Downloaded 102 times




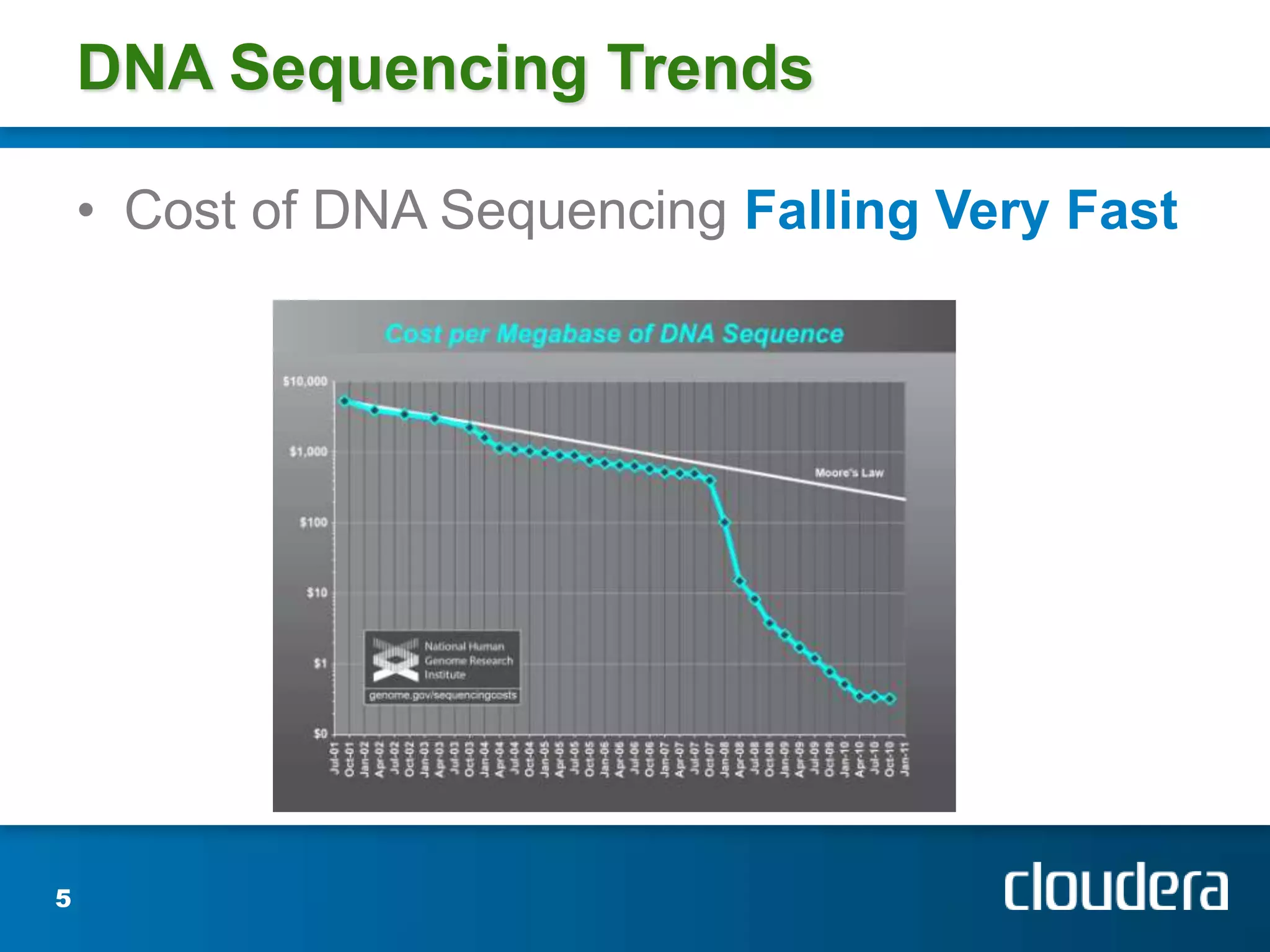
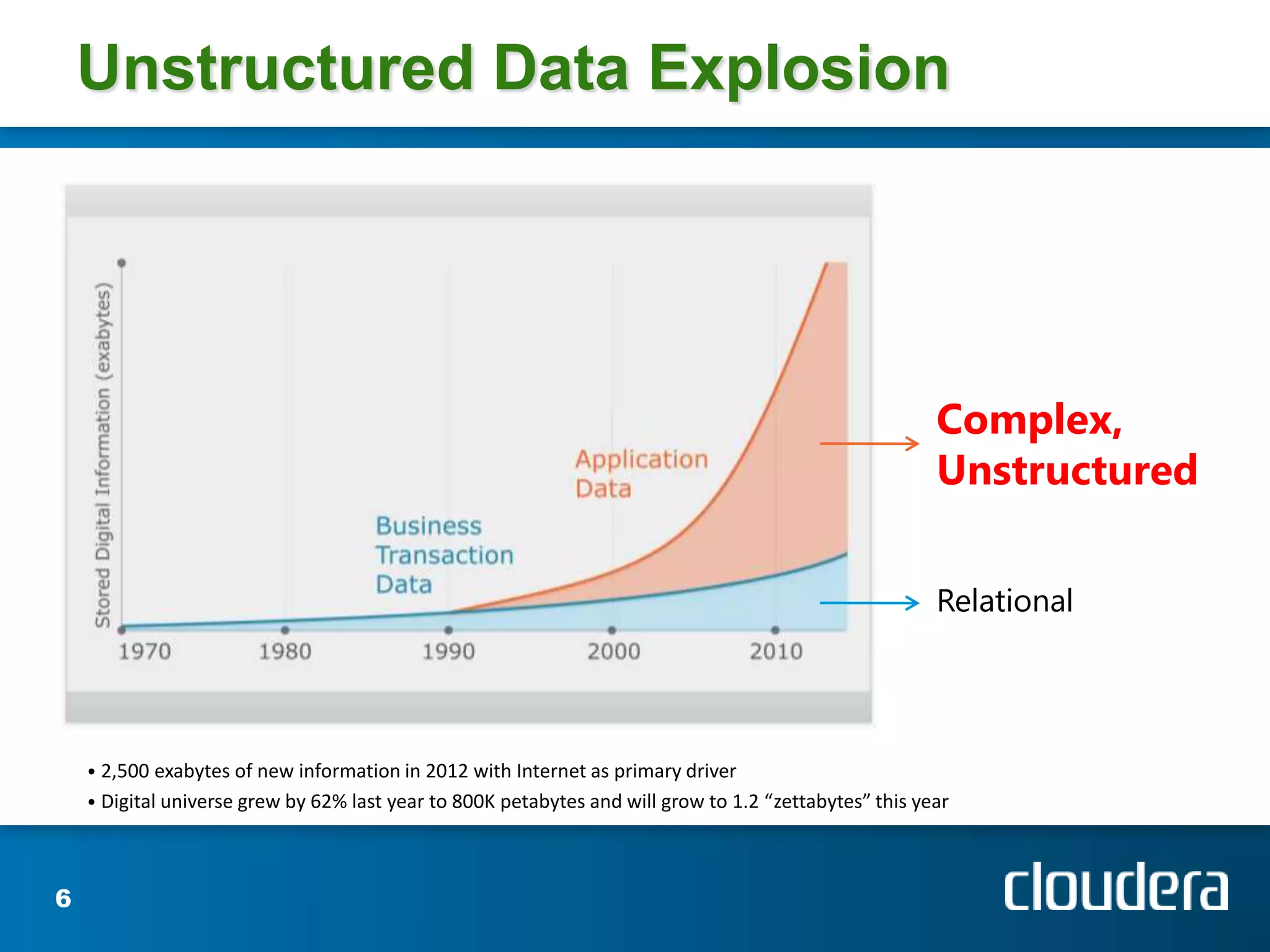














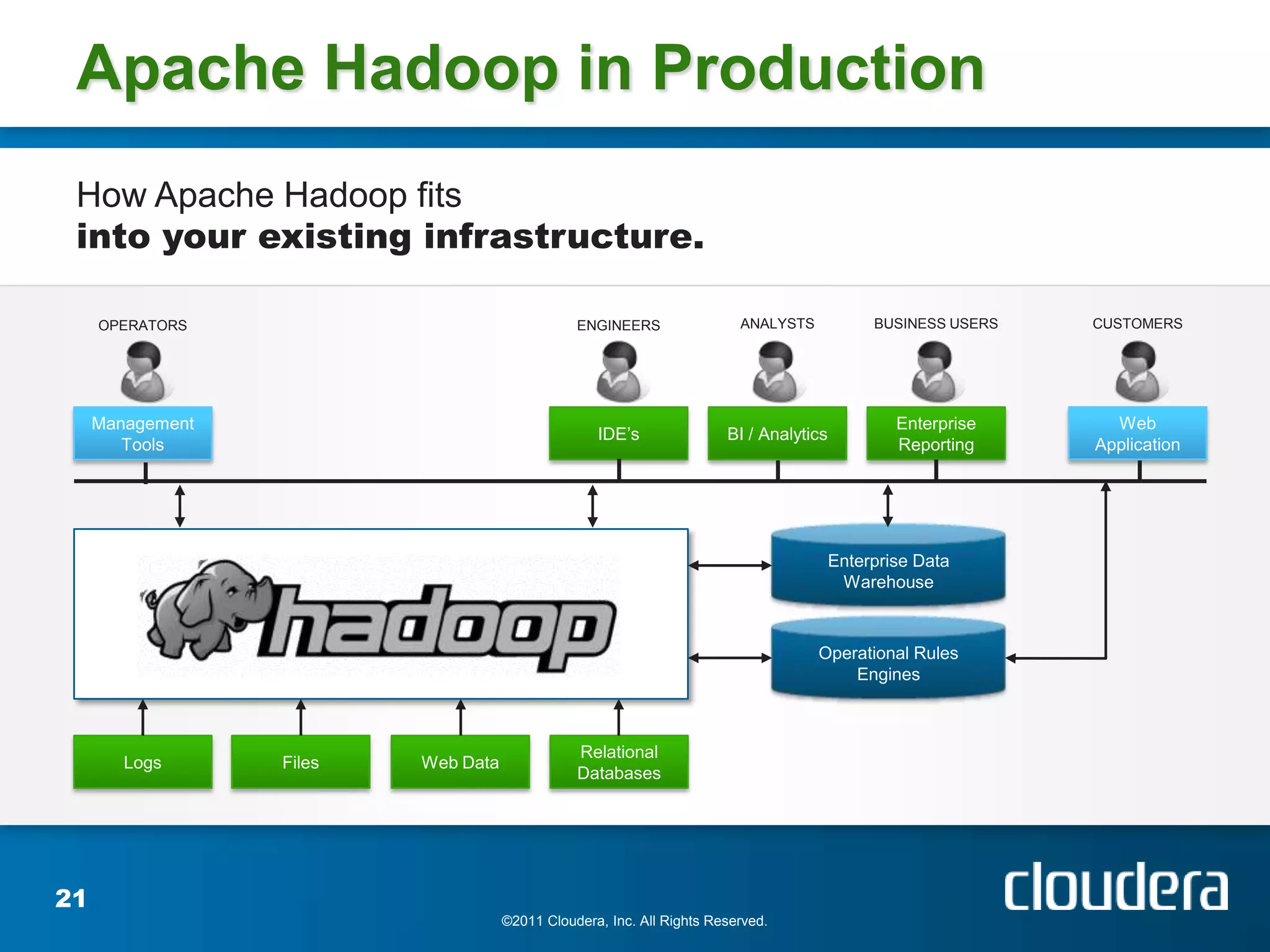

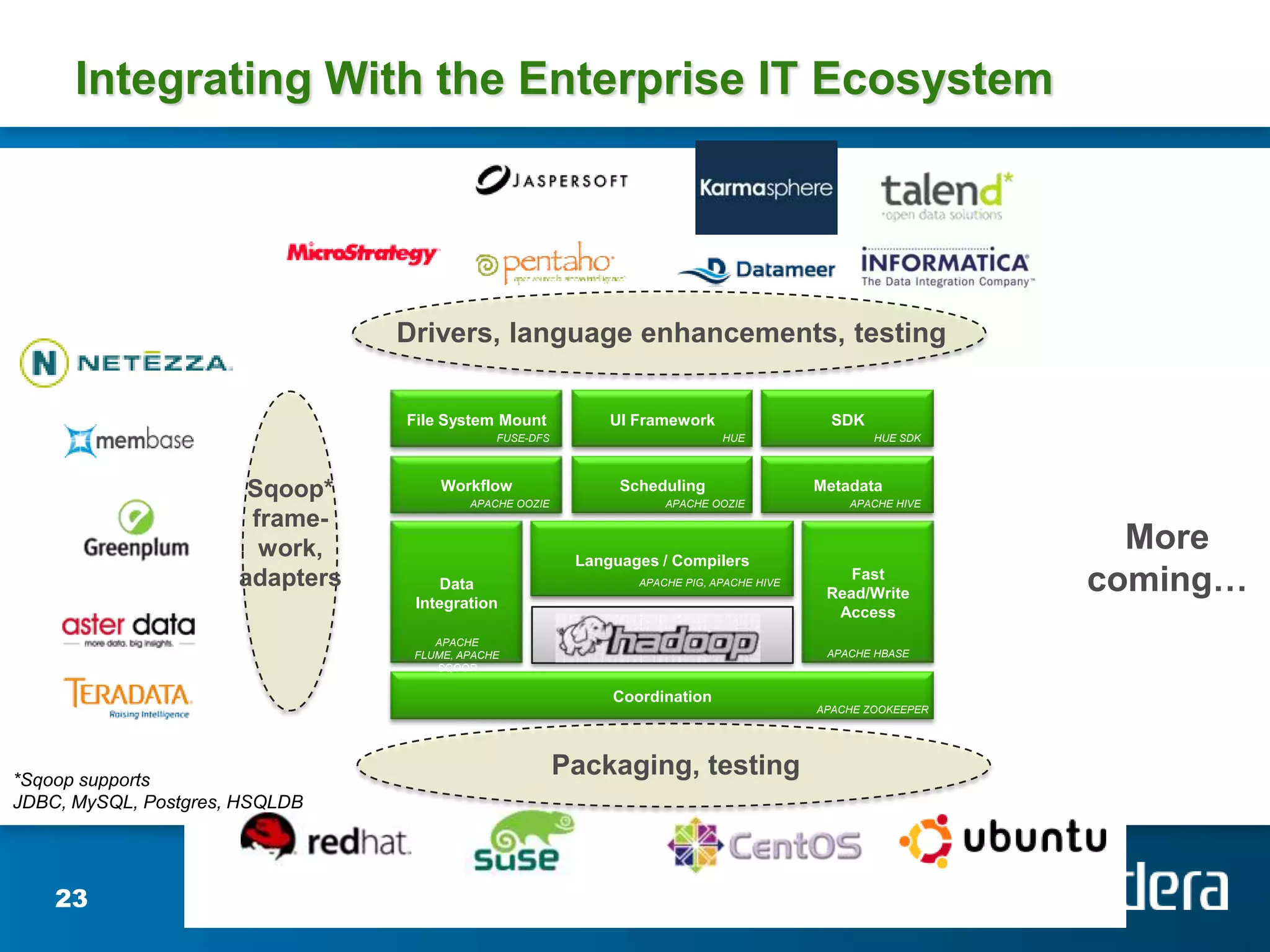











Josh Patterson gave a presentation on Hadoop and how it has been used. He discussed his background working on Hadoop projects including for the Tennessee Valley Authority. He outlined what Hadoop is, how it works, and examples of use cases. This includes how Hadoop was used to store and analyze large amounts of smart grid sensor data for the openPDC project. He discussed integrating Hadoop with existing enterprise systems and tools for working with Hadoop like Pig and Hive.






























































































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)







![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


