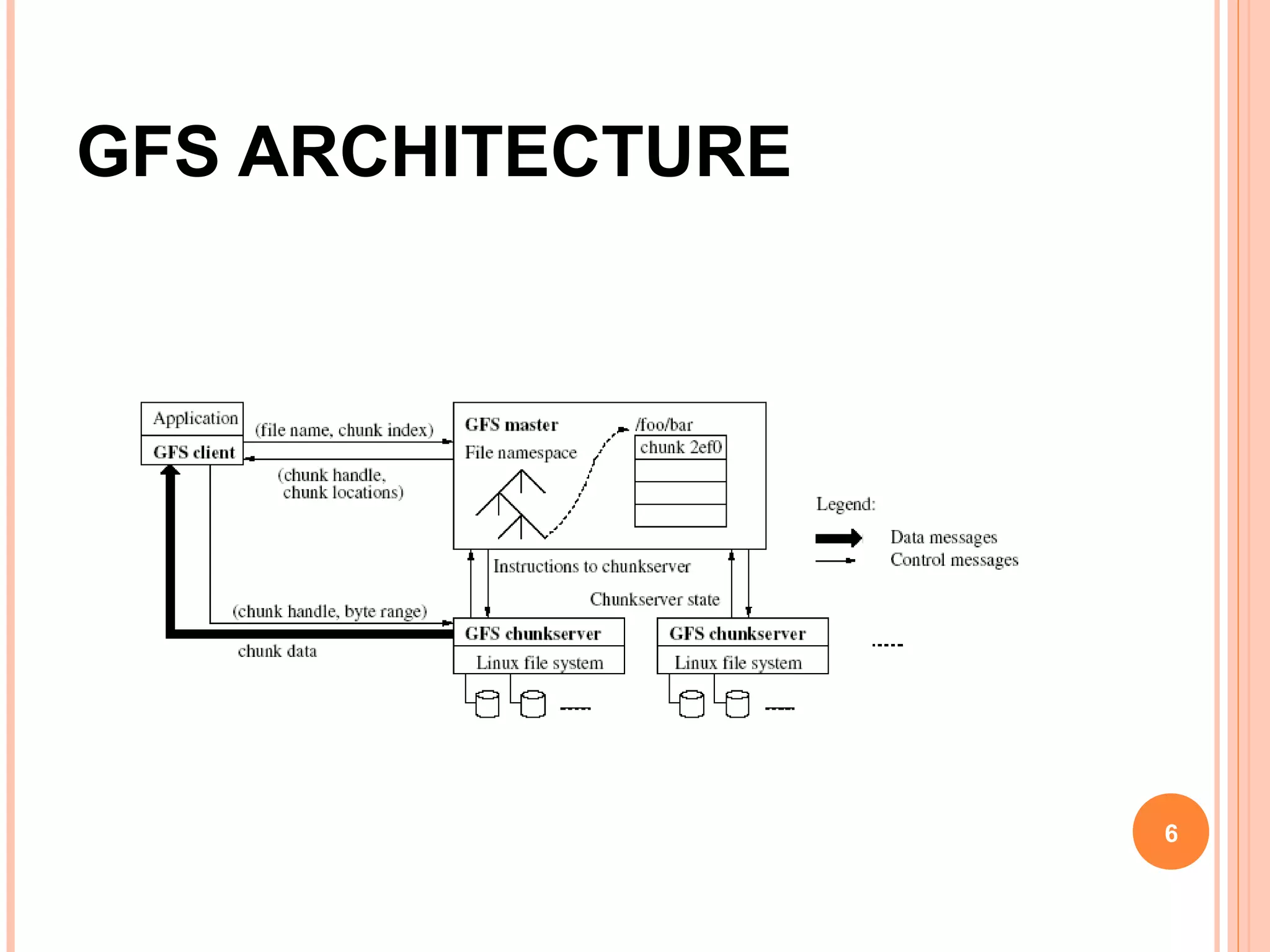
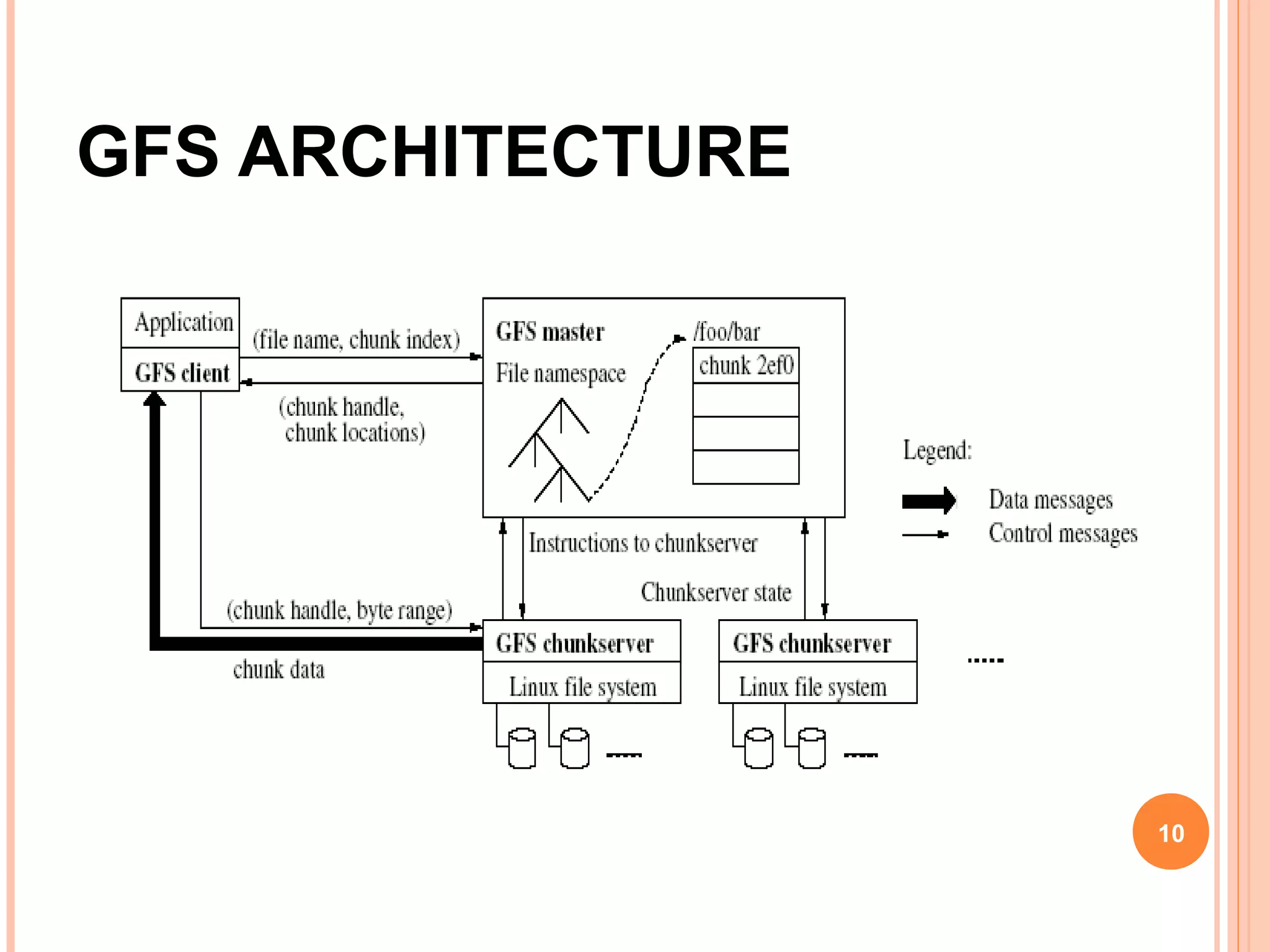
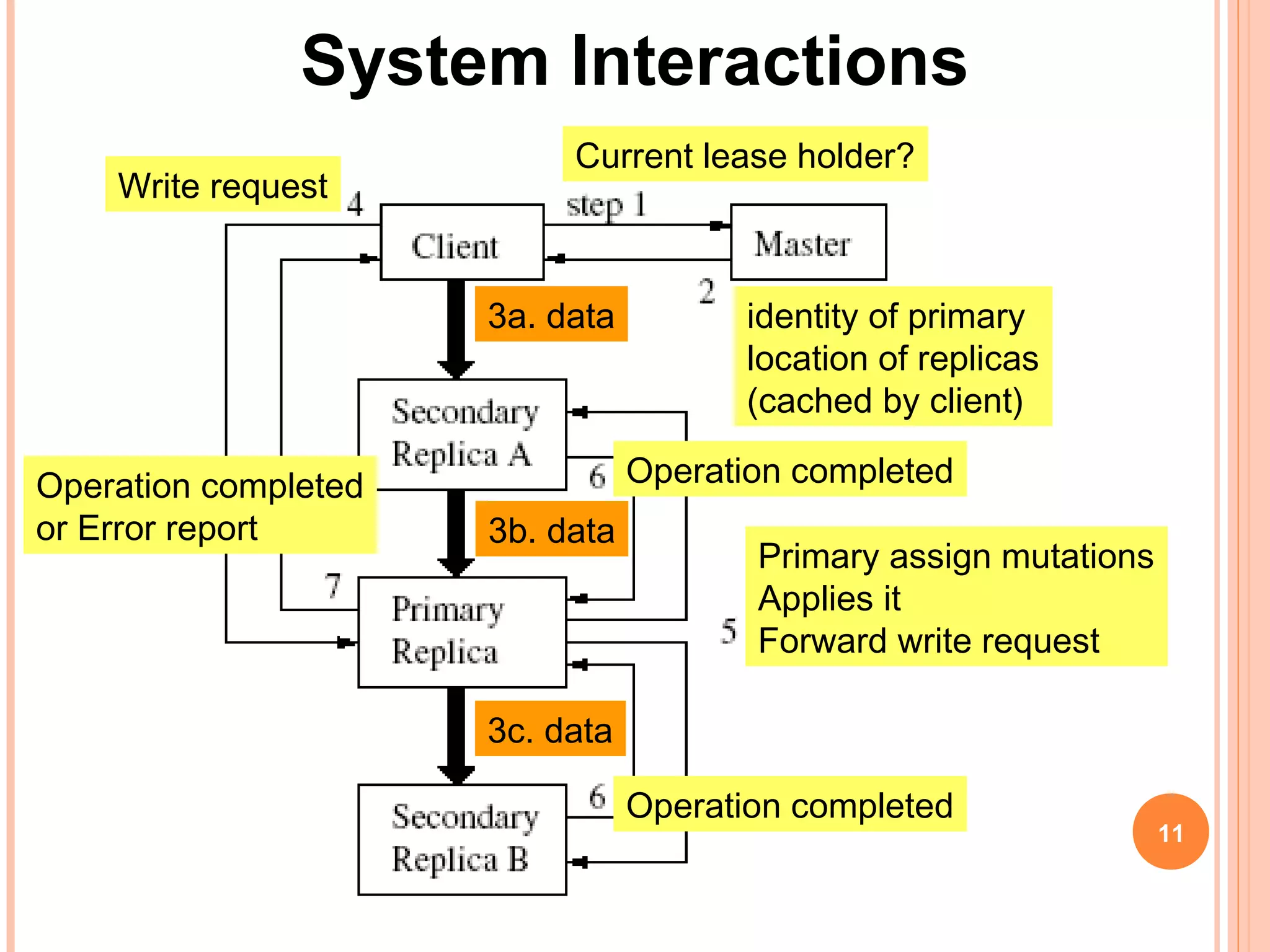
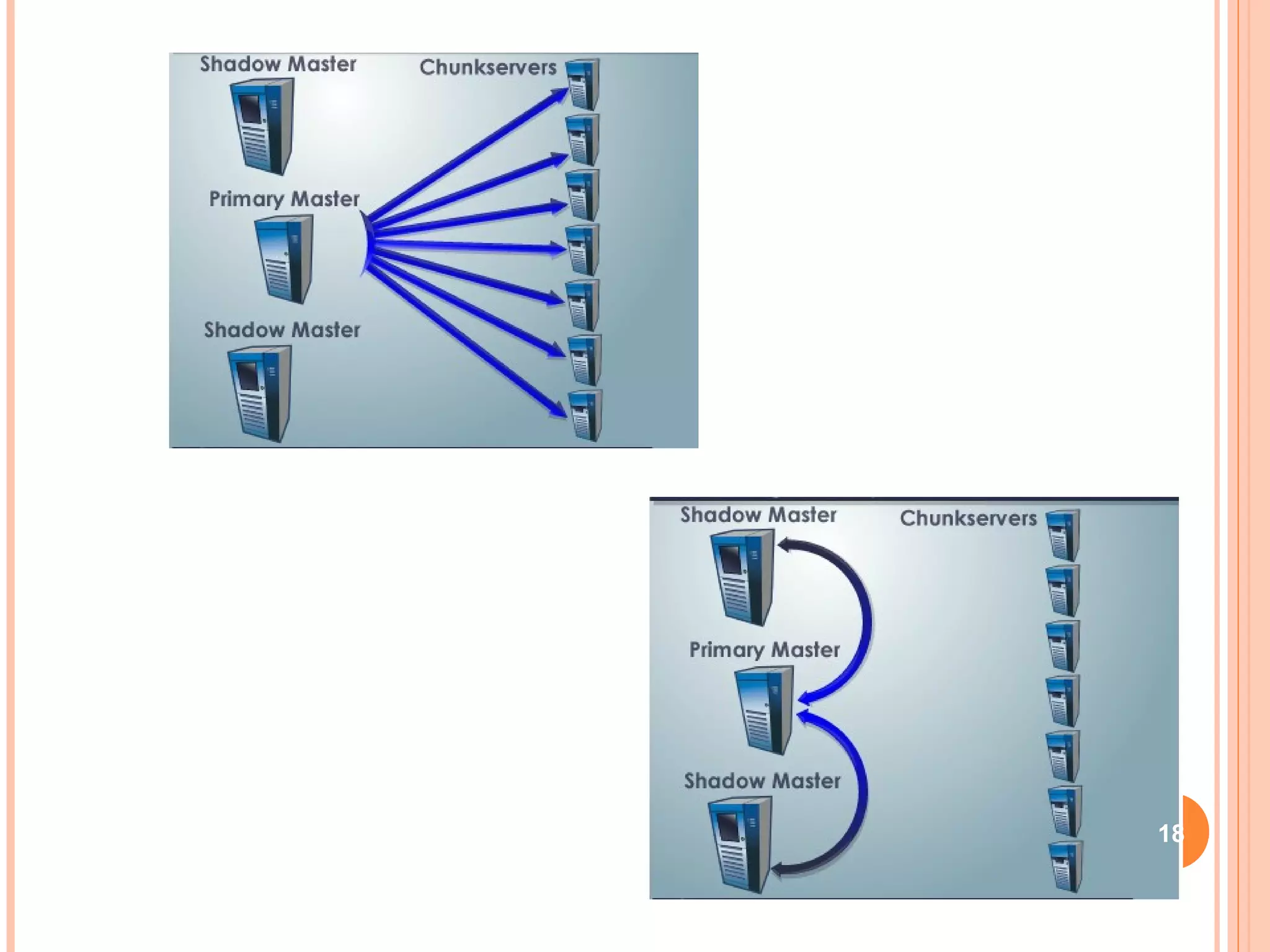
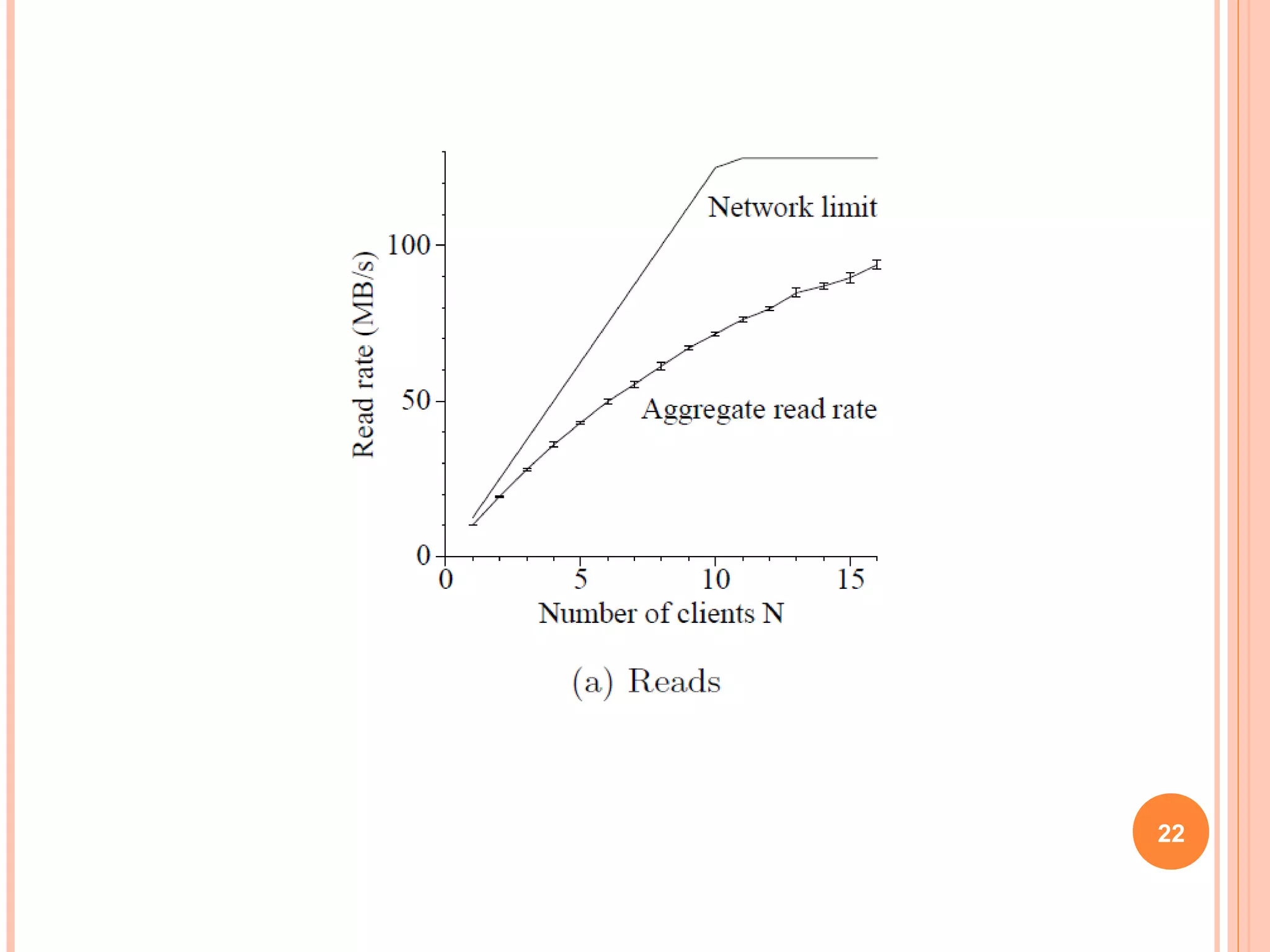
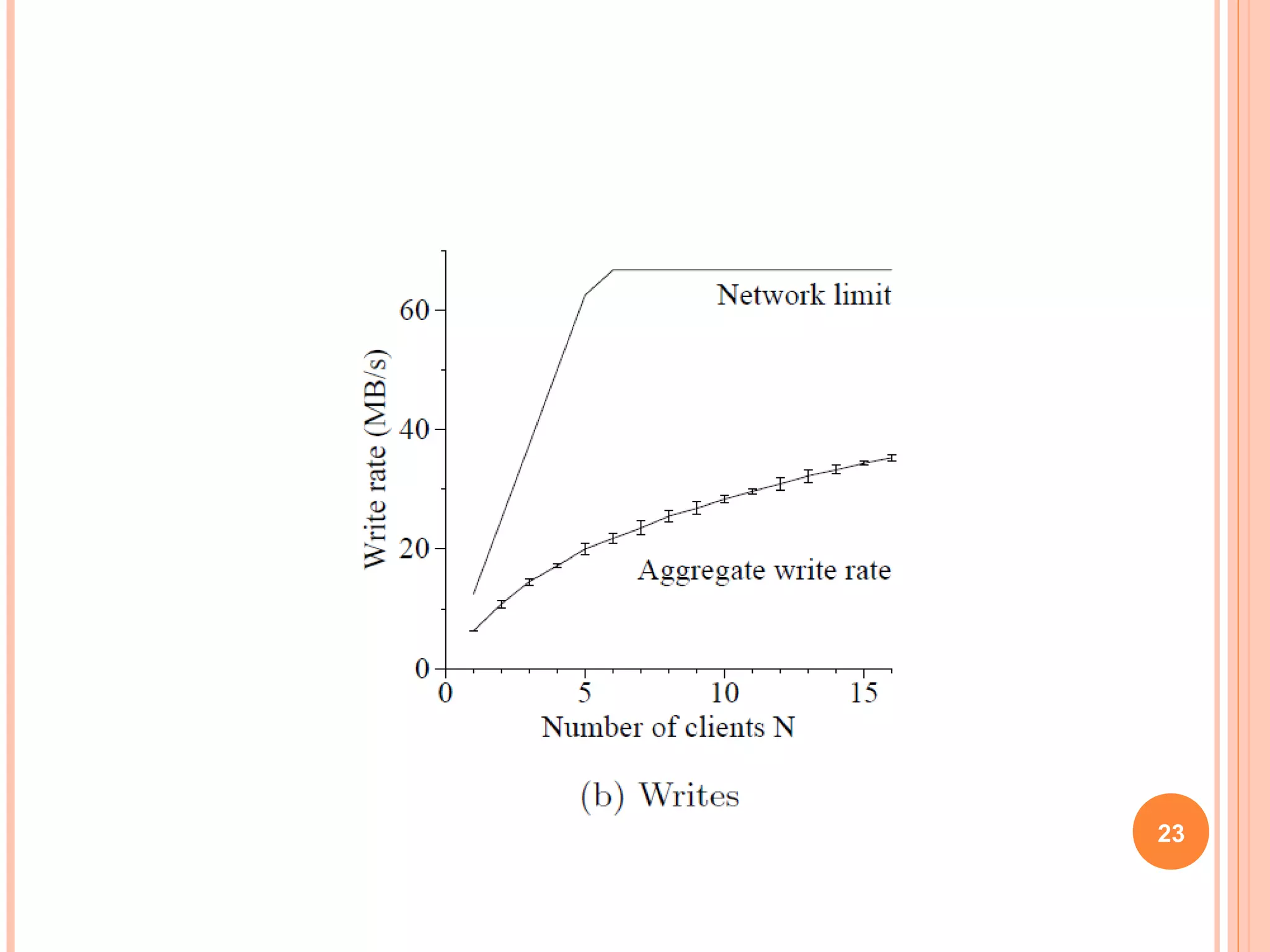
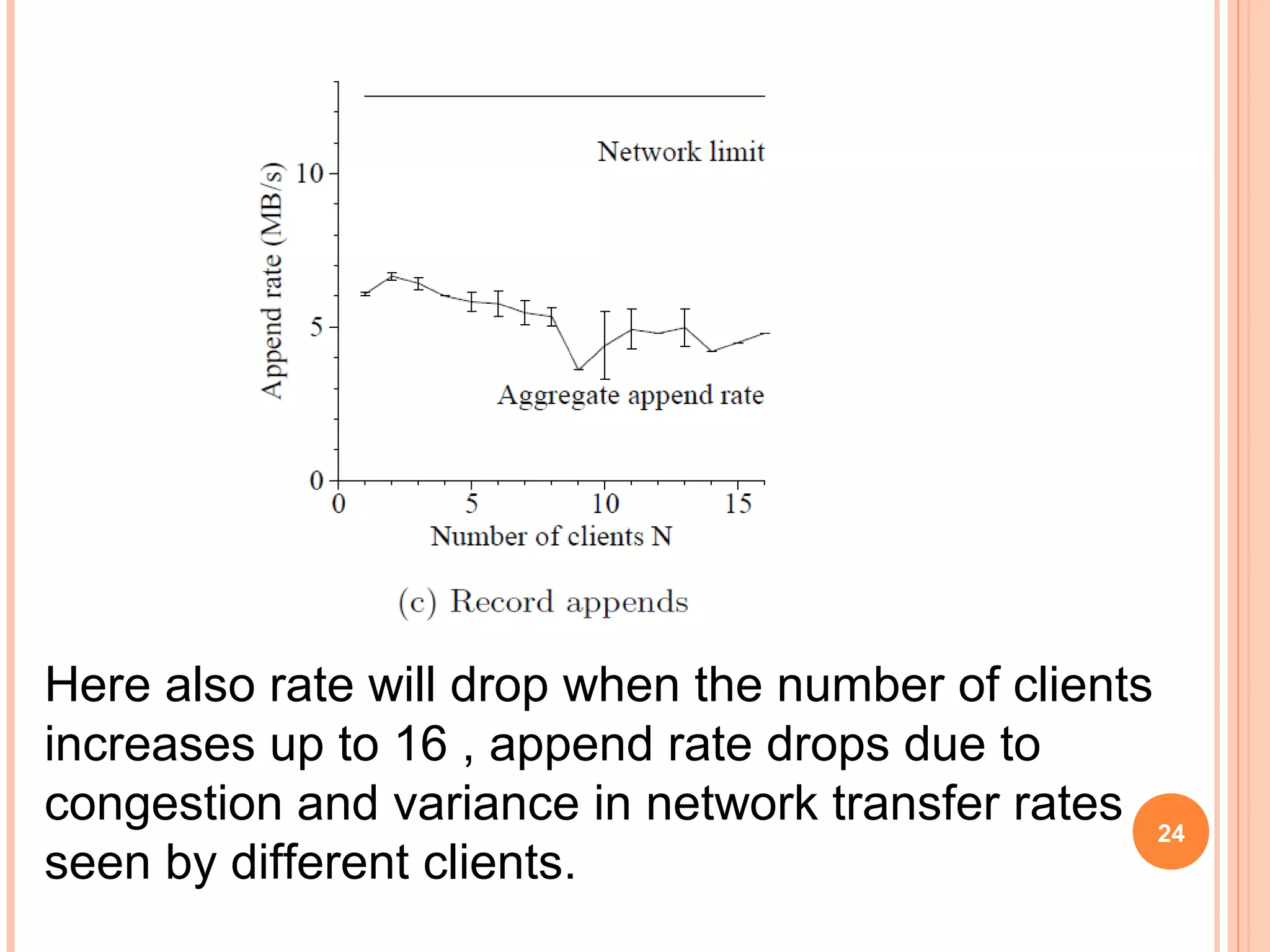
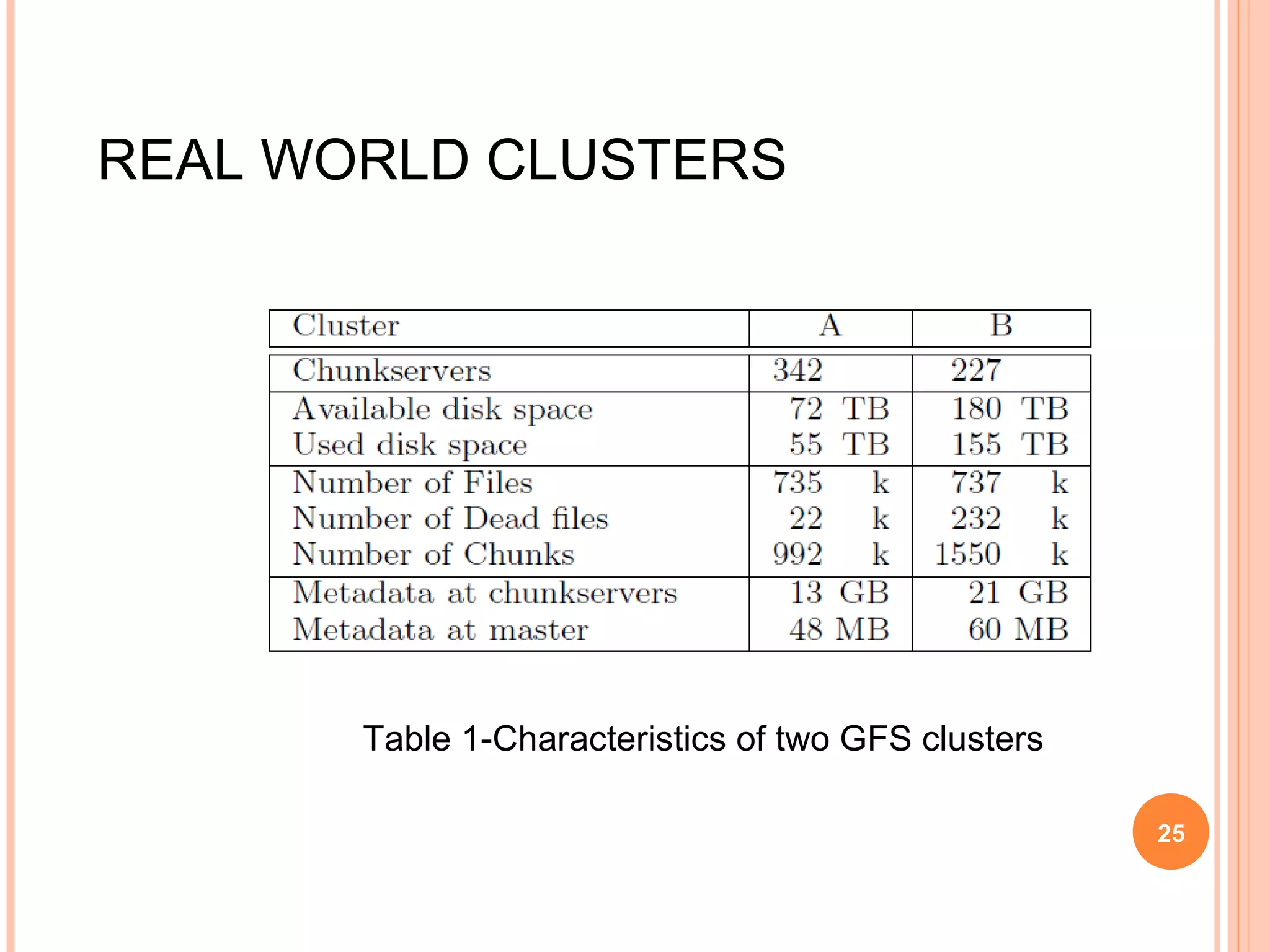
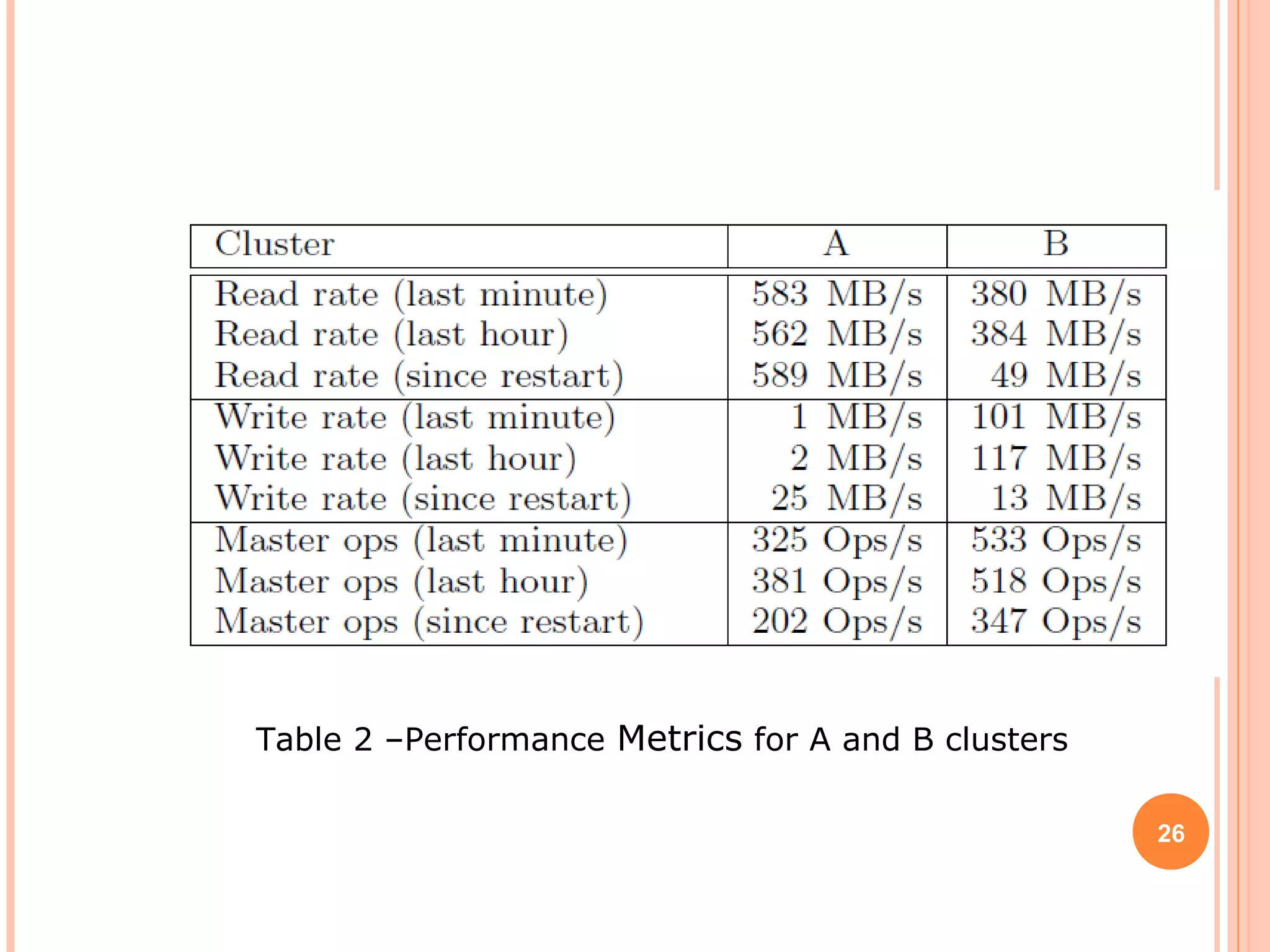
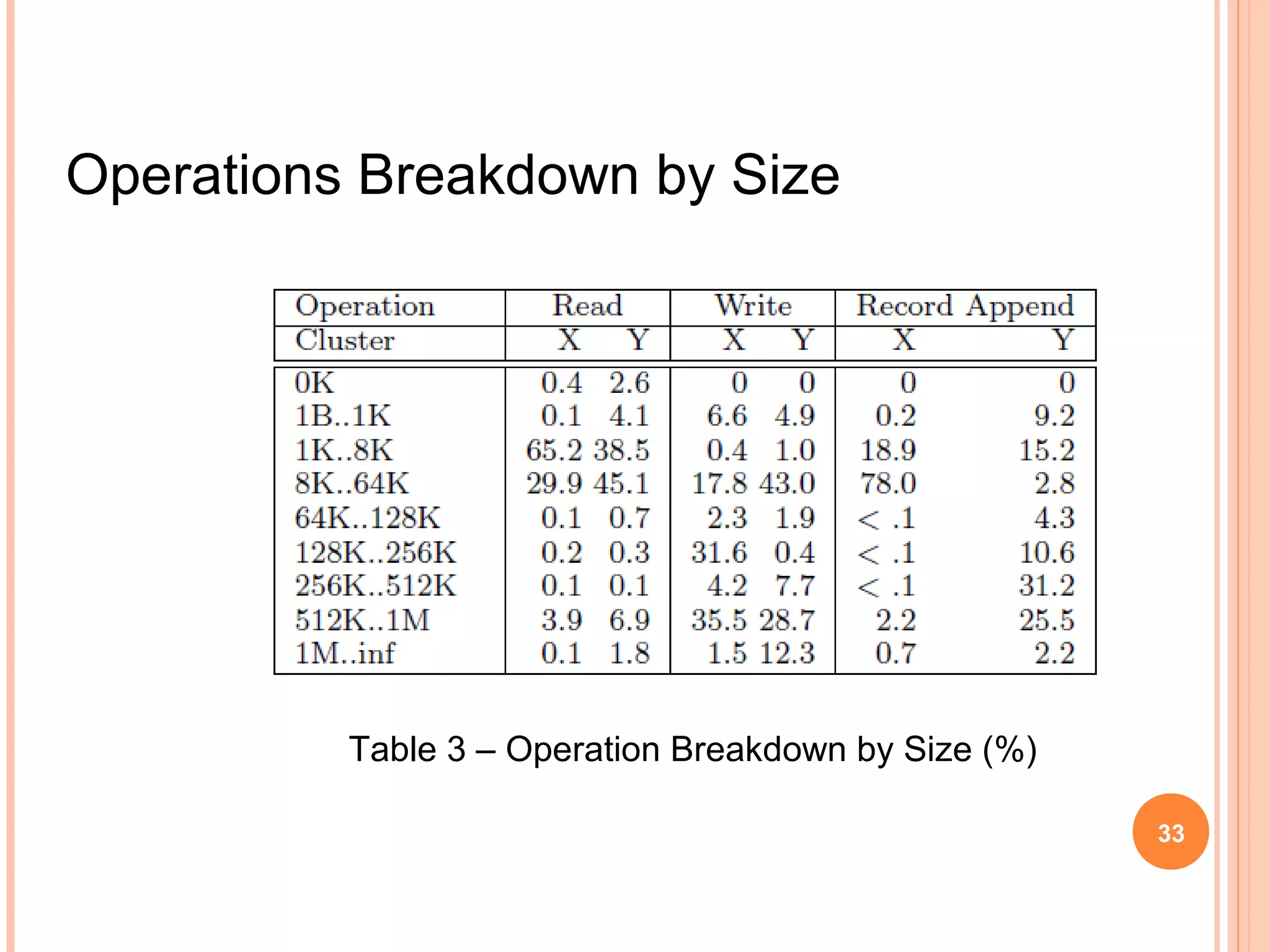
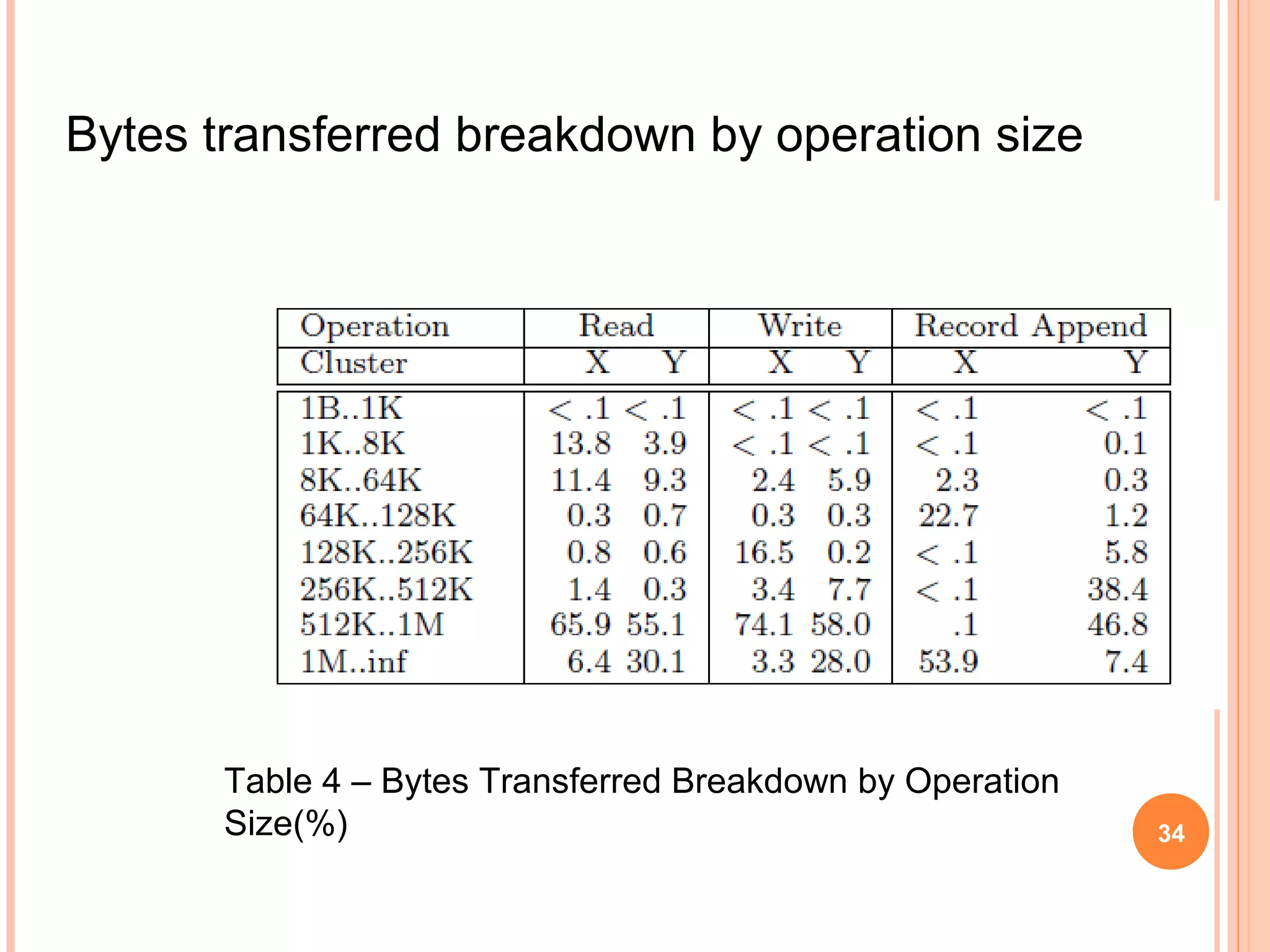
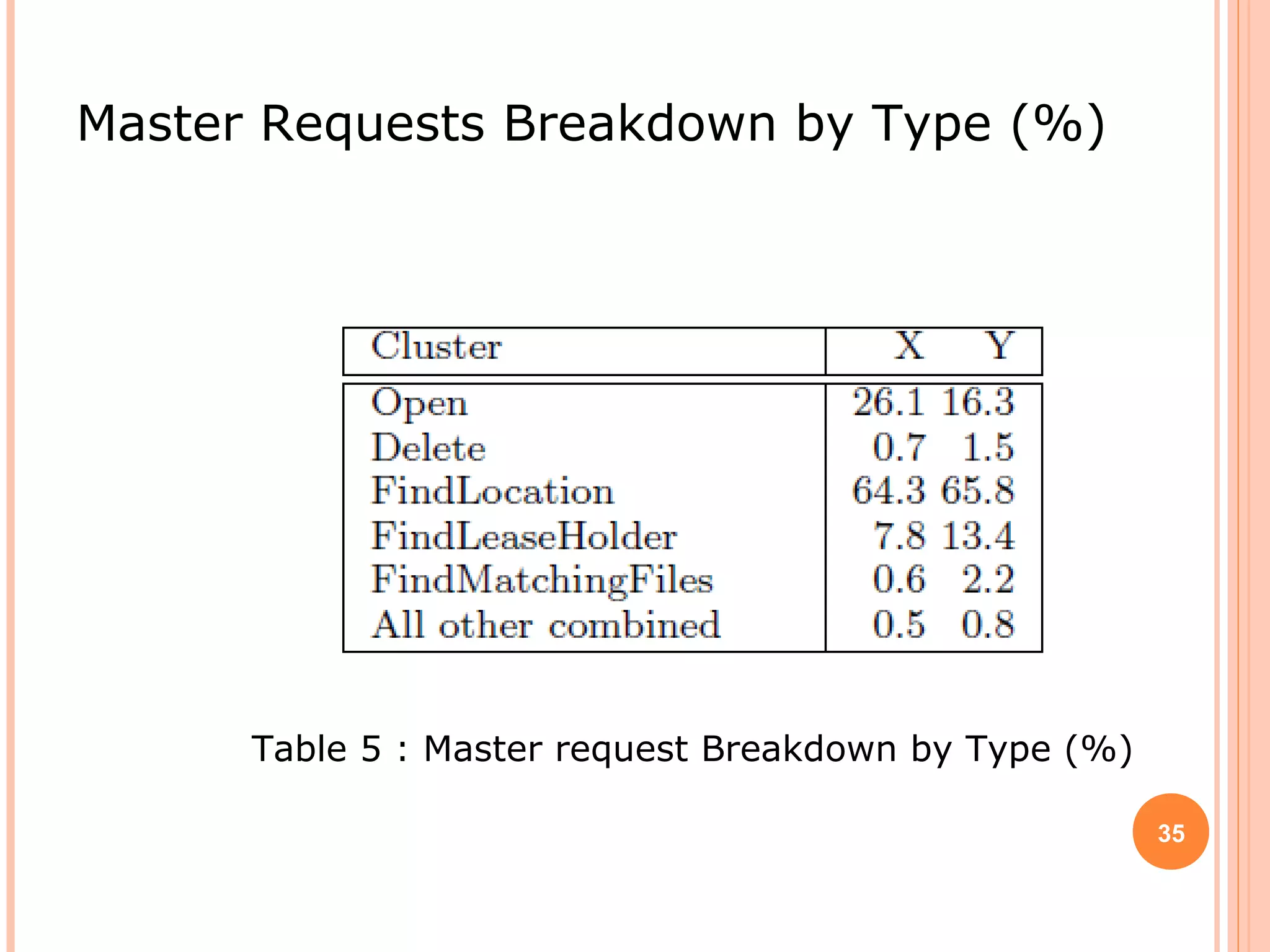
The Google File System (GFS) is a distributed file system designed to provide efficient, reliable access to data for Google's applications processing large datasets. GFS uses a master-slave architecture, with the master managing metadata and chunk servers storing file data in 64MB chunks replicated across machines. The system provides fault tolerance through replication, fast recovery of failed components, and logging of metadata operations. Performance testing showed it could support write rates of 30MB/s and recovery of 600GB of data from a failed chunk server in under 25 minutes. GFS delivers high throughput to concurrent users through its distributed architecture and replication of data.

































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














