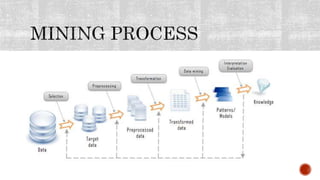
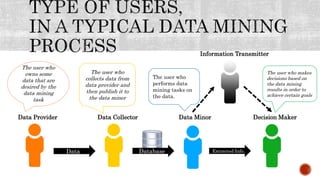
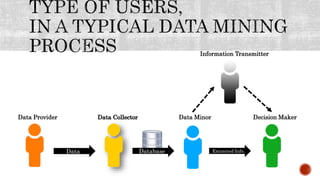
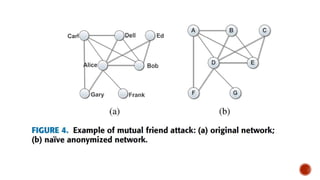
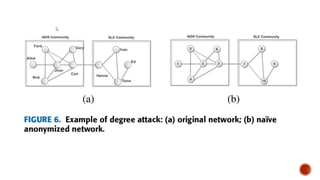
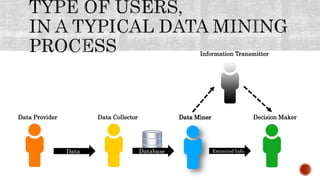
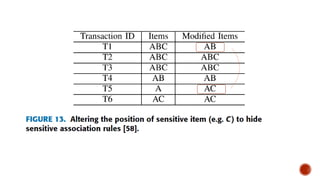
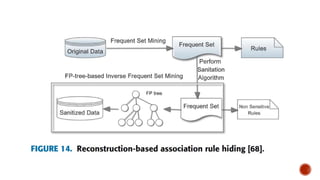
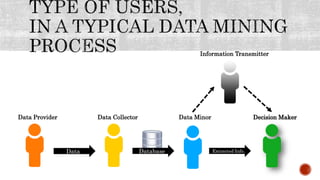
This document discusses the roles involved in data mining processes and privacy concerns. It describes the roles of data provider, data collector, data miner, and decision maker. For each role, it outlines their privacy concerns and approaches that can be used to address those concerns, such as limiting data access, anonymization techniques, and secure multi-party computation. The goal of privacy-preserving data mining is to protect sensitive information while still allowing for useful knowledge discovery from data.