Download as PDF, PPTX











![How counter works
■ Create dedicated node-counter-id (shard) for each node [RF=2]
Node
counter id
Shard’s
logical clock
Shard’s
value
A_1 0 0
B_1 1 1
NODE A
Node
counter id
Shard’s
logical clock
Shard’s
value
A_1 0 0
B_1 1 1
NODE B](https://image.slidesharecdn.com/robertczupiol-scyllasummit2022-220125182259/75/Scylla-Summit-2022-How-to-Migrate-a-Counter-Table-for-68-Billion-Records-12-2048.jpg)
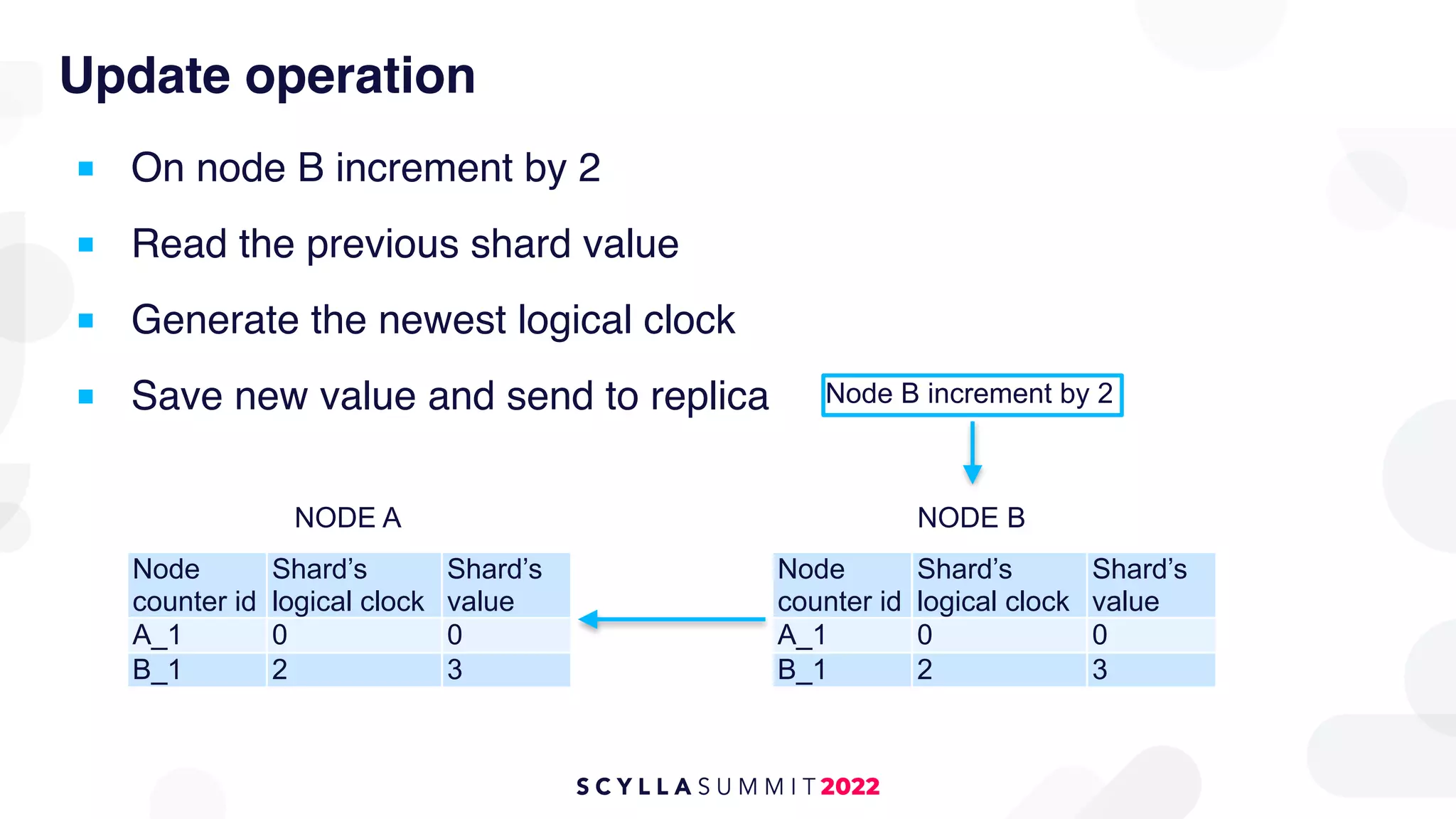
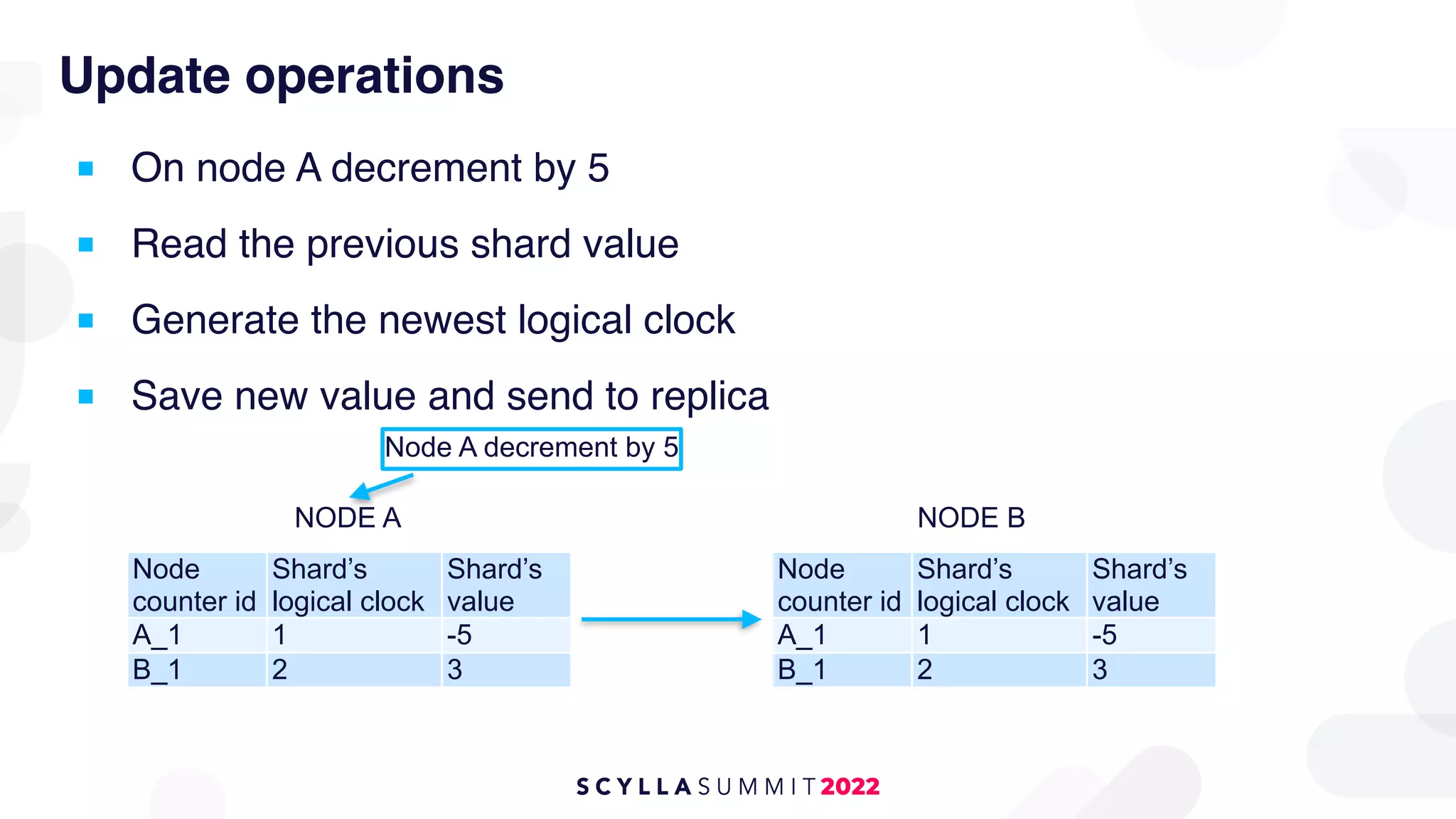
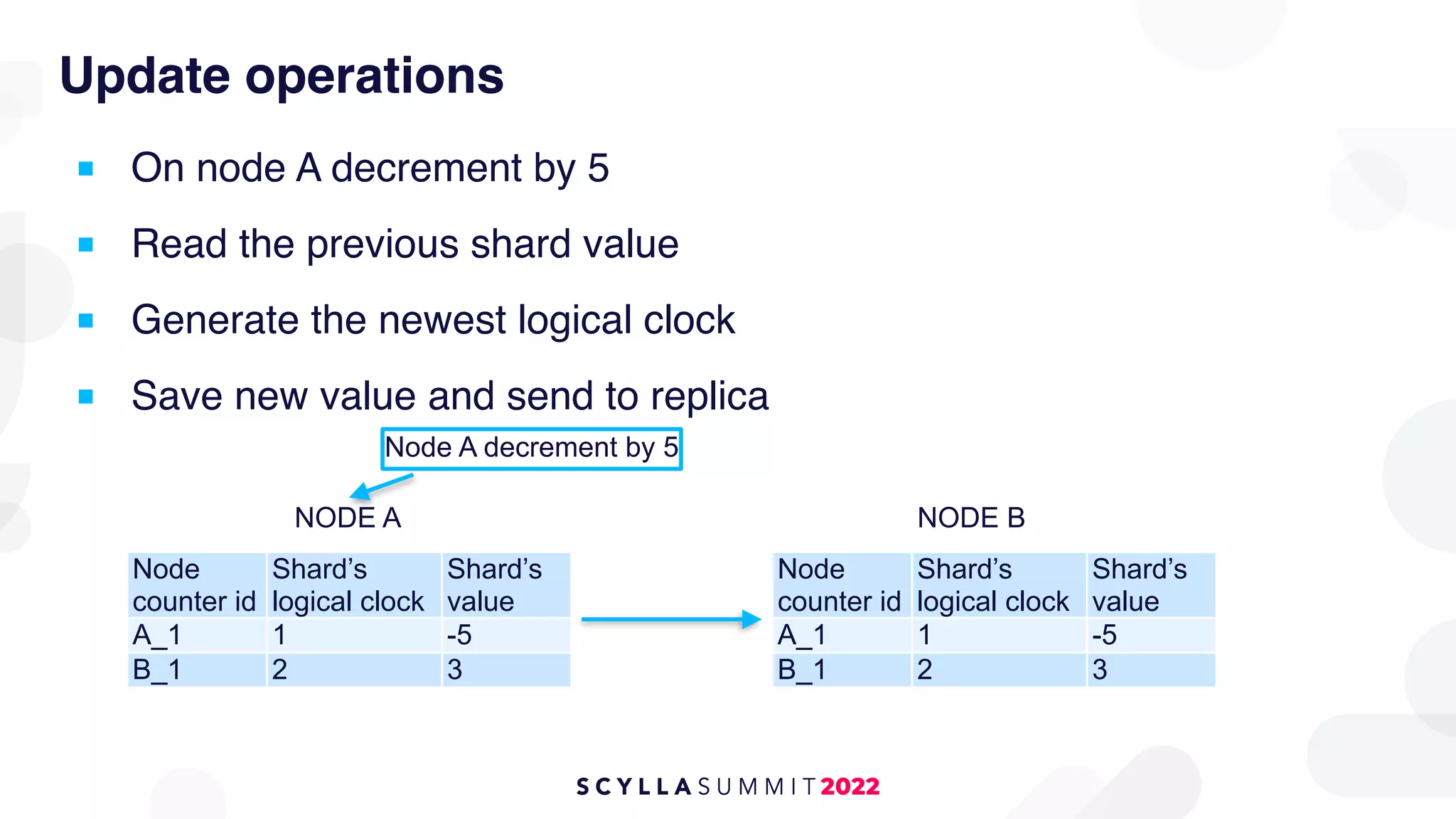


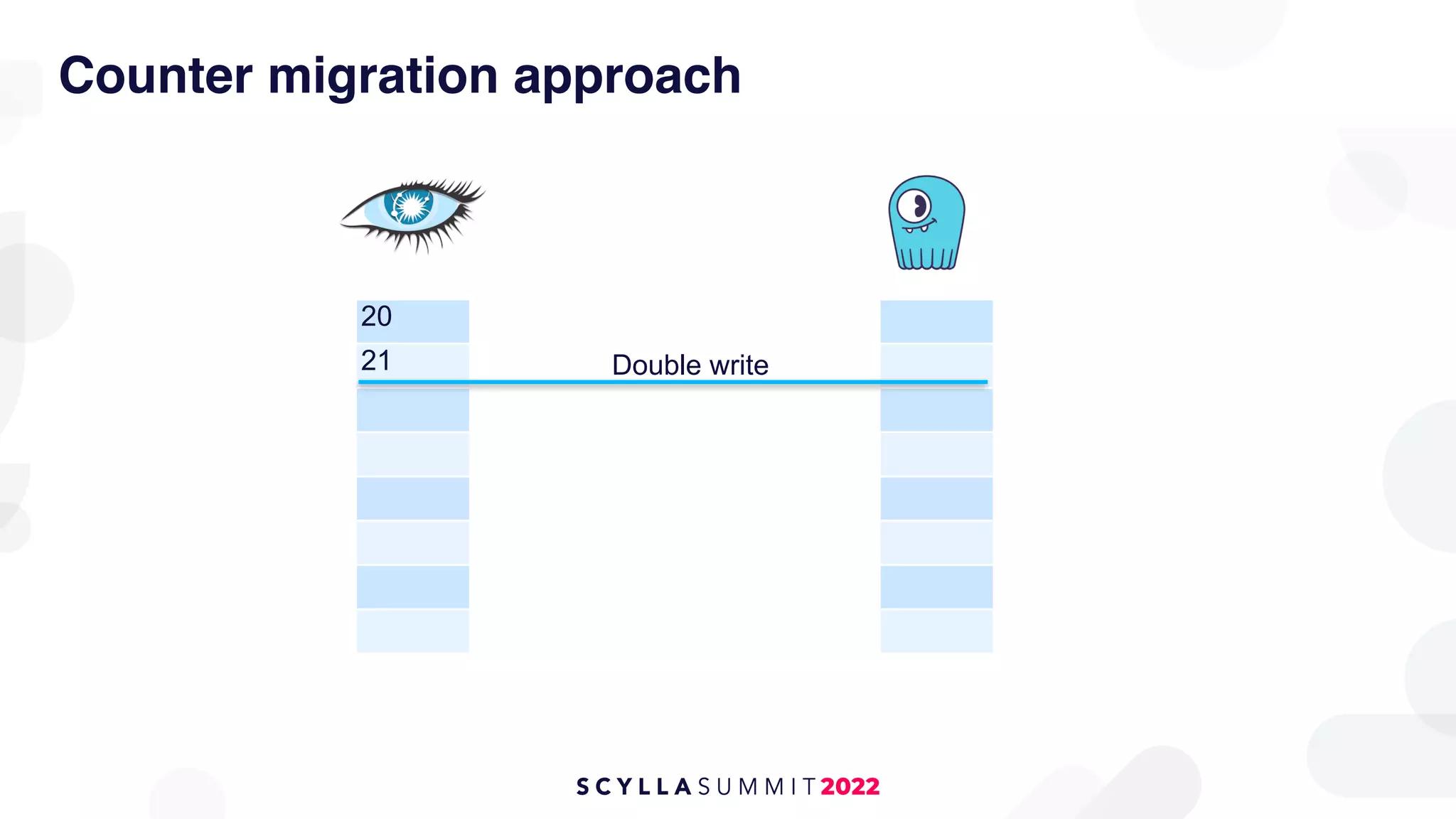
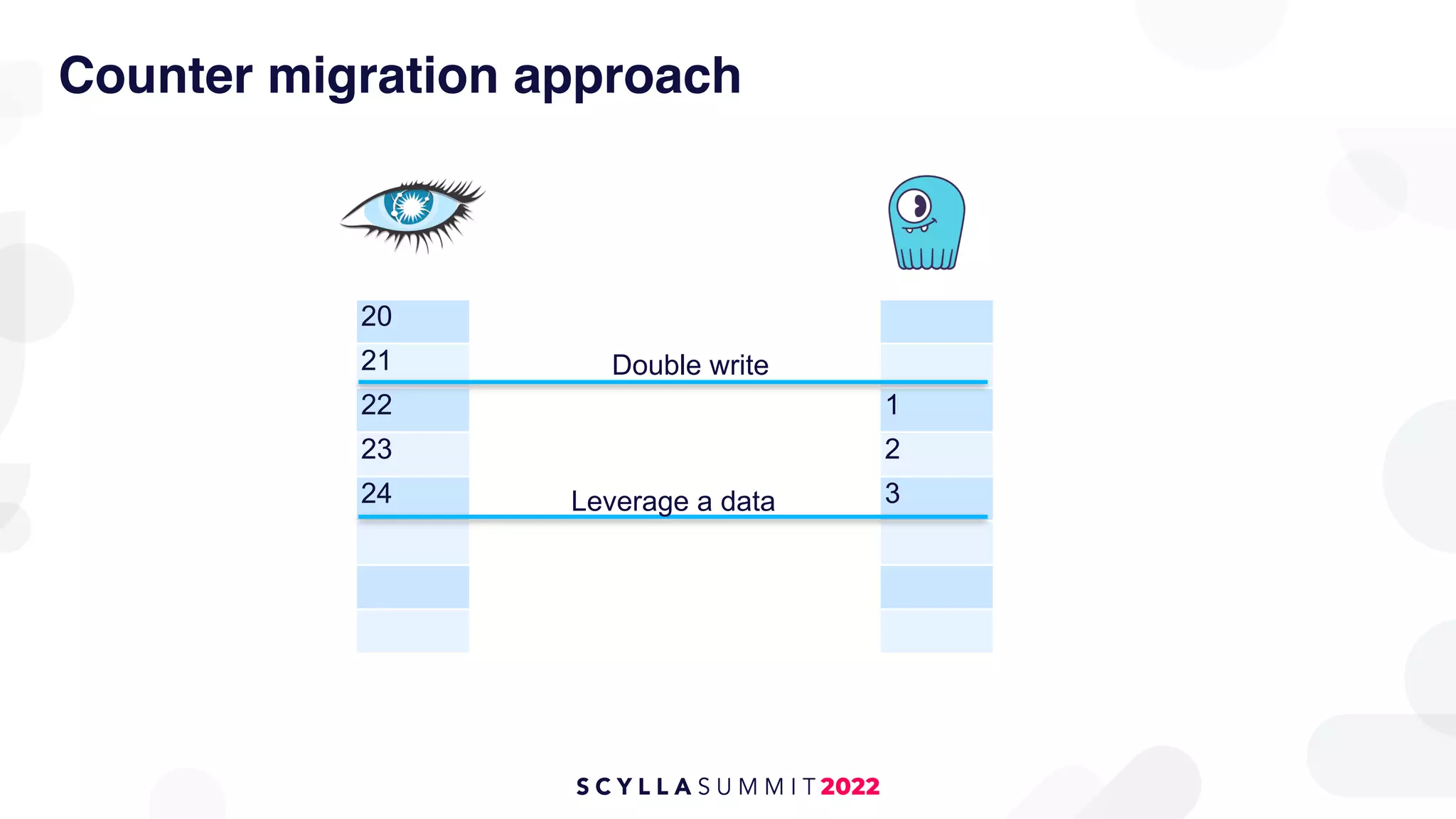















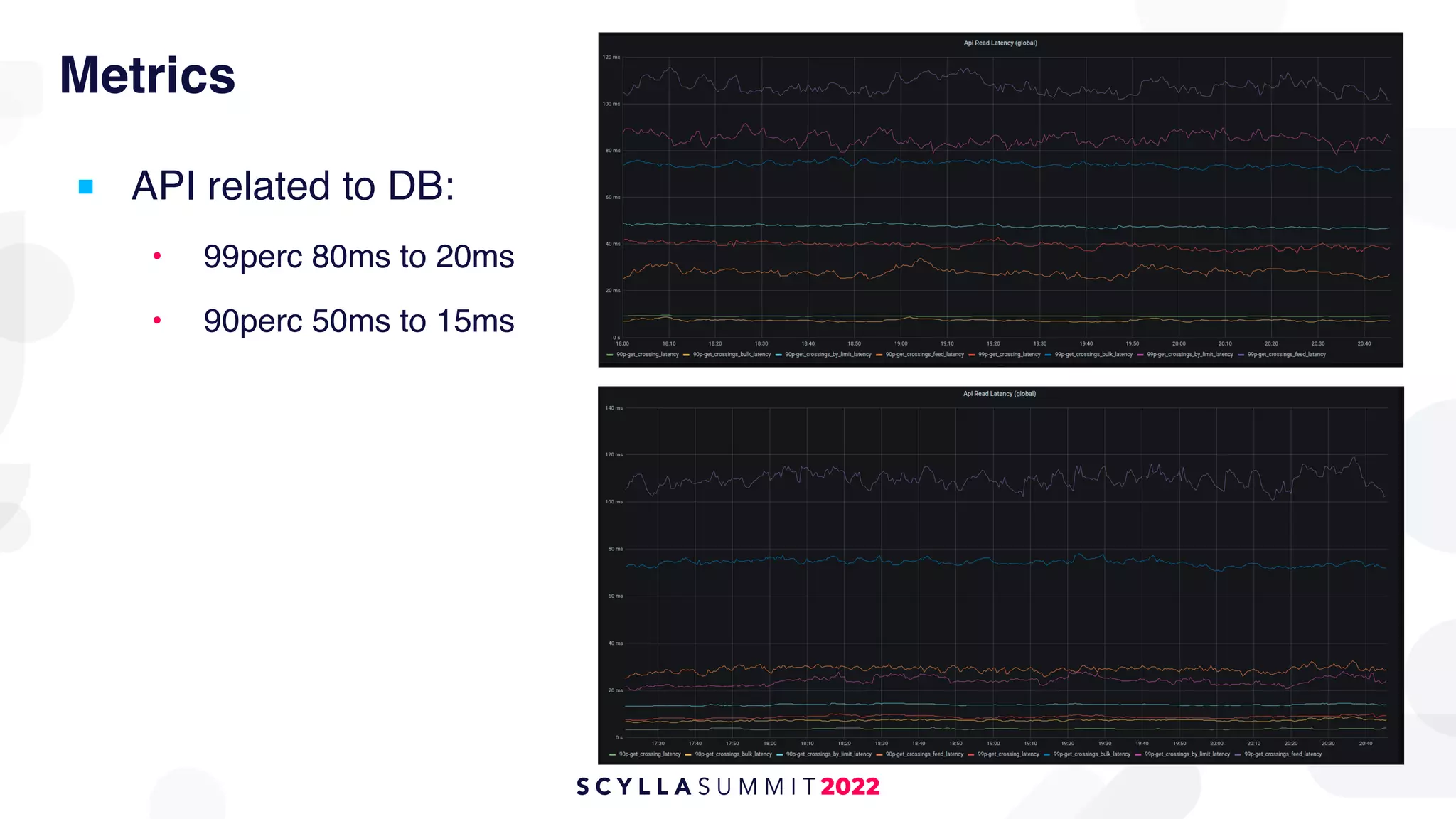
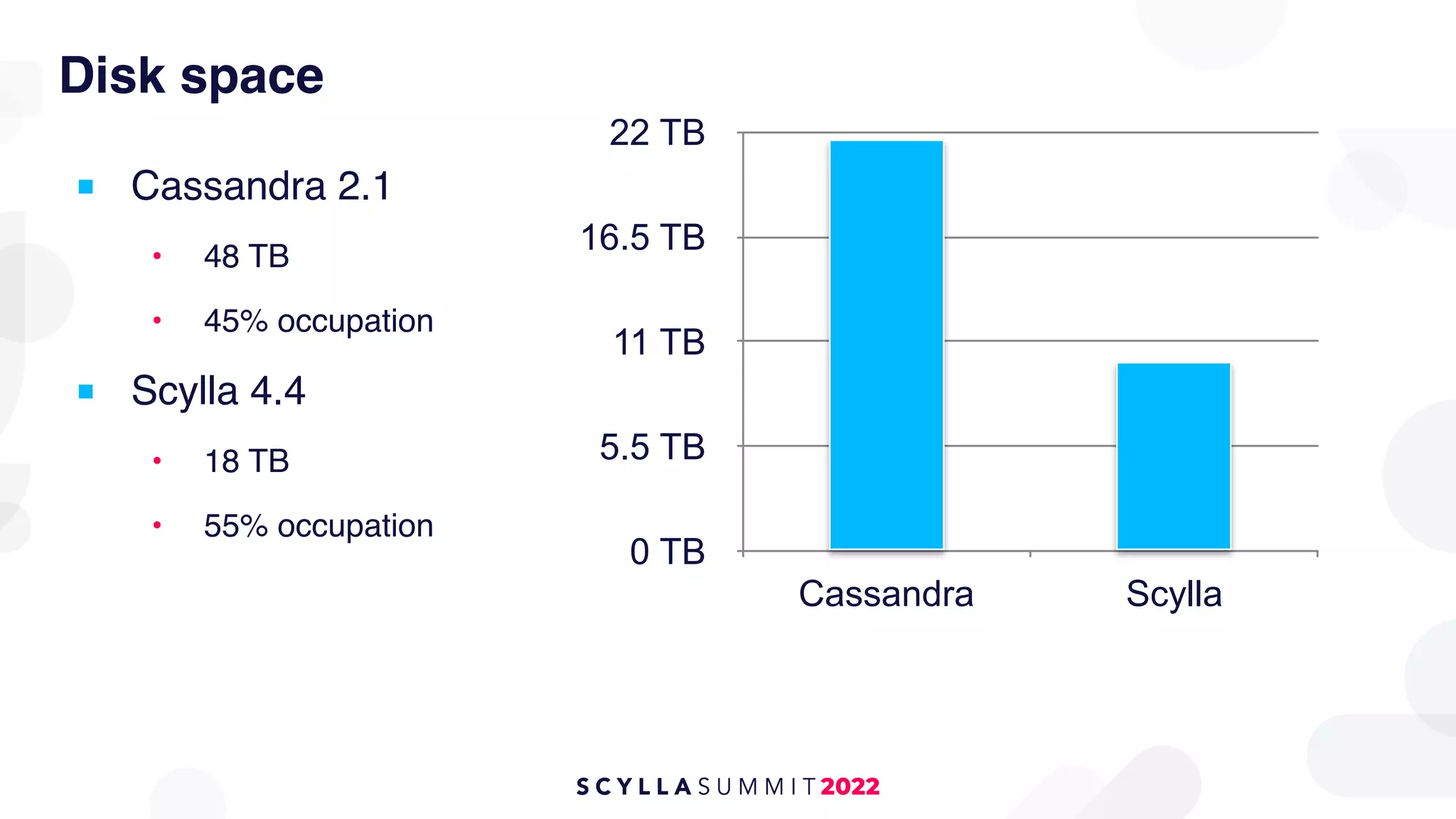

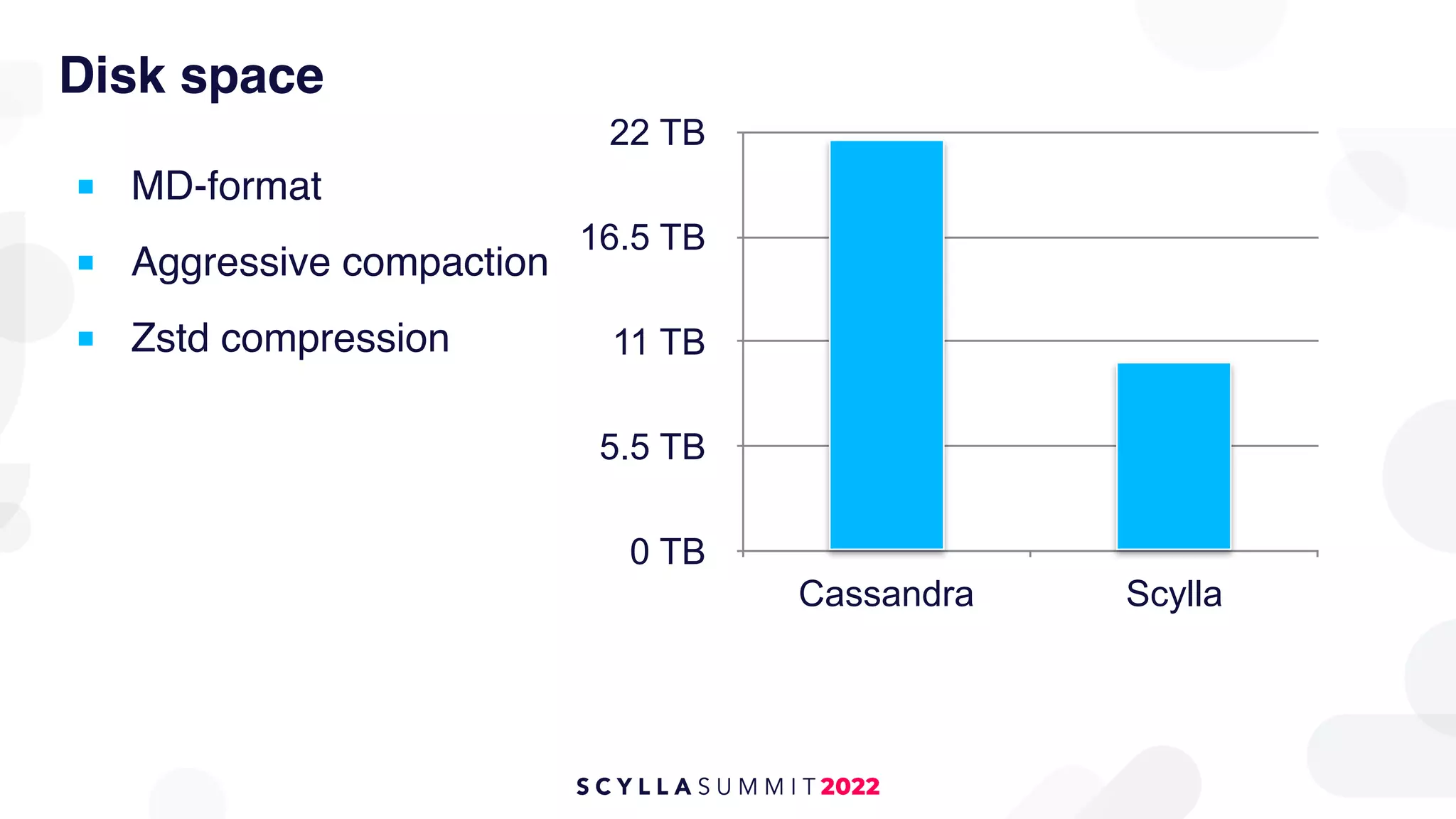






The document outlines the migration of a counter table containing 68 billion records from Cassandra to ScyllaDB, detailing the technical challenges and strategies employed. It describes the migration approach involving a double write technique, data leveraging methods, and the creation of a custom counter migrator application. The successful outcome of the migration resulted in improved system performance, reduced total cost of ownership by 75%, and effectively utilized resources across fewer clusters.









































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













