Downloaded 42 times










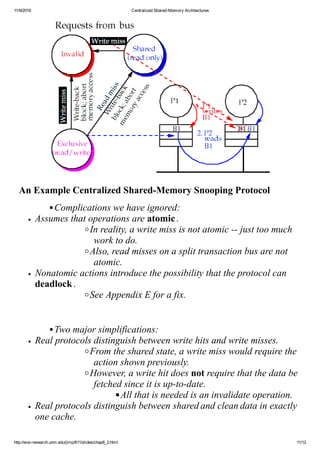


This document discusses centralized shared-memory architectures and cache coherence protocols. It begins by explaining how multiple processors can share memory through a shared bus and cached data. It then discusses the cache coherence problem that arises when caches contain replicated data. Write invalidate is introduced as the most common coherence protocol, where a write invalidates other caches' copies of the block. The implementation of write invalidate protocols with snooping and directory approaches is covered, focusing on supporting write-back caches through tracking shared state and bus snooping.









































































