Downloaded 11 times
















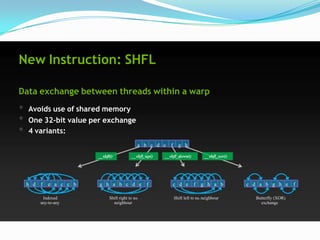
![SHFL Example: Warp Prefix-Sum
__global__ void shfl_prefix_sum(int *data)
{ 3 8 2 6 3 9 1 4
int id = threadIdx.x;
int value = data[id]; n = __shfl_up(value, 1)
int lane_id = threadIdx.x & warpSize;
value += n 3 11 10 8 9 12 10 5
// Now accumulate in log2(32) steps n = __shfl_up(value, 2)
for(int i=1; i<=width; i*=2) {
int n = __shfl_up(value, i); value += n 3 11 13 19 19 20 19 17
if(lane_id >= i)
value += n; n = __shfl_up(value, 4)
}
value += n 3 11 13 19 21 31 32 36
// Write out our result
data[id] = value;
}](https://image.slidesharecdn.com/gpuarchi-130408004542-phpapp01/85/Gpu-archi-20-320.jpg)






![const __restrict Example
Annotate eligible kernel __global__ void saxpy(float x, float y,
const float * __restrict input,
parameters with float * output)
{
const __restrict size_t offset = threadIdx.x +
(blockIdx.x * blockDim.x);
Compiler will automatically // Compiler will automatically use texture
map loads to use read-only // for "input"
output[offset] = (input[offset] * x) + y;
data cache path }](https://image.slidesharecdn.com/gpuarchi-130408004542-phpapp01/85/Gpu-archi-28-320.jpg)


1. The CUDA programming model uses parallel threads organized in cooperative thread arrays (CTAs) to execute the same program on many threads simultaneously. 2. CTAs are grouped into grids and threads within a CTA can share memory. Each CTA implements a thread block. 3. The GPU architecture has streaming multiprocessors that perform computations and global memory like CPU RAM that is accessible to both the GPU and CPU.
























![[Harvard CS264] 05 - Advanced-level CUDA Programming](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201105-cudaadvancedsharetmp-110222173227-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








![[05][cuda 및 fermi 최적화 기술] hryu optimization](https://cdn.slidesharecdn.com/ss_thumbnails/05cudafermihryuoptimization-110106231451-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























