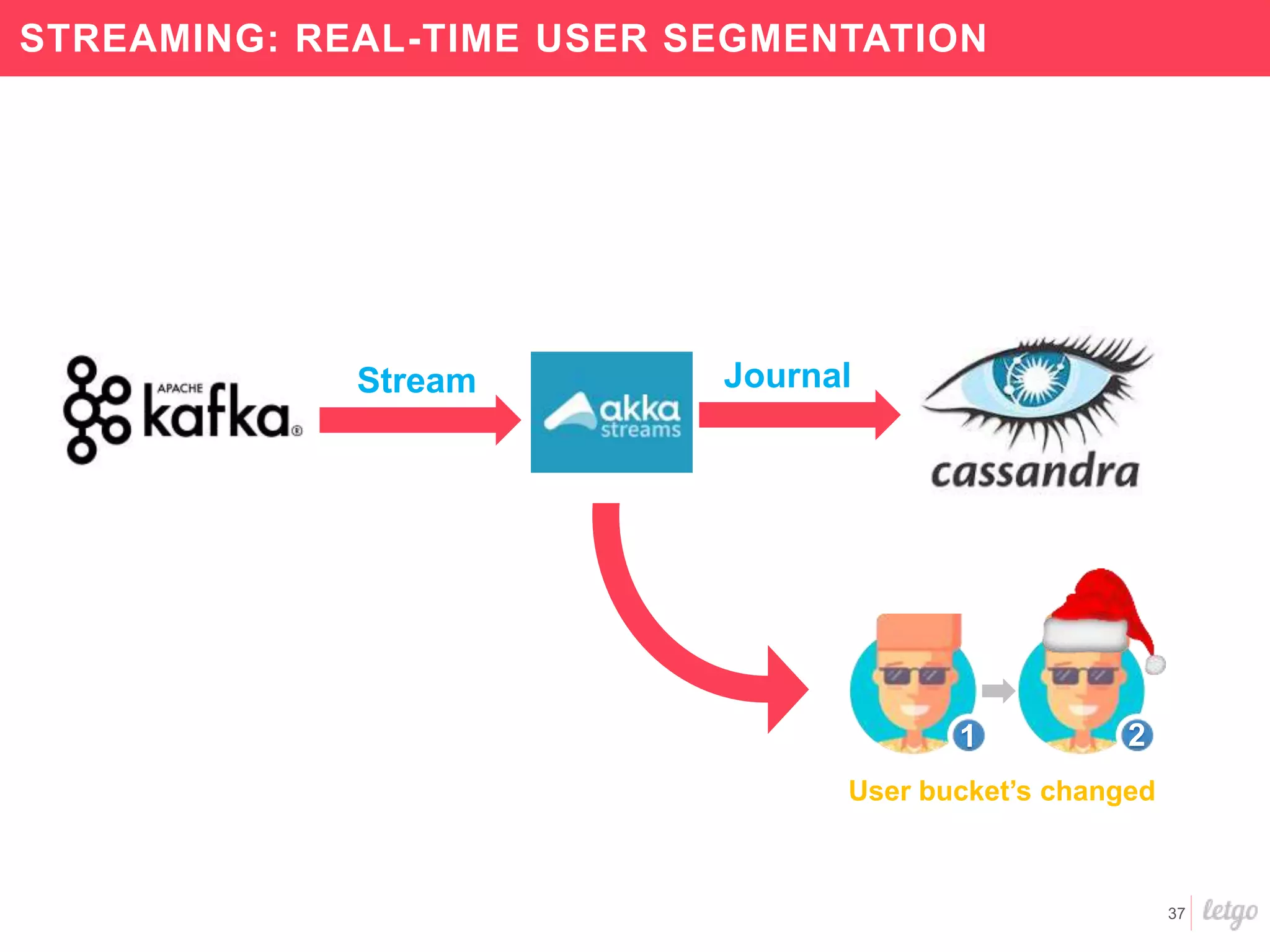
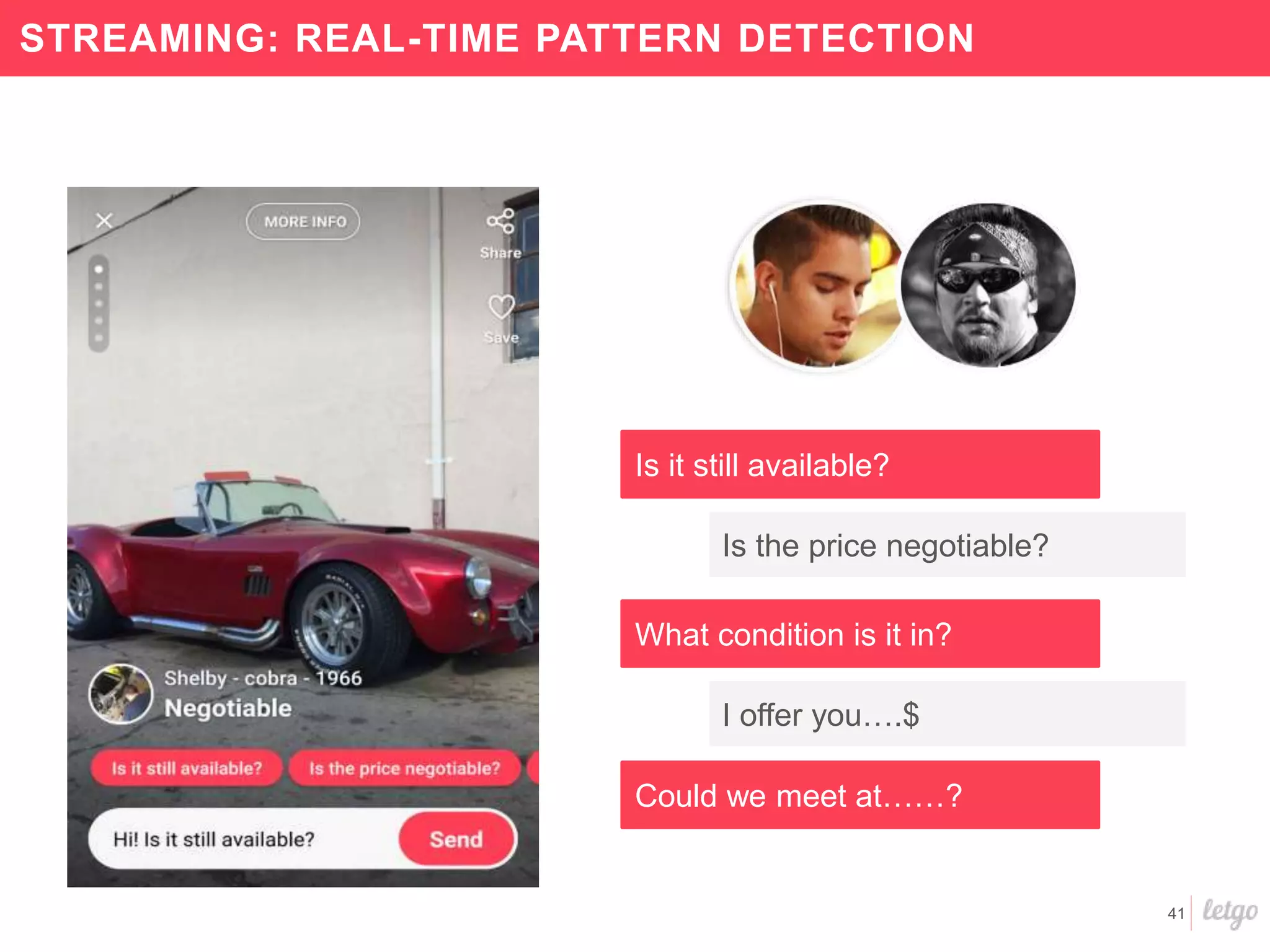
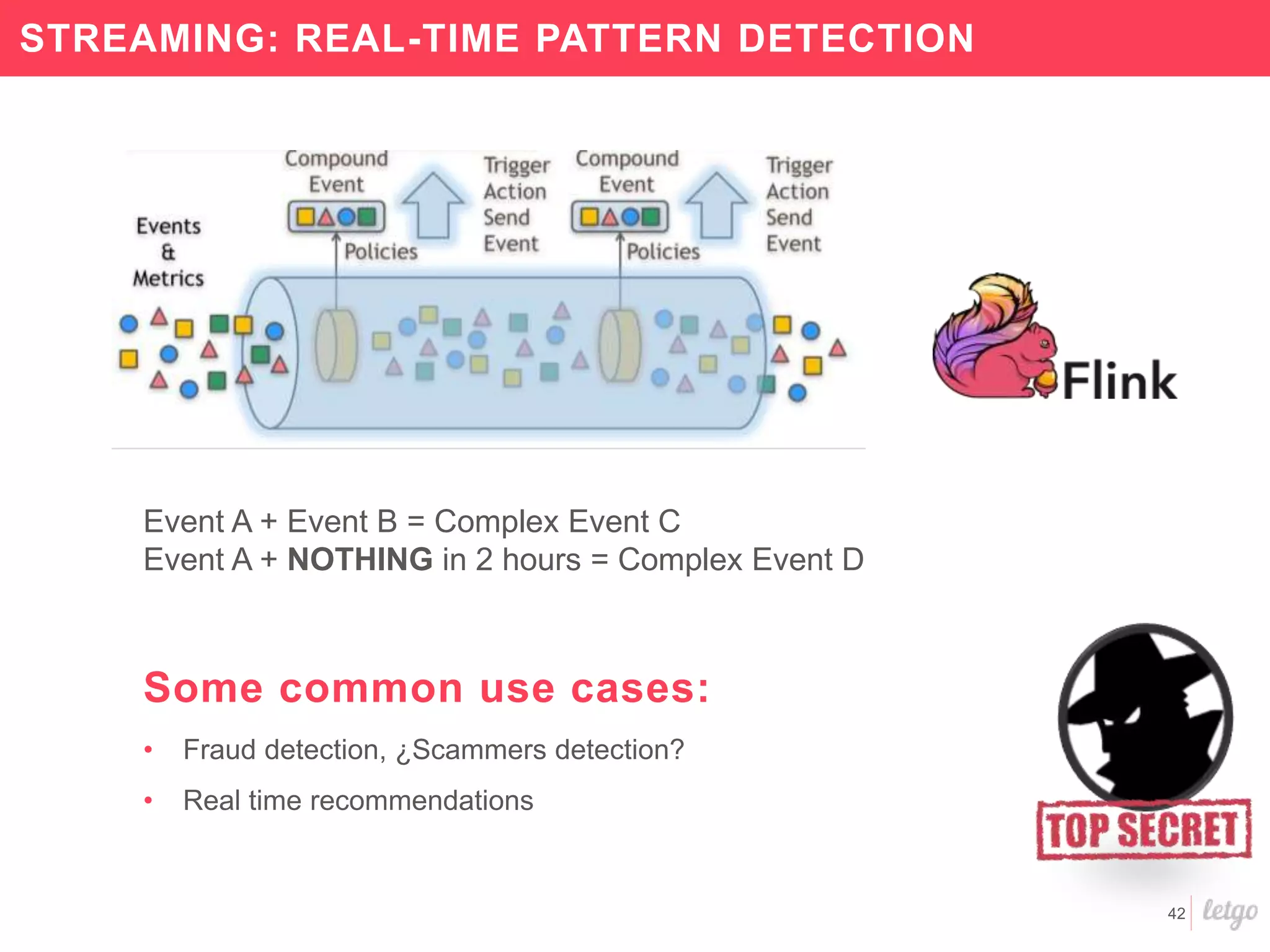
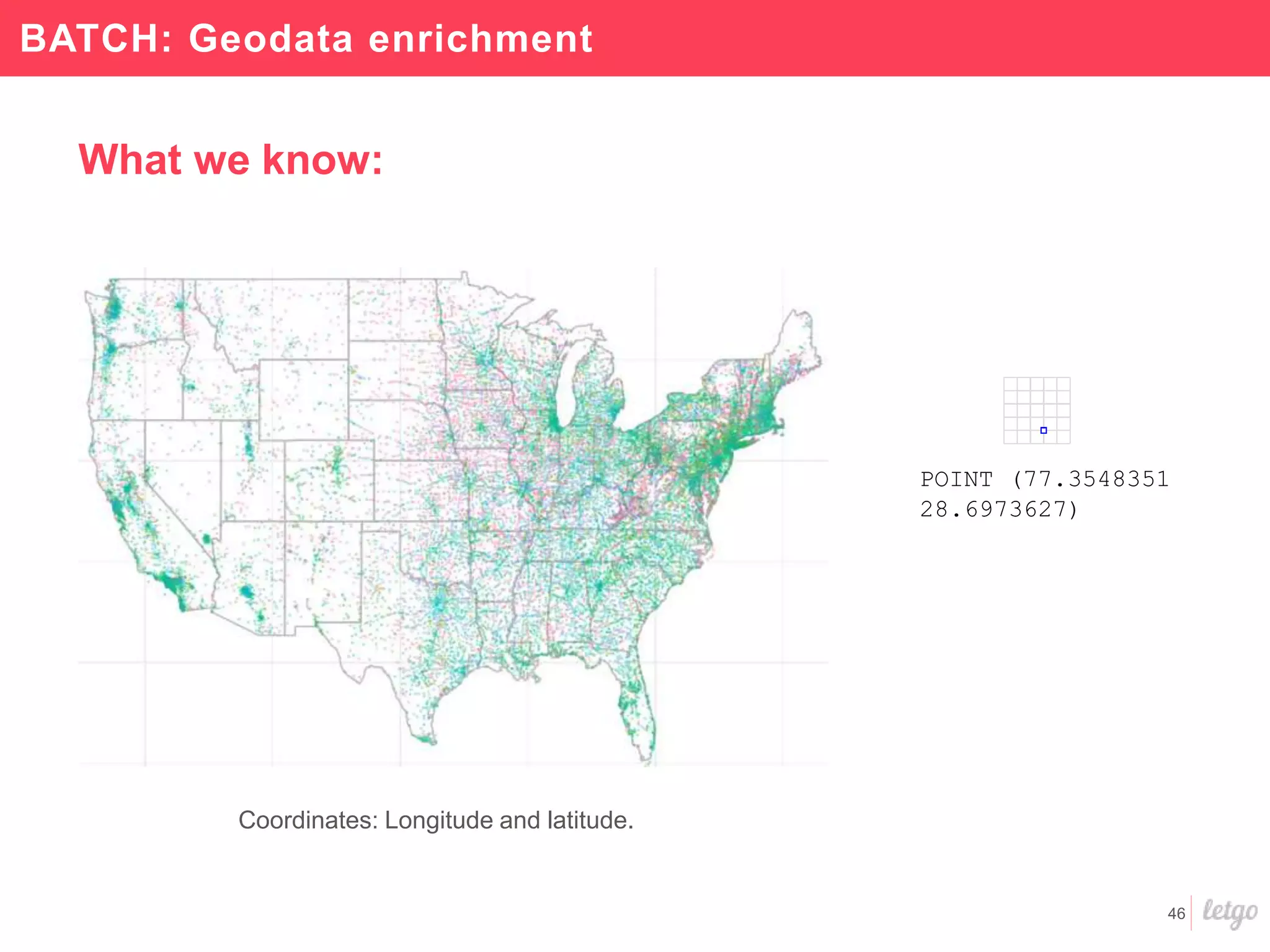
This document provides a summary of Letgo's data platform. It discusses how Letgo ingests 500GB of data daily from various event types and processes over 530 million events daily with near real-time processing. It describes Letgo's data journey in moving to an event-driven architecture and storing data in S3. Key components of Letgo's data platform are discussed like stream processing for real-time user segmentation, batch processing for geo data enrichment, querying data using Spark SQL, and data exploitation tools. The document also provides some tips for orchestrating jobs and monitoring metrics.











































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)



