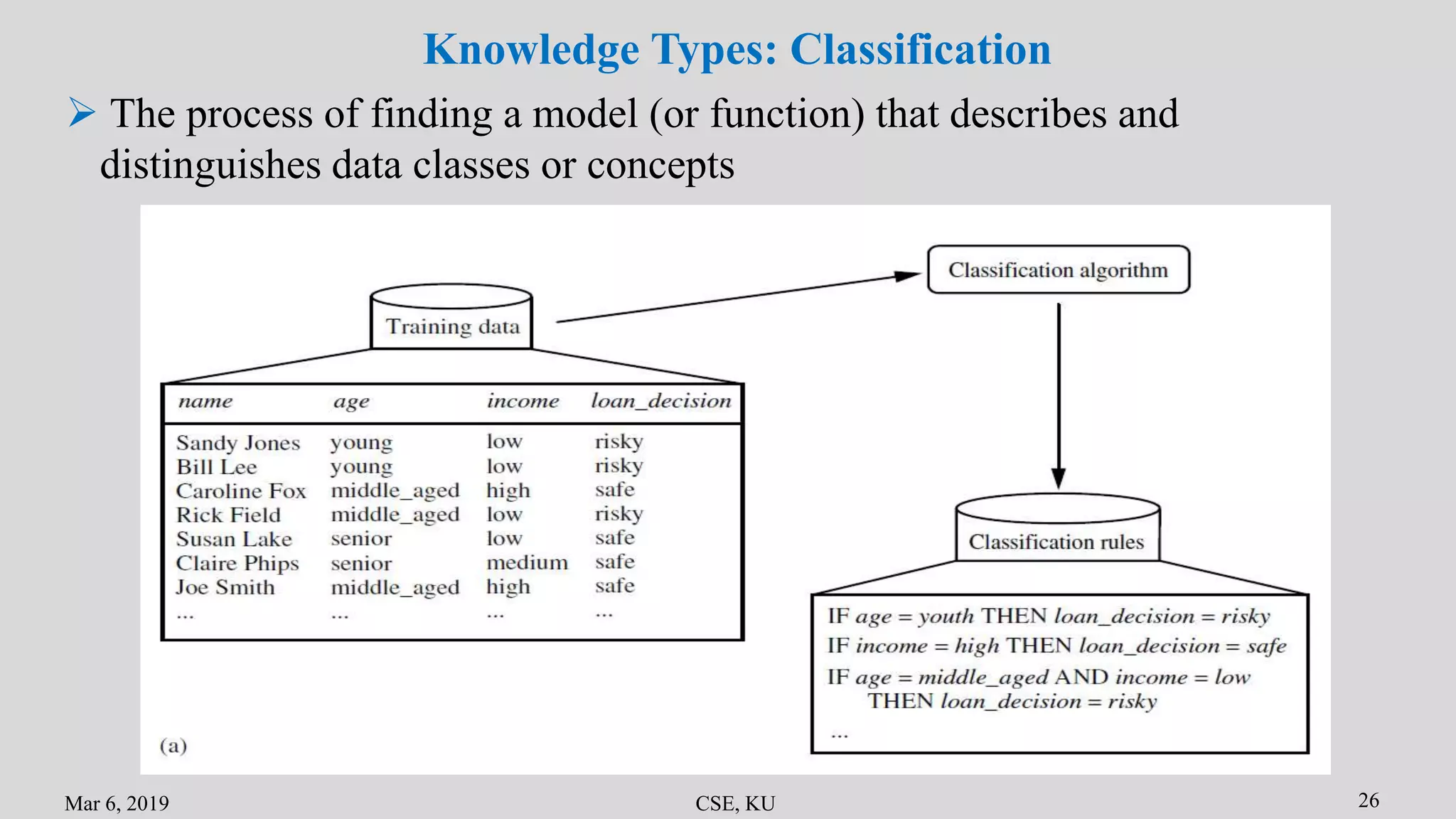
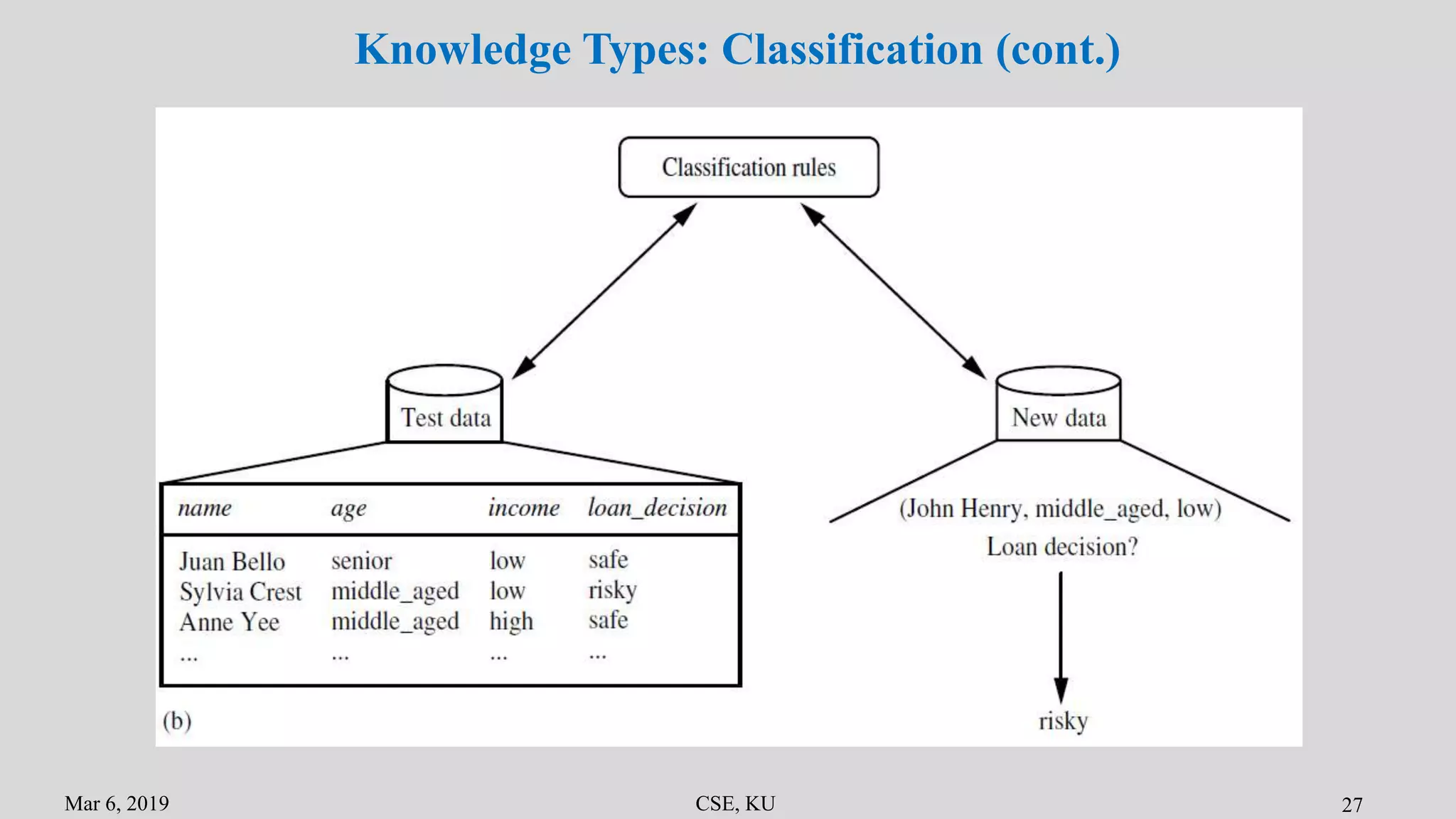
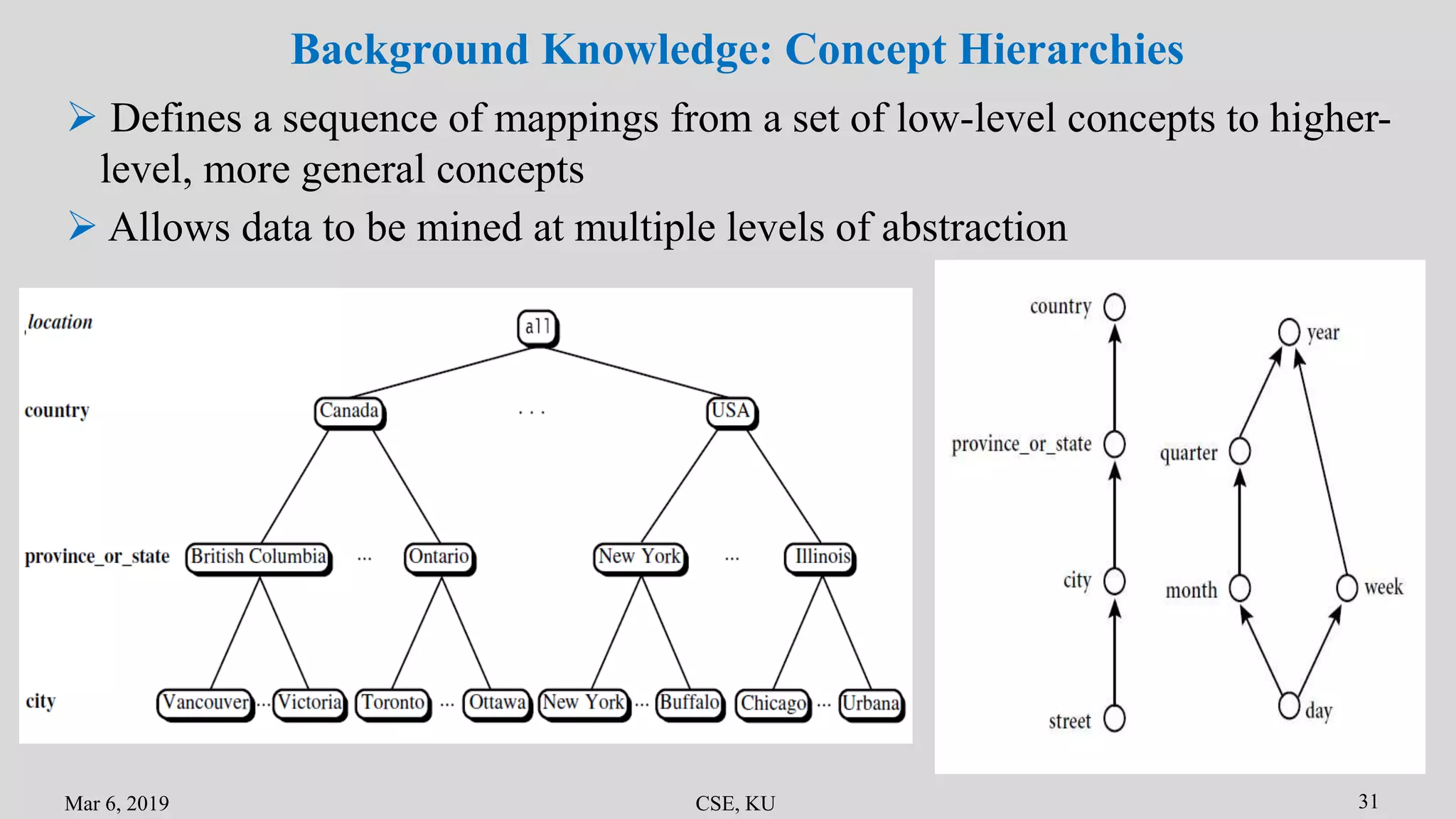
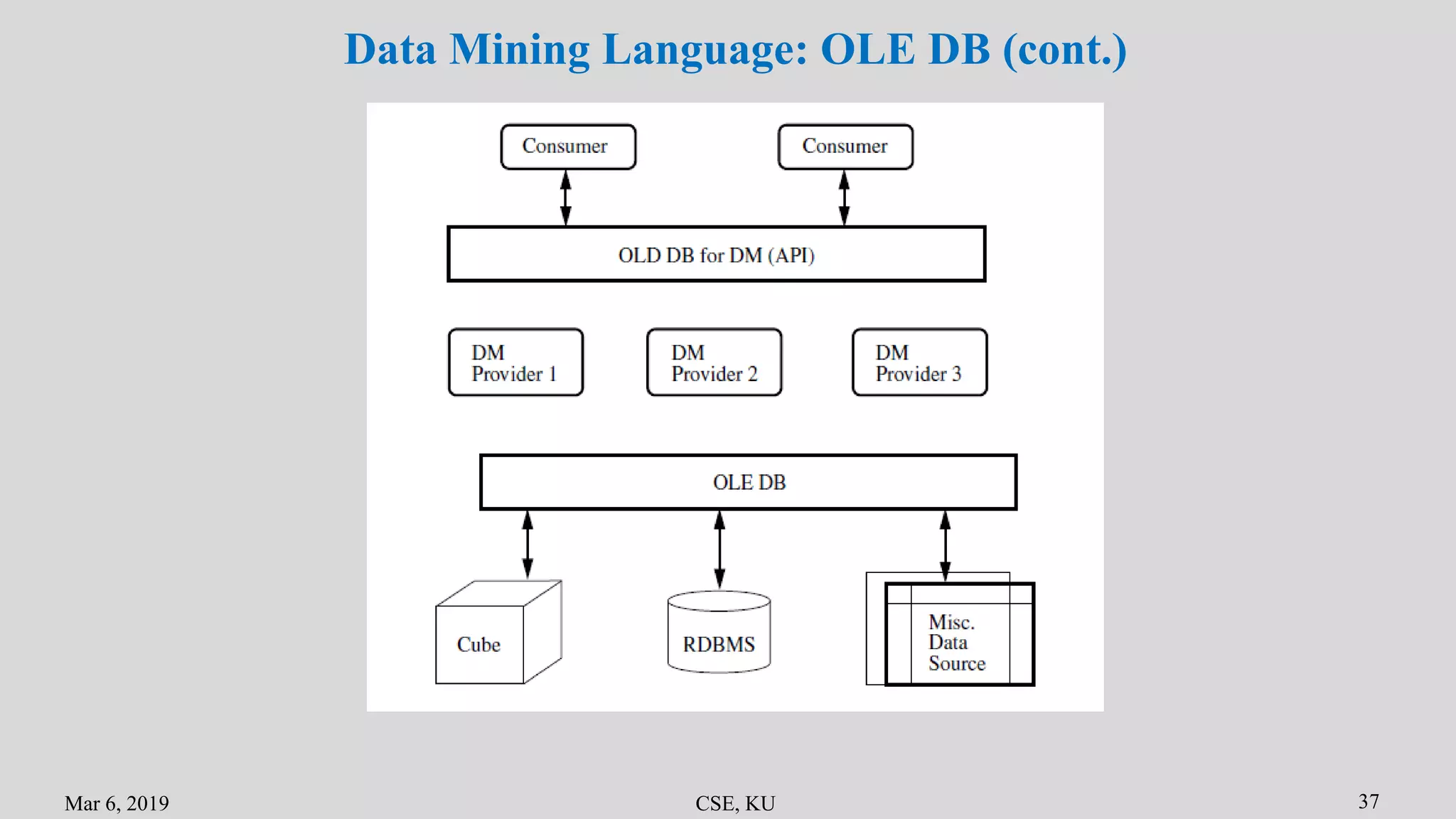
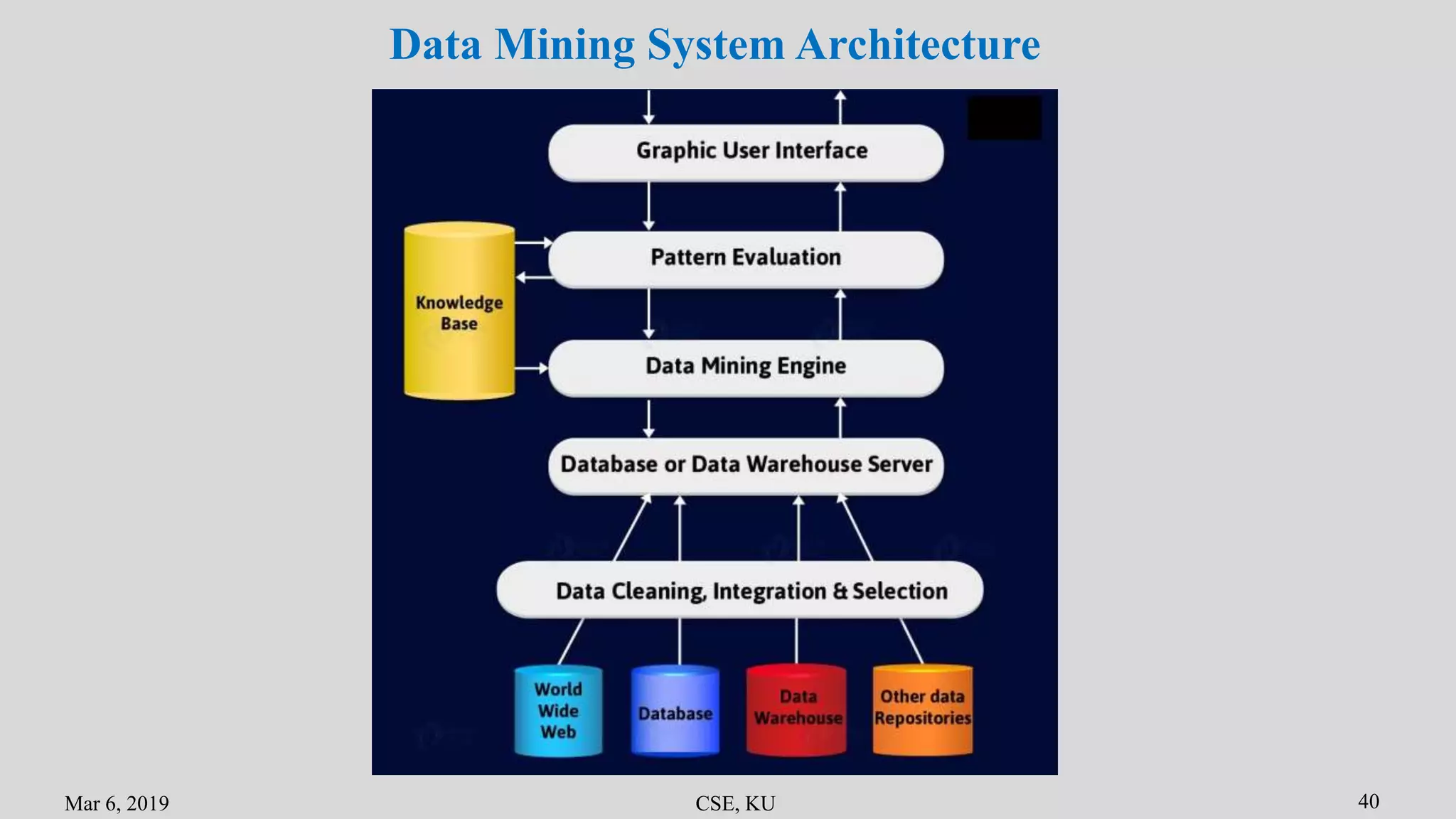
The document summarizes the key primitives and concepts in data mining. It discusses the main primitives as task-relevant data, knowledge types to be mined, and background knowledge. It describes various data mining techniques including data selection, grouping, characterization, discrimination, associations and correlations. It also discusses classification methods and prediction. Finally, it covers data mining system architectures and languages such as DMQL and OLE DB.
![Advanced Data Mining
Lec-4: Data Mining Primitives, Languages & Systems
[Class Presentation]
Presented by
Niloy Sikder
ID: MSc 190221
CSE Discipline
Khulna University, Khulna](https://image.slidesharecdn.com/admlec-4-190405082017/75/Data-Mining-Primitives-Languages-Systems-1-2048.jpg)
















![Mar 6, 2019 CSE, KU 24
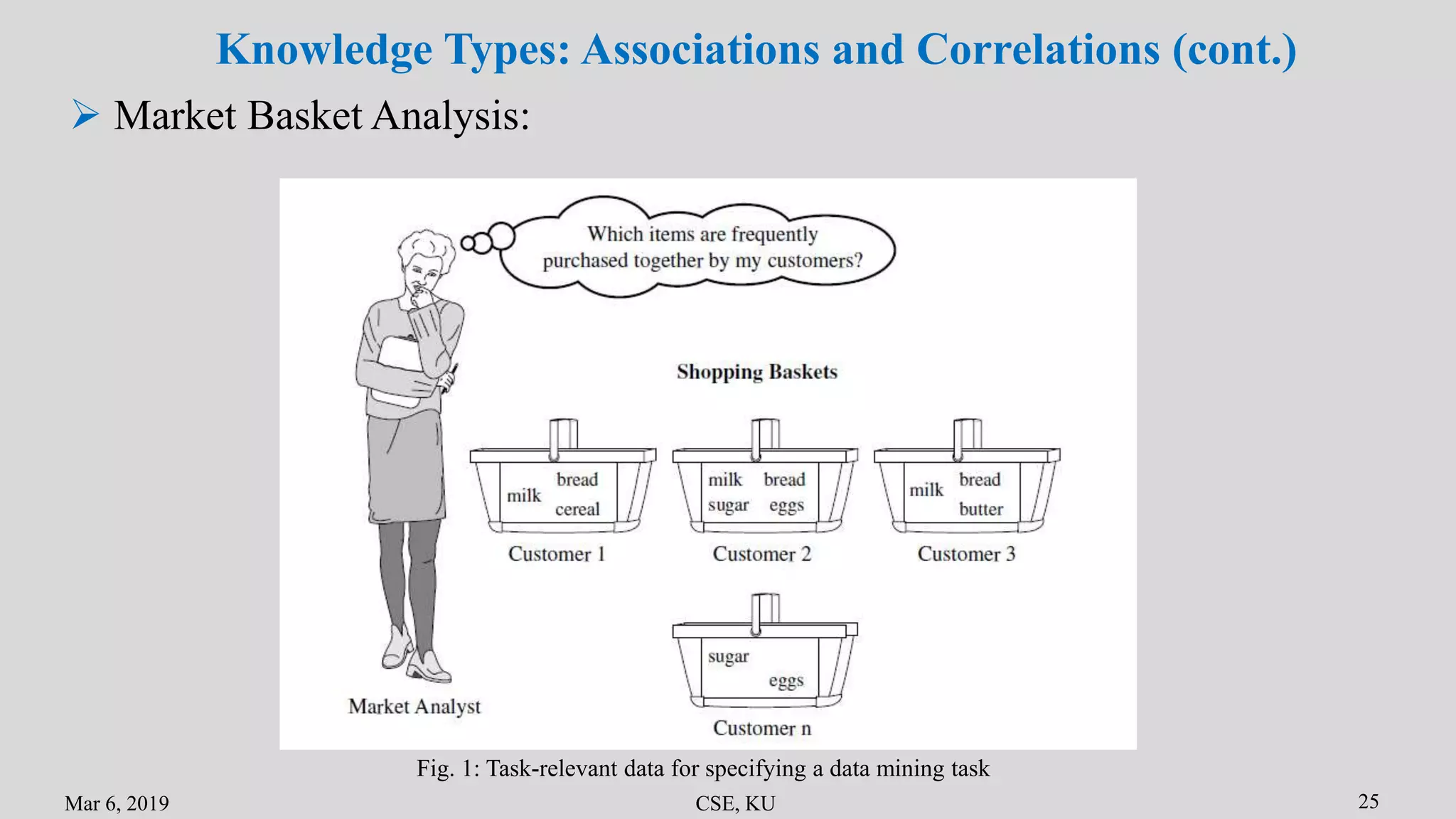
Knowledge Types: Associations and Correlations
Frequent patterns, are the patterns that occur frequently in data
buys(X; “computer”)) => buys(X; “software”) [support = 1%; confidence = 50%]
Mining frequent patterns leads to the discovery of interesting associations
and correlations within data
A frequent itemset refers to a set of items that frequently appear together in
a transactional data set
age(X, “20:::29”) ^ income(X, “20K:::29K”)) => buys(X, “CD player”) [support = 2%,
confidence = 60%]](https://image.slidesharecdn.com/admlec-4-190405082017/75/Data-Mining-Primitives-Languages-Systems-25-2048.jpg)













![References
[1] Data Mining: Concepts and Techniques Second Edition - Jiawei Han, Micheline Kamber
[2] Introduction to Data Mining - Tan Steinbach Kumar
[3] https://data-flair.training/blogs/data-mining-architecture/
[4] https://www.tutorialspoint.com/data_mining/dm_systems.htm](https://image.slidesharecdn.com/admlec-4-190405082017/75/Data-Mining-Primitives-Languages-Systems-45-2048.jpg)


















































































