Downloaded 699 times



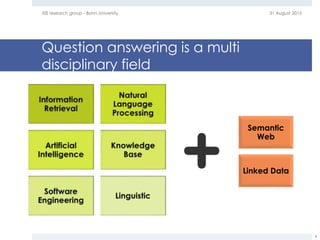

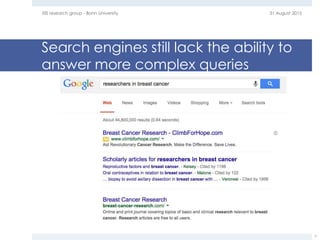
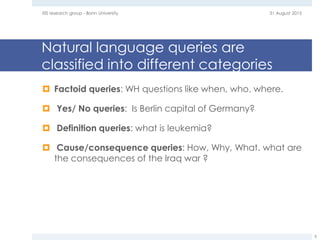





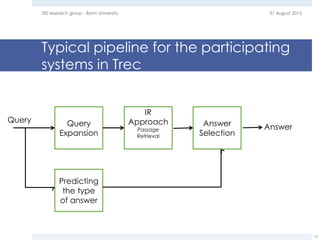

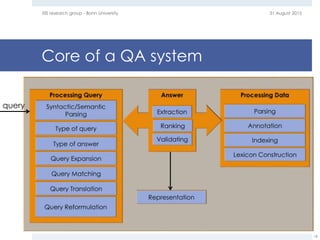

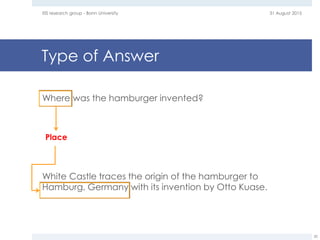




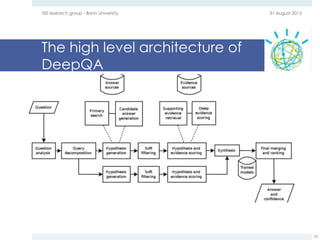
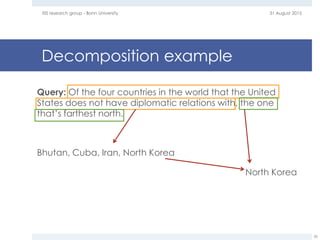
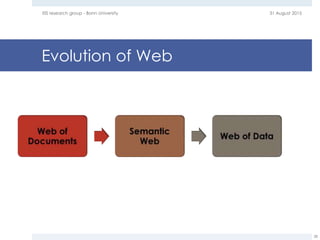


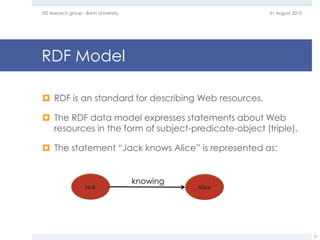

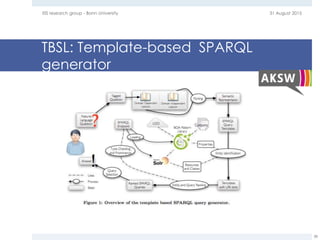
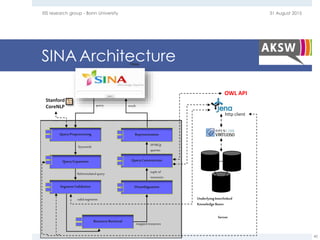


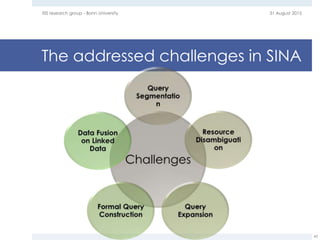
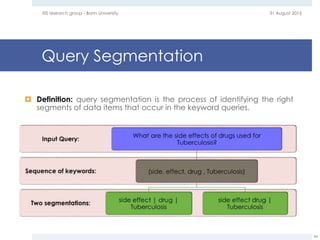

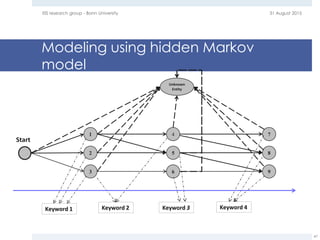


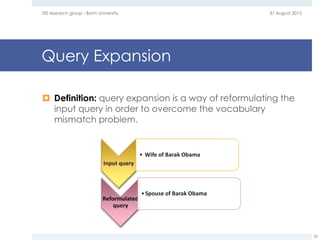
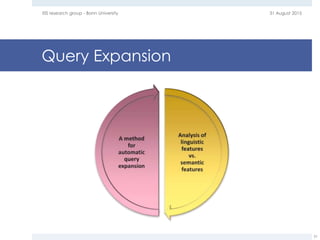



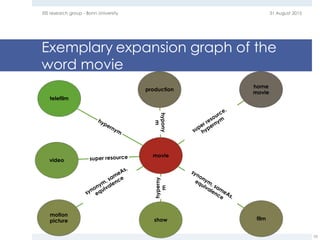

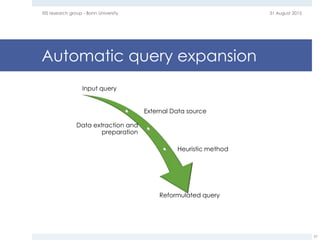
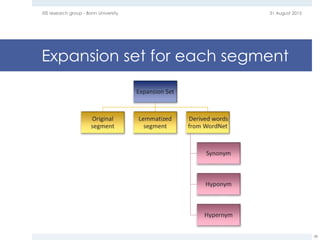
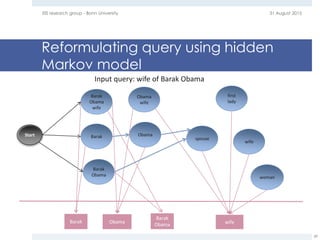



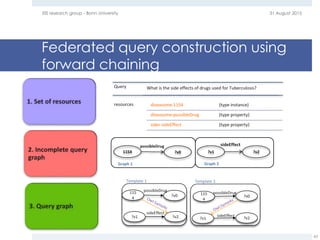

The document provides an overview of question answering systems, including their evolution from information retrieval, common evaluation benchmarks like TREC and CLEF, and examples of major QA projects like Watson. It also discusses the movement towards leveraging semantic technologies and linked open data to power next generation QA systems, as seen in projects like SINA which transform natural language queries into formal queries over structured knowledge bases.















































































