Download to read offline





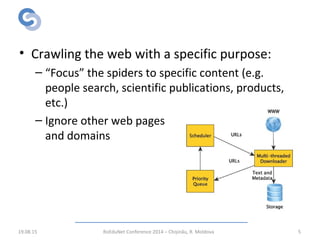

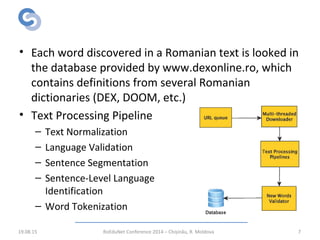





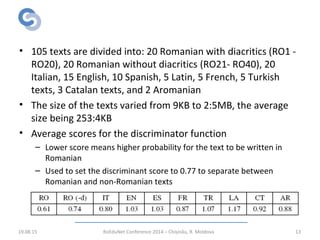

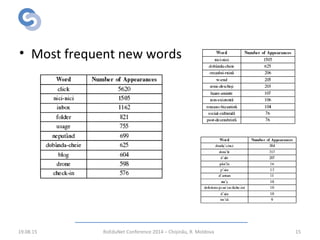



The document describes a focused web crawler called RWScraper that was developed to identify new Romanian words from web pages. RWScraper analyzes Romanian texts, distinguishes common nouns from proper names, and extracts new words along with context and metadata to a database. It implements text processing techniques like normalization, language identification, and word tokenization. The system was tested on over 264,000 documents and identified over 53,000 new words, many of which were misspellings, technical terms, or regionalisms. The authors conclude RWScraper provides a way to discover language evolution but could be improved with more accurate NLP and analysis of identified words.