Downloaded 180 times








![Comparison: RDBMS vs. Cassandra
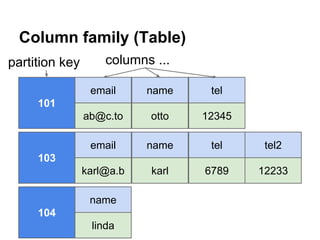
RDBMS Data Design
Cassandra Data Design
Users Table
Users Table
user_id
name
email
user_id
name
email
101
otto
o@t.to
101
otto
o@t.to
Tweets Table
tweet_id author_id
9990
101
Followers Table
follows_
id
id
104
4321
Tweets Table
body
Hello!
tweet_id author_id
9990
101
Follows Table
followed
_id
101
name
body
otto
Hello!
Followed Table
user_id
follows_list
id
followed_list
104
[101,117]
101
[104,109]](https://image.slidesharecdn.com/cassandralesson-datamodelandcql3-131123012511-phpapp02/85/Apache-Cassandra-Lesson-Data-Modelling-and-CQL3-11-320.jpg)


















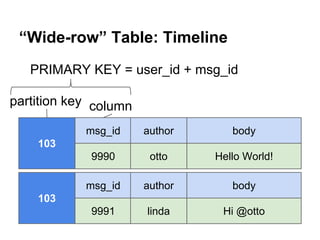
![Collections - List
2. Now create a Table "followers" with a list of followers.
cqlsh:twotter> CREATE TABLE followers (
user_id int PRIMARY KEY,
followers list<text>);
cqlsh:twotter> INSERT INTO followers (
user_id, followers)
VALUES (101, ['willi','heinz']);
cqlsh:twotter> SELECT * FROM followers;
user_id | followers
---------+-------------------101
| ['willi', 'heinz']](https://image.slidesharecdn.com/cassandralesson-datamodelandcql3-131123012511-phpapp02/85/Apache-Cassandra-Lesson-Data-Modelling-and-CQL3-34-320.jpg)











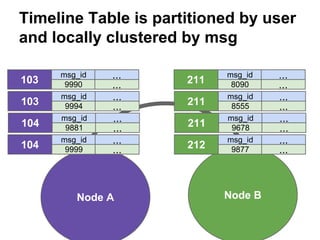
![Solution: sstable2json
$ nodetool flush twotter users
$ sstable2json
/var/lib/cassandra/data/twotter/users/twotte
r-users-jb-1-Data.db > twotter-users.json
$ cat twotter-users.json
[{"key": "00000069","columns": [["","",
1384963716697000], ["email","g@rd.de",
1384963716697000], ["name","gerd",
1384963716697000]]},
{"key": "00000068","columns": [["","",
1384963716685000], ...](https://image.slidesharecdn.com/cassandralesson-datamodelandcql3-131123012511-phpapp02/85/Apache-Cassandra-Lesson-Data-Modelling-and-CQL3-46-320.jpg)





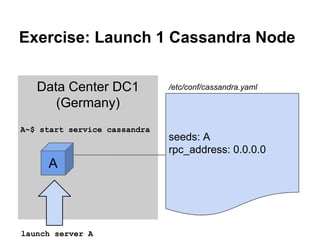
![Exercise: Lightweight Transactions
● Perform a failing CAS e-mail reset:
cqlsh:twotter>
UPDATE users
SET email = 'franz@ABC.de'
WHERE id = 110
IF email = 'fr@nz.de';
[applied] | email
-----------+------------False
| franz@gmail.com](https://image.slidesharecdn.com/cassandralesson-datamodelandcql3-131123012511-phpapp02/85/Apache-Cassandra-Lesson-Data-Modelling-and-CQL3-52-320.jpg)




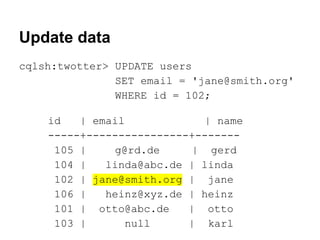
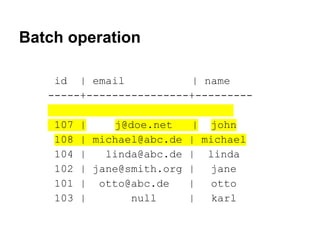
The document is a guide to data modeling and queries using CQL3 with Cassandra, detailing key concepts such as keyspaces, column families, and various table structures. It covers creating tables, inserting and updating data, and advanced features like collections, consistency levels, and lightweight transactions. The content also includes exercises for practical application and comparisons between RDBMS and Cassandra data design.













































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









