



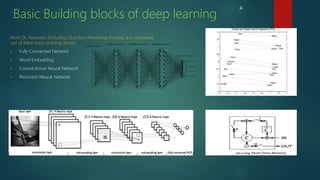
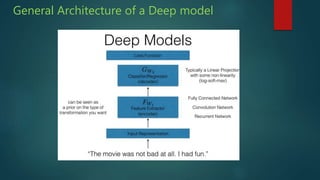



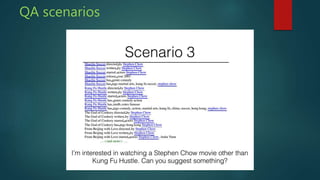














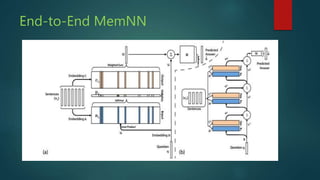
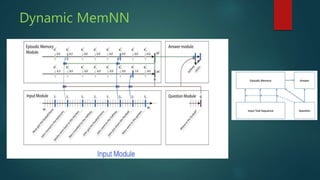
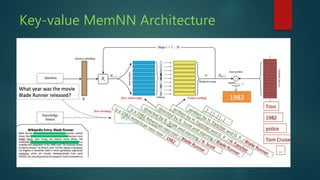





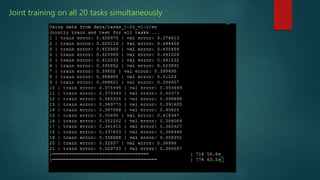
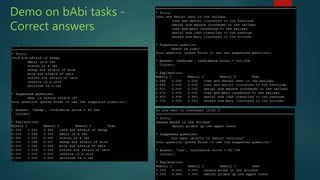
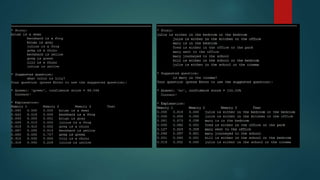
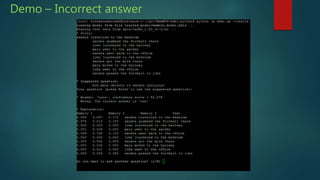



The presentation discusses deep learning and its application in question answering (QA) systems, focusing on the use of deep architectures such as memory networks that integrate learning with memory capabilities. It outlines the two primary types of traditional QA systems—information retrieval and knowledge-based systems—and highlights the shift towards models that can autonomously read documents and answer questions. Additionally, various datasets for training QA models are presented, along with future work aimed at improving memory networks and exploring their application in real-world scenarios.



![[KDD 2018 tutorial] End to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/kdd2018tutorialend-to-endgoal-orientedquestionansweringsystems-180821081440-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[246]QANet: Towards Efficient and Human-Level Reading Comprehension on SQuAD](https://cdn.slidesharecdn.com/ss_thumbnails/246qanetdeview2018-181012000849-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



