Download as PDF, PPTX










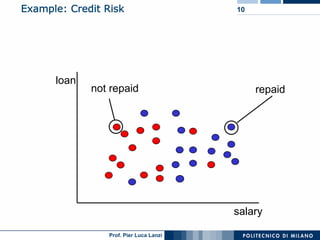
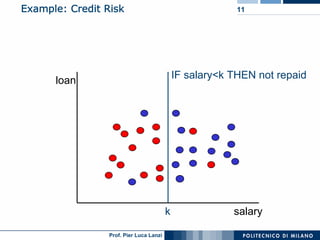


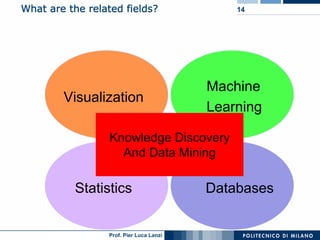


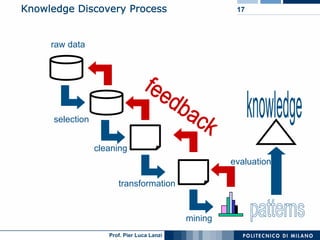

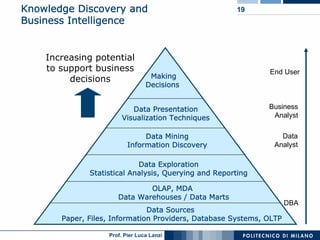
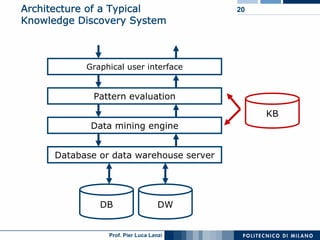


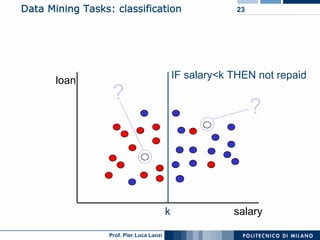

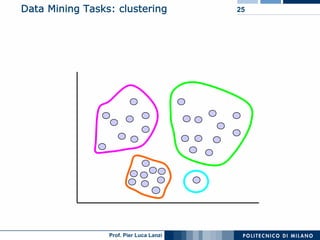





















The document outlines key aspects of data mining, including its necessity due to the explosive growth of data and various applications like customer attrition and credit assessment. It defines data mining as the process of discovering valid, novel, and useful patterns from large datasets and discusses related fields such as machine learning and knowledge discovery. Furthermore, it highlights major tasks in data mining, the knowledge discovery process, and addresses significant issues such as efficiency, scalability, and the integration of discovered knowledge.









































































































