Download as PDF, PPTX











![DATA MINING FUNCTIONALITIES
Multidimensional concept description: Characterization and
discriminationdiscrimination
Generalize, summarize, and contrast data characteristics, e.g.,
dry vs. wet regions
Frequent patterns, association, correlation vs. causality
Diaper Beer [0.5%, 75%] (Correlation or causality?)
Cl ifi i d di i Classification and prediction
Construct models (functions) that describe and distinguish
classes or concepts for future predictionp p
E.g., classify countries based on (climate), or classify cars
based on (gas mileage)
Predict some unknown or missing numerical values 19](https://image.slidesharecdn.com/cs501dmintro-180604113048/75/Cs501-dm-intro-19-2048.jpg)


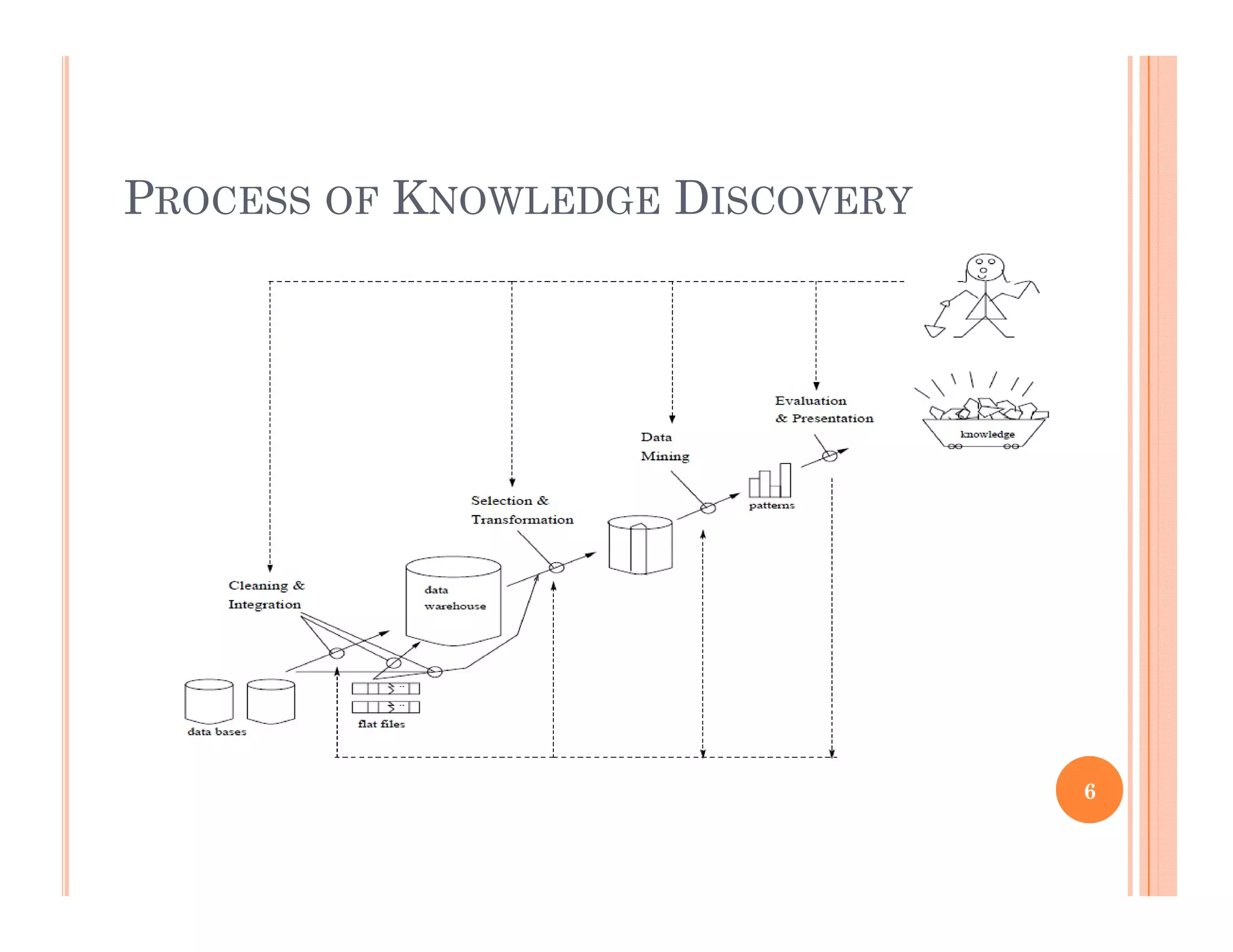
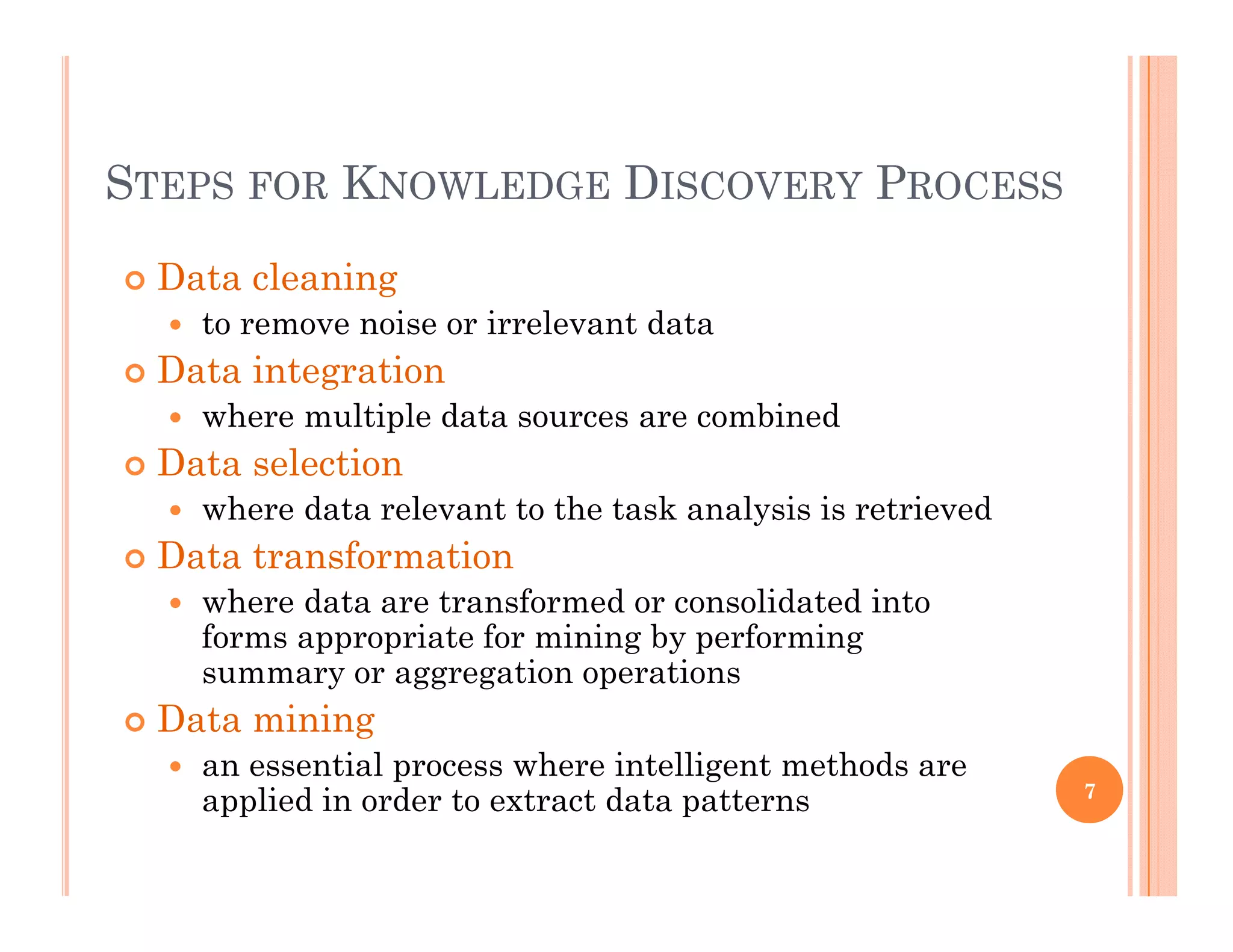
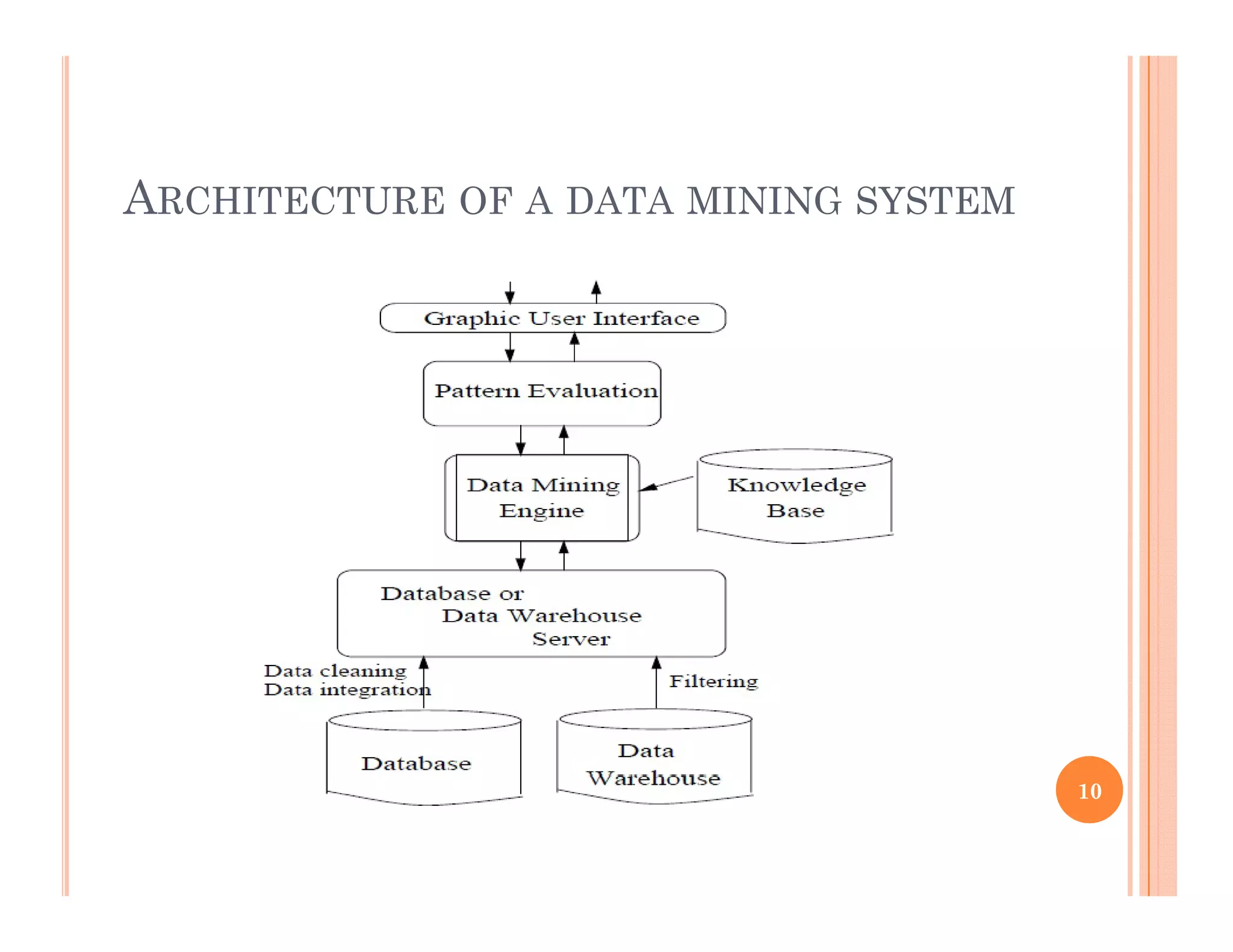
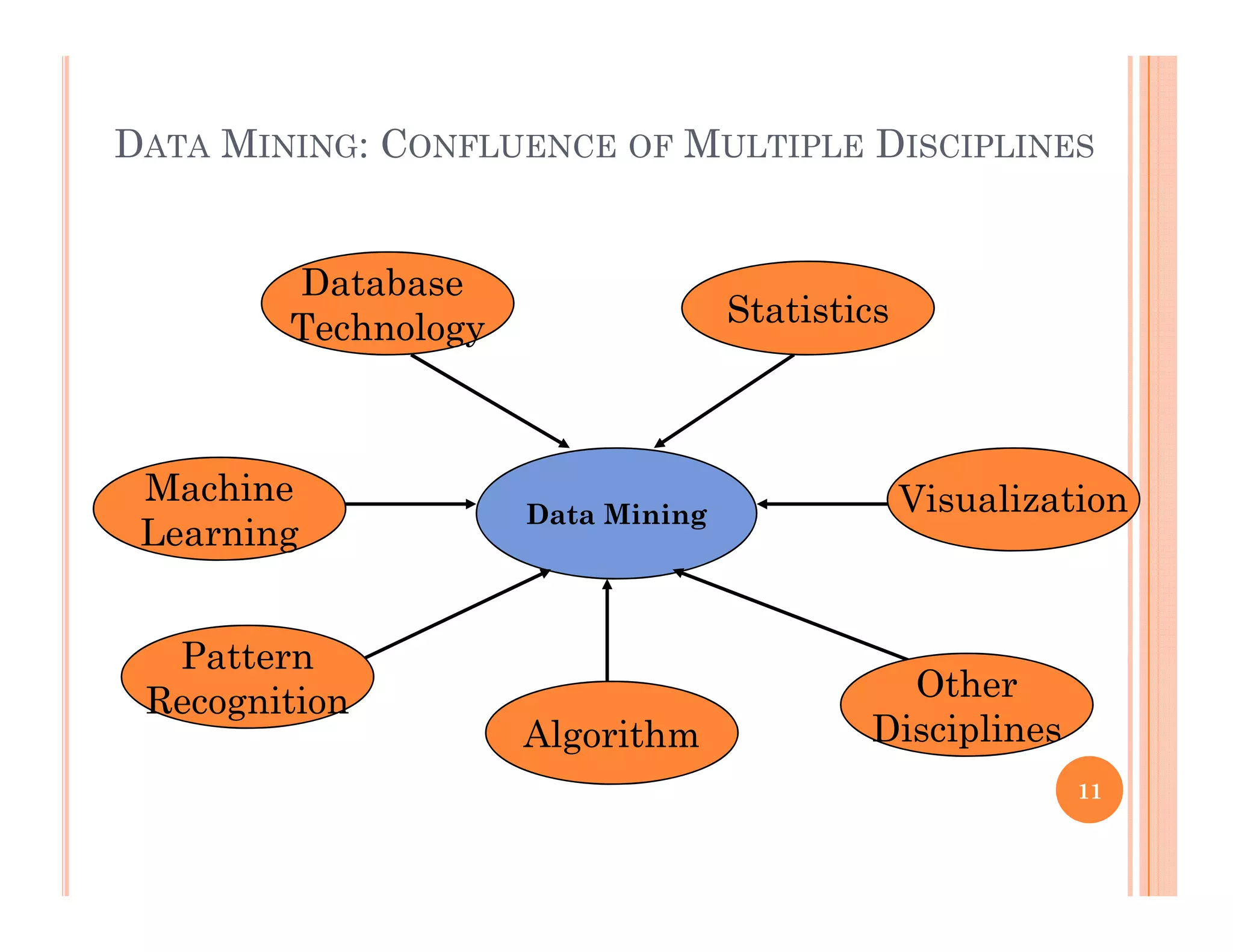
The document provides an introduction to data mining. It discusses the growth of data from terabytes to petabytes and how data mining can help extract knowledge from large datasets. The document outlines the evolution of sciences from empirical to theoretical to computational and now data-driven. It also describes the evolution of database technology and defines data mining as the process of discovering interesting patterns from large amounts of data. The key steps of the knowledge discovery process are discussed.



















































































