Downloaded 23 times




















![Results: Cosine vs Euclidean
Cosine distance is a special case of Euclidean distance
𝑐𝑜𝑠_𝑑𝑖𝑠𝑡(𝑥, 𝑦) = 1 − 𝑐𝑜𝑠 𝑥, 𝑦 = 1 −
𝑖 𝑥𝑖 𝑦𝑖
𝑥 2 𝑦 2
=
𝐿2
2 𝑥
𝑥 2
,
𝑦
𝑦 2
2
Fast to compute for sparse vectors and ranges [0,1] for all-positive vectors popular in NLP](https://image.slidesharecdn.com/deeplearningatmacys-181030174916/75/Image-Based-E-Commerce-Product-Discovery-A-Deep-Learning-Case-Study-Denis-Kamotsky-Peter-Gazaryan-Macy-s-Inc-36-2048.jpg)




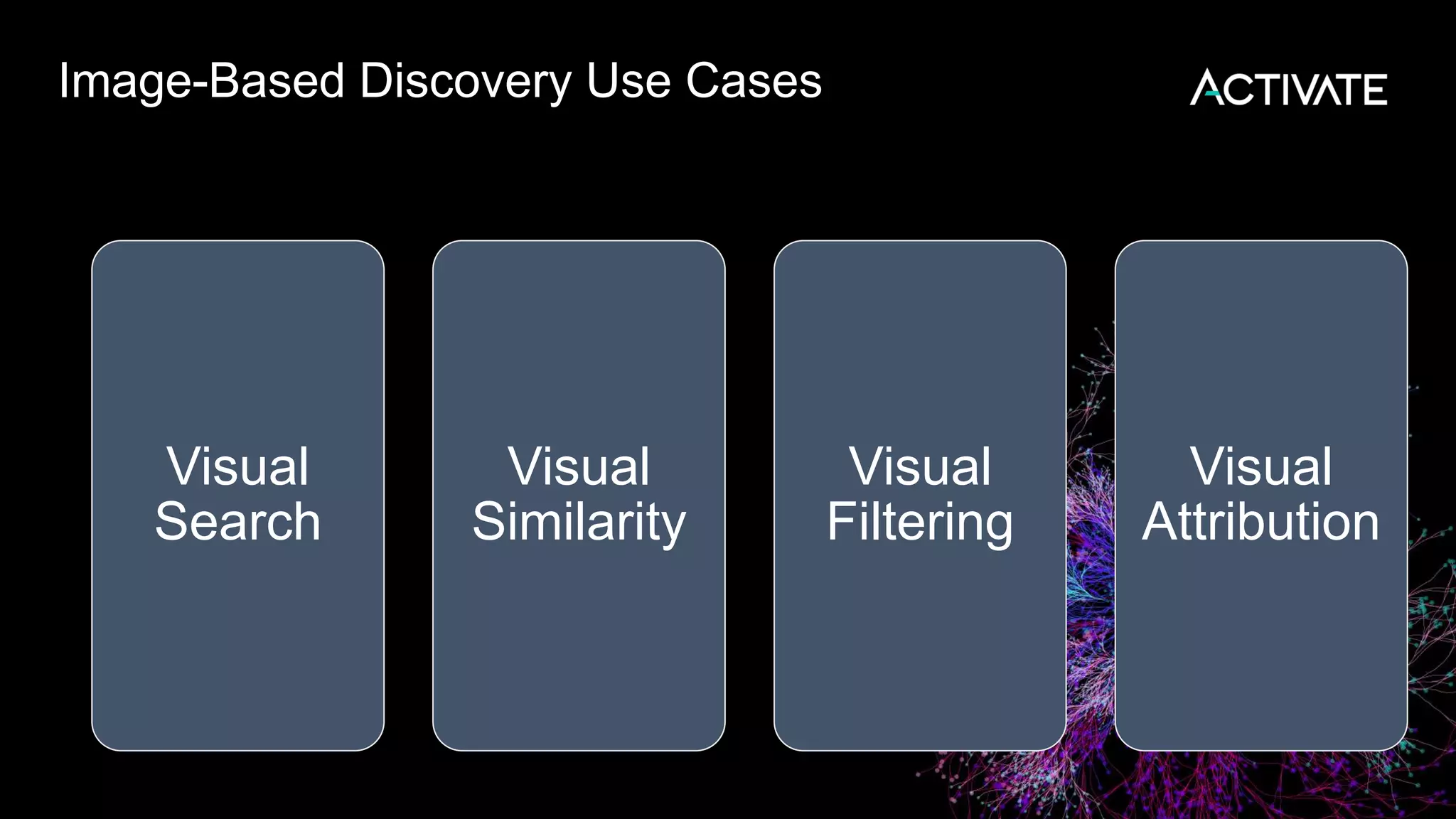
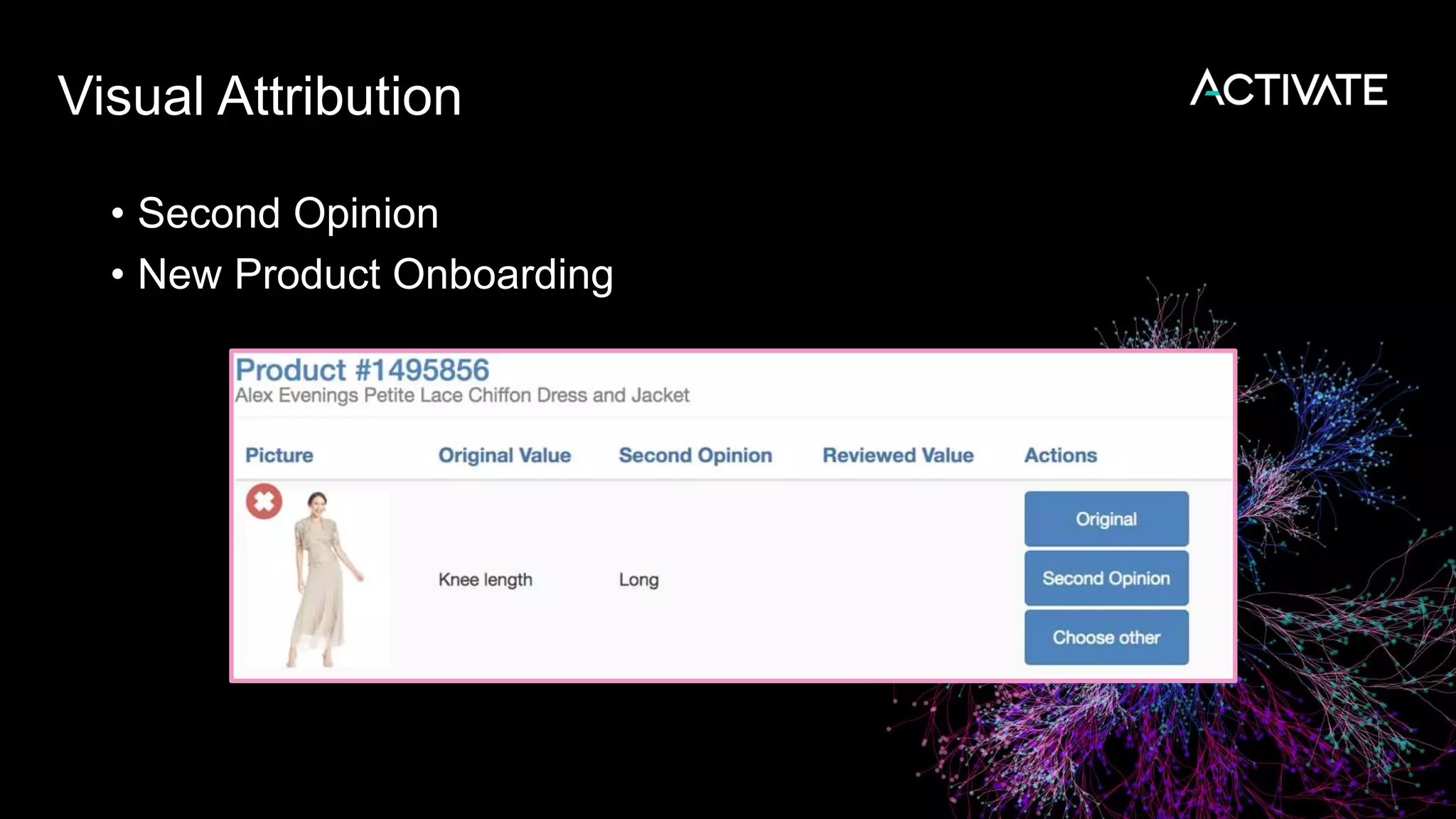
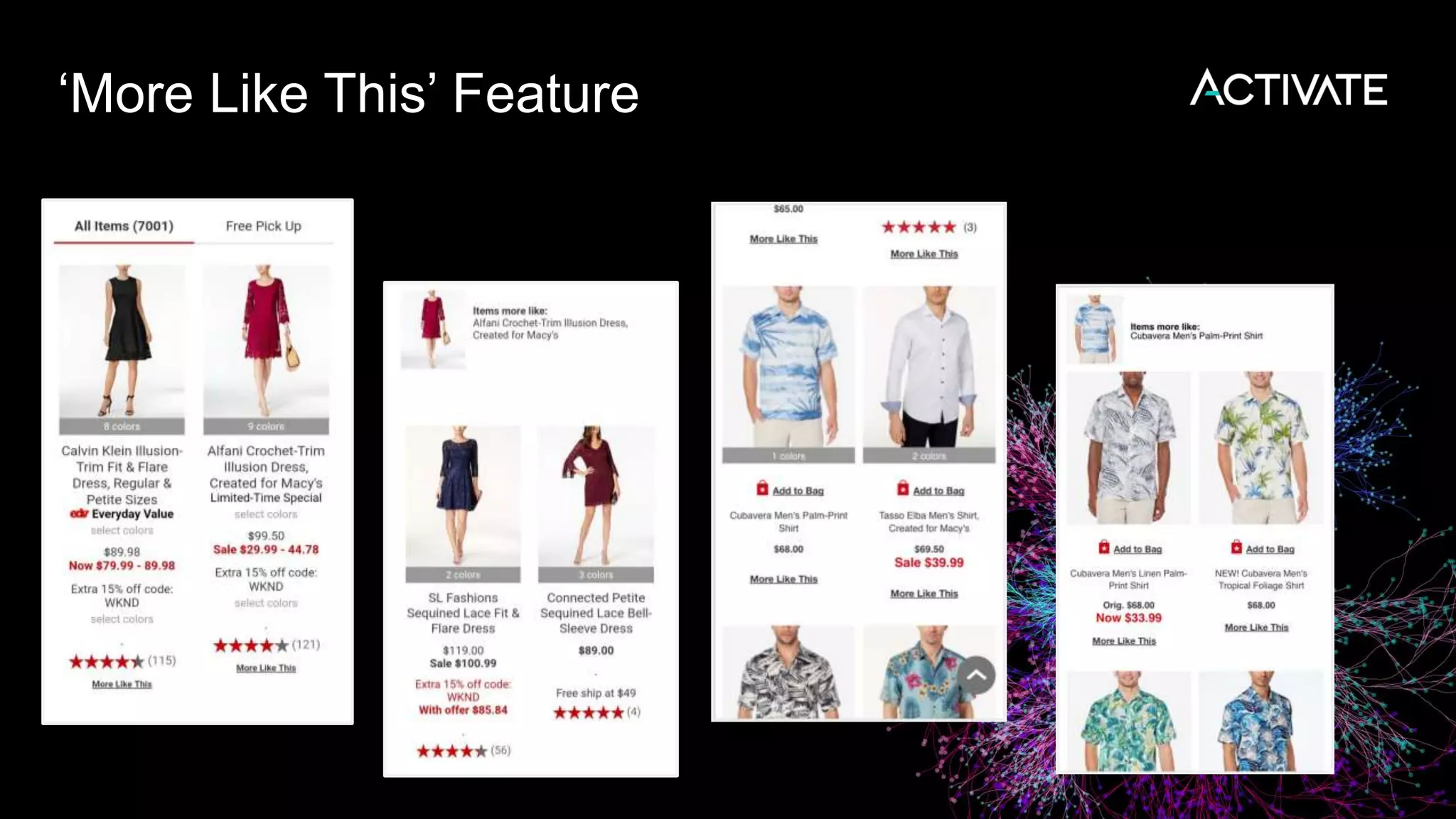
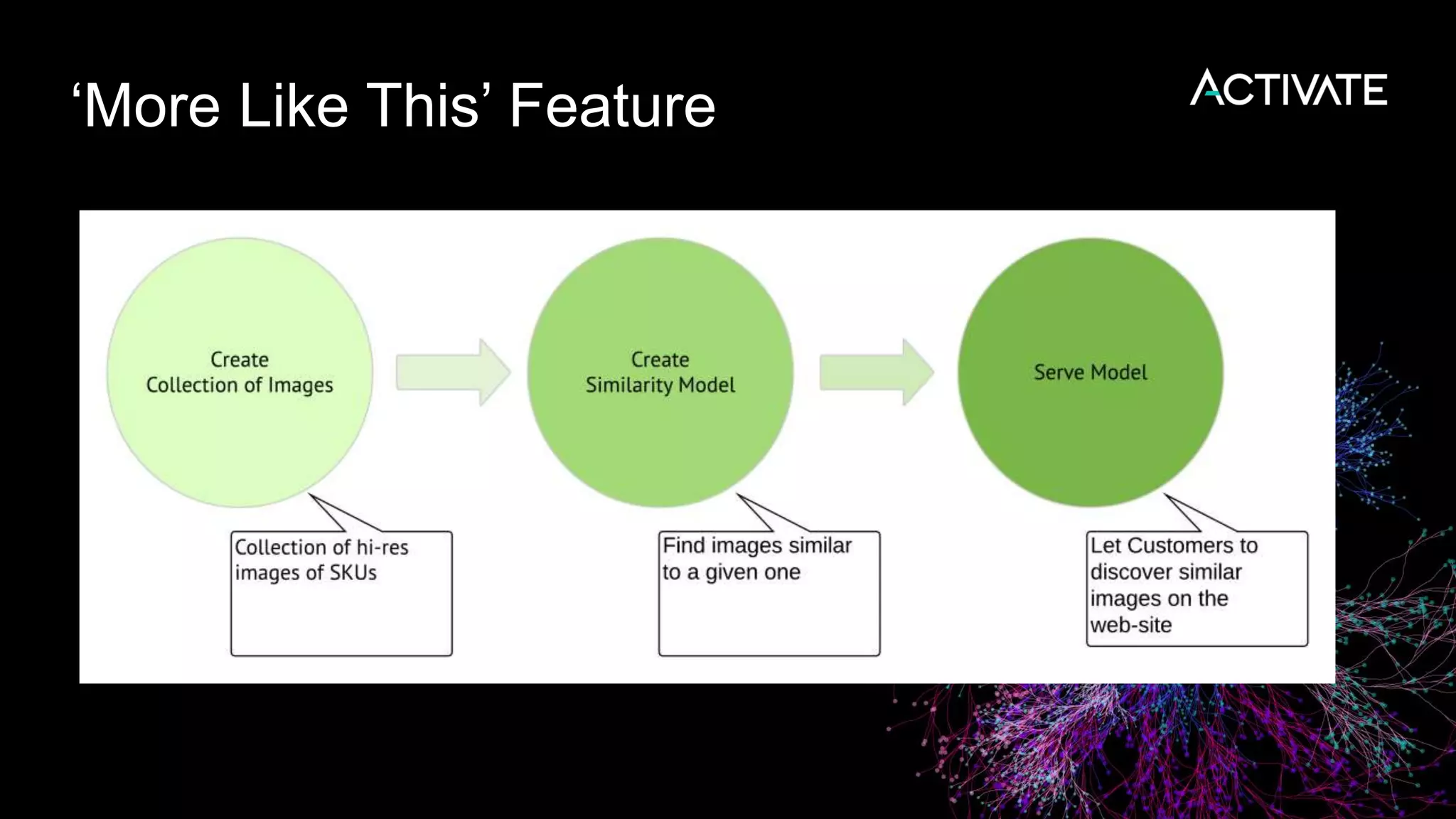
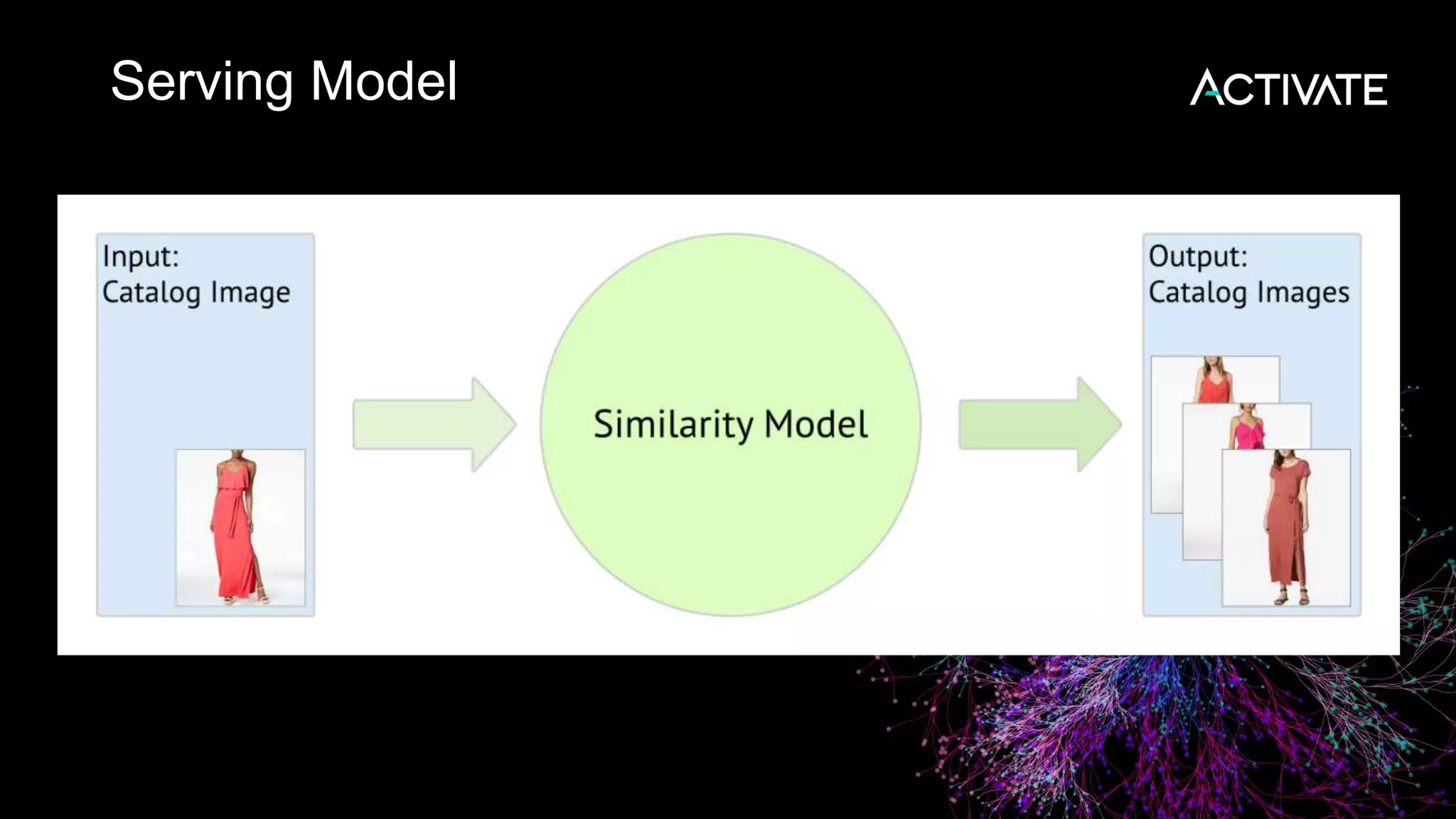
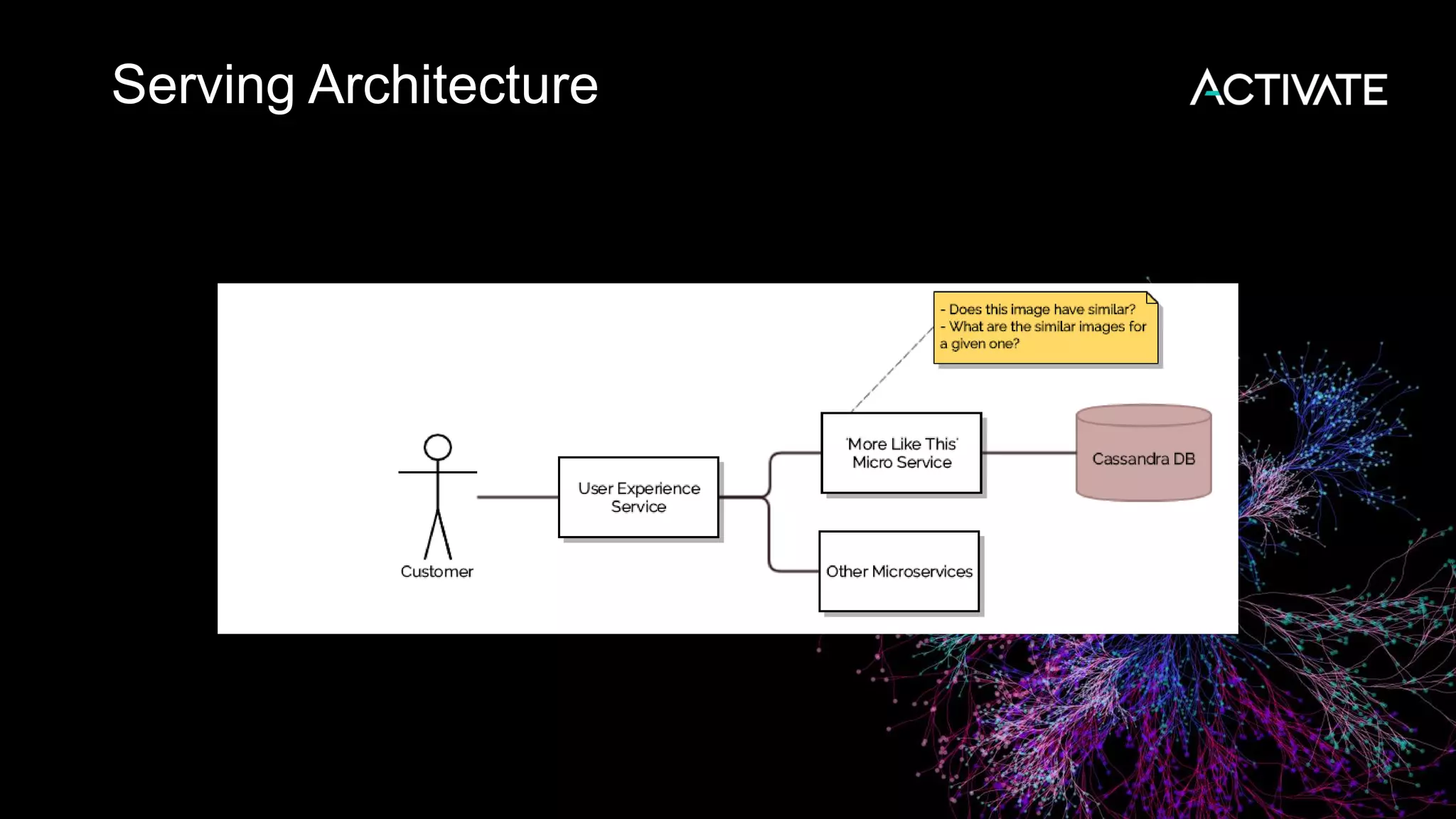
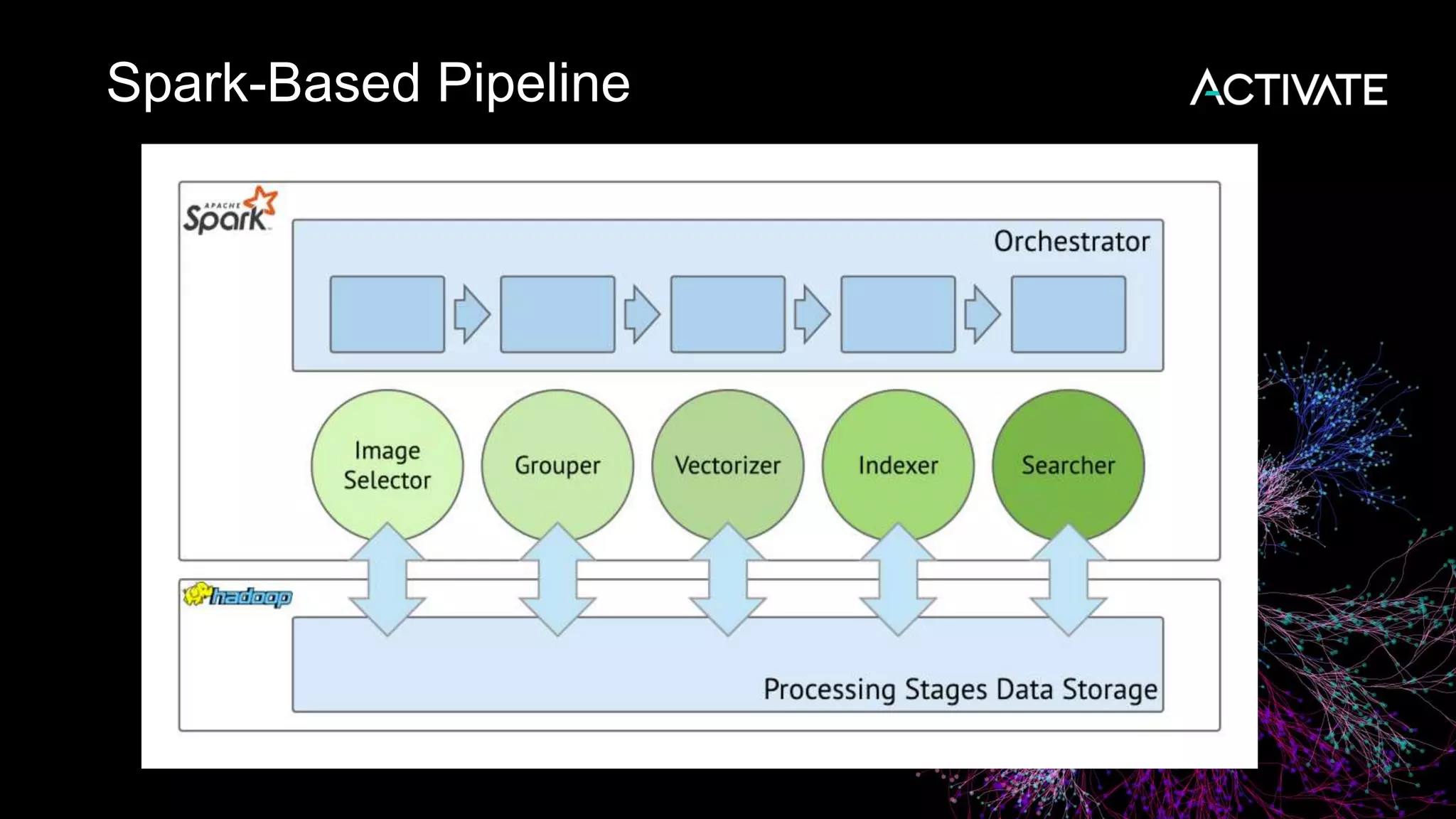
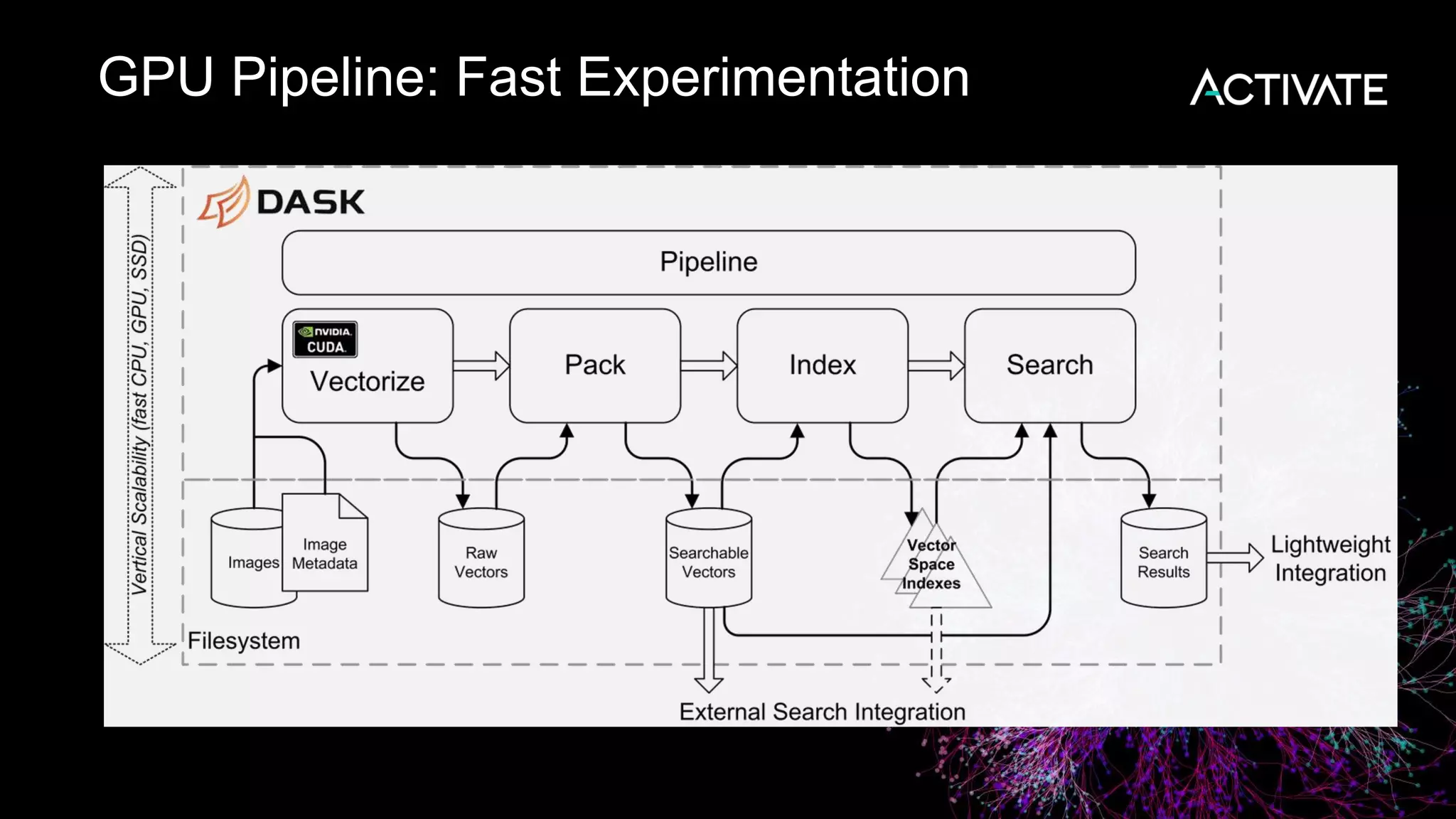
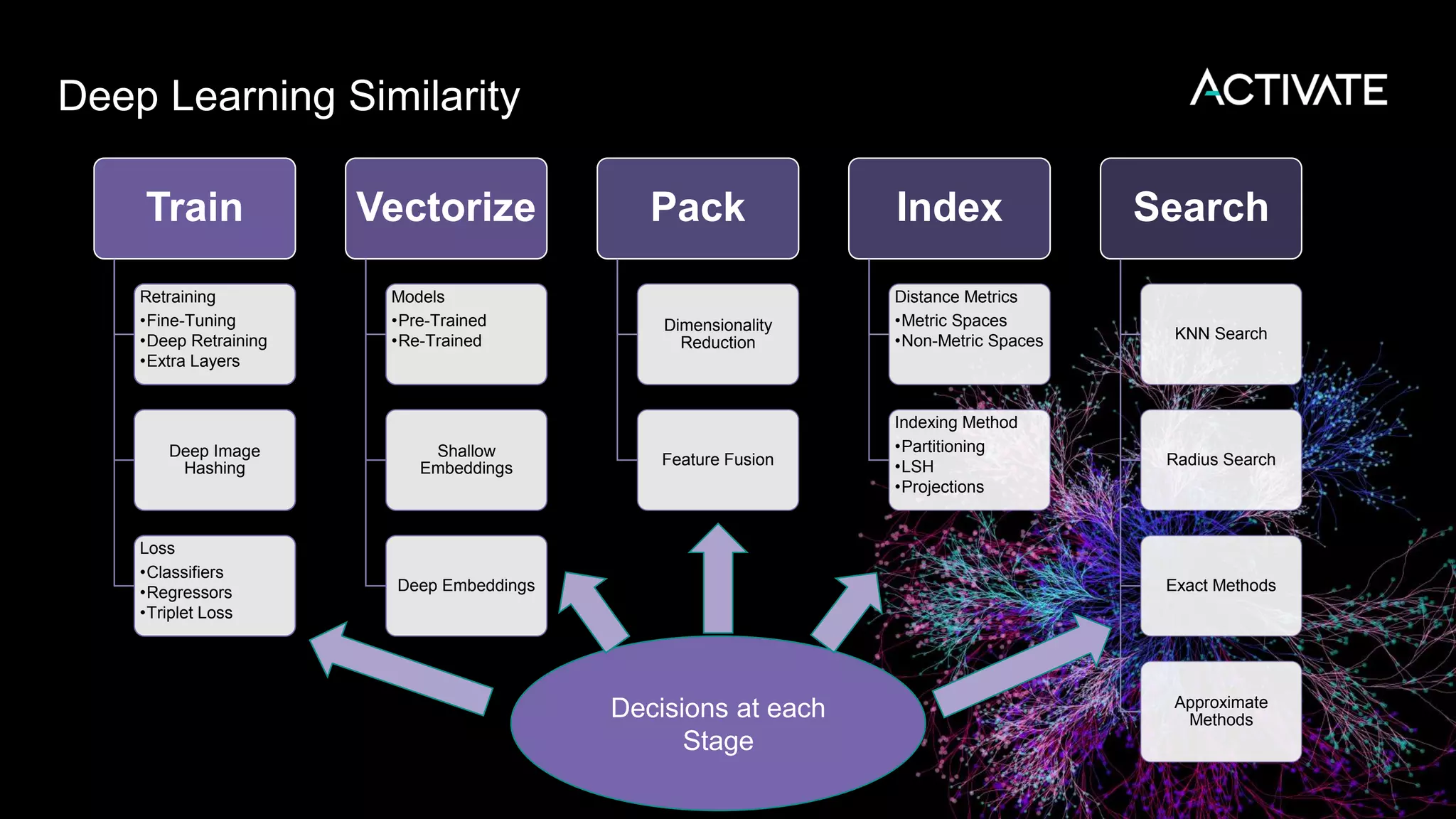
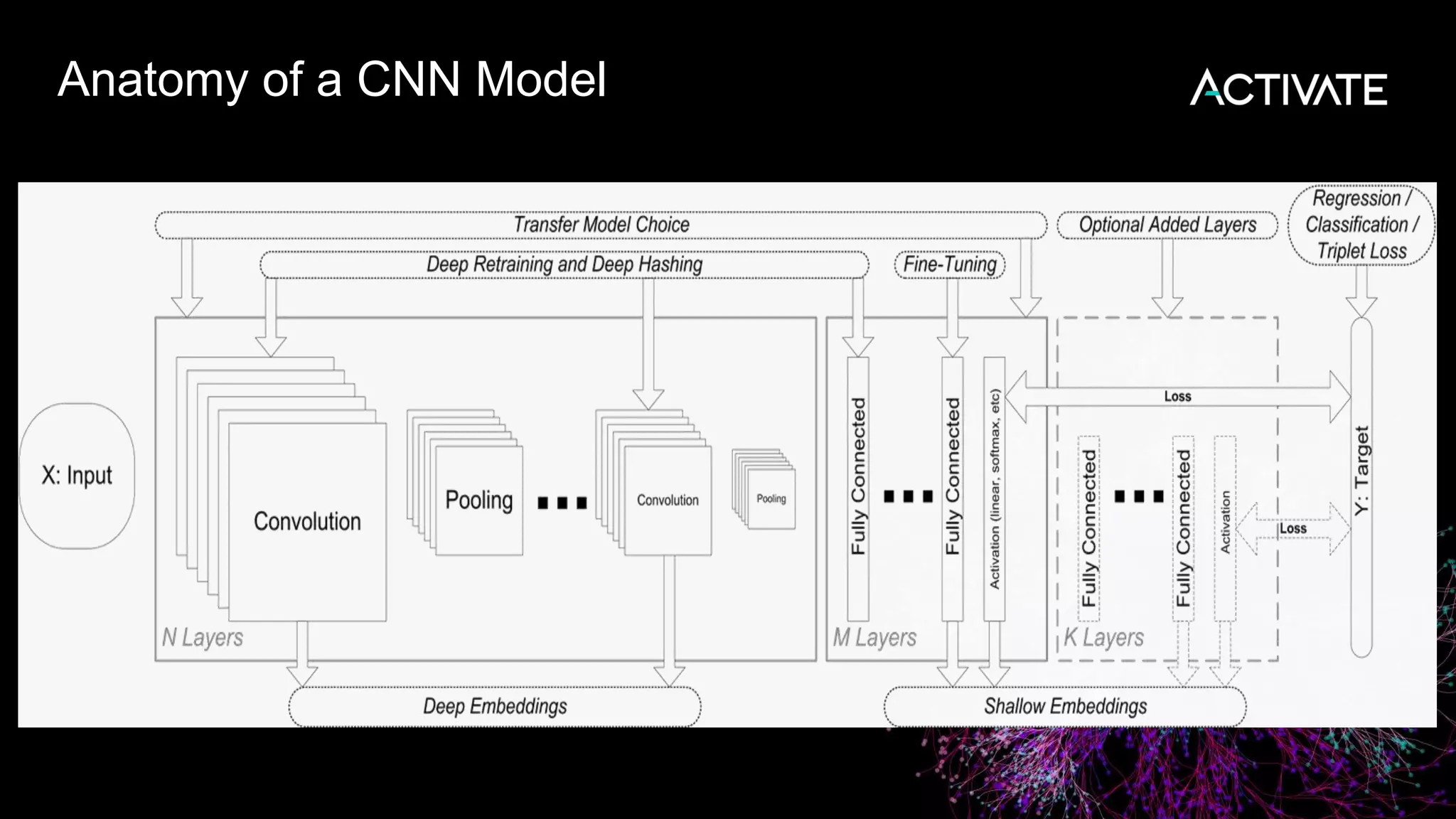
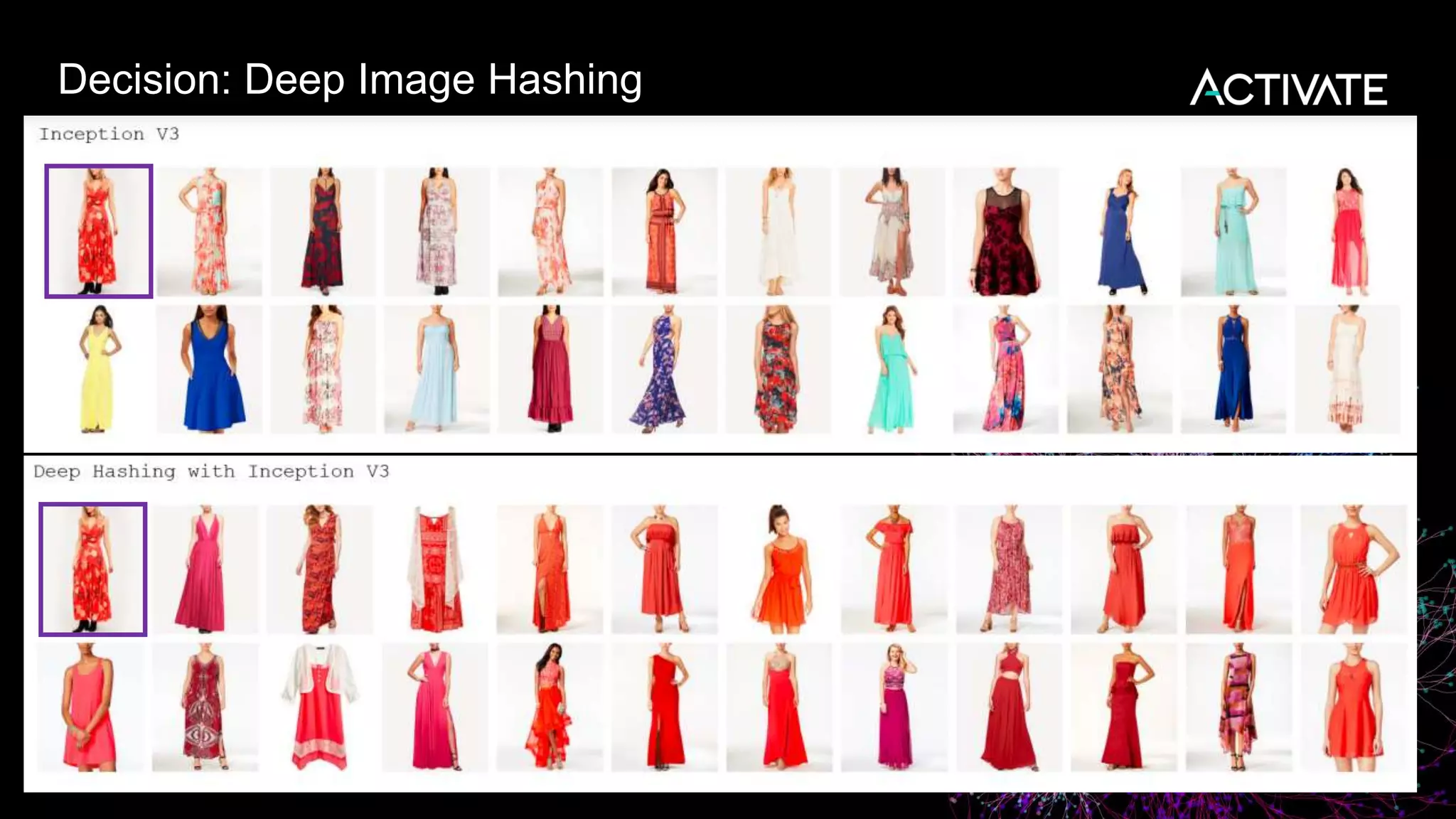
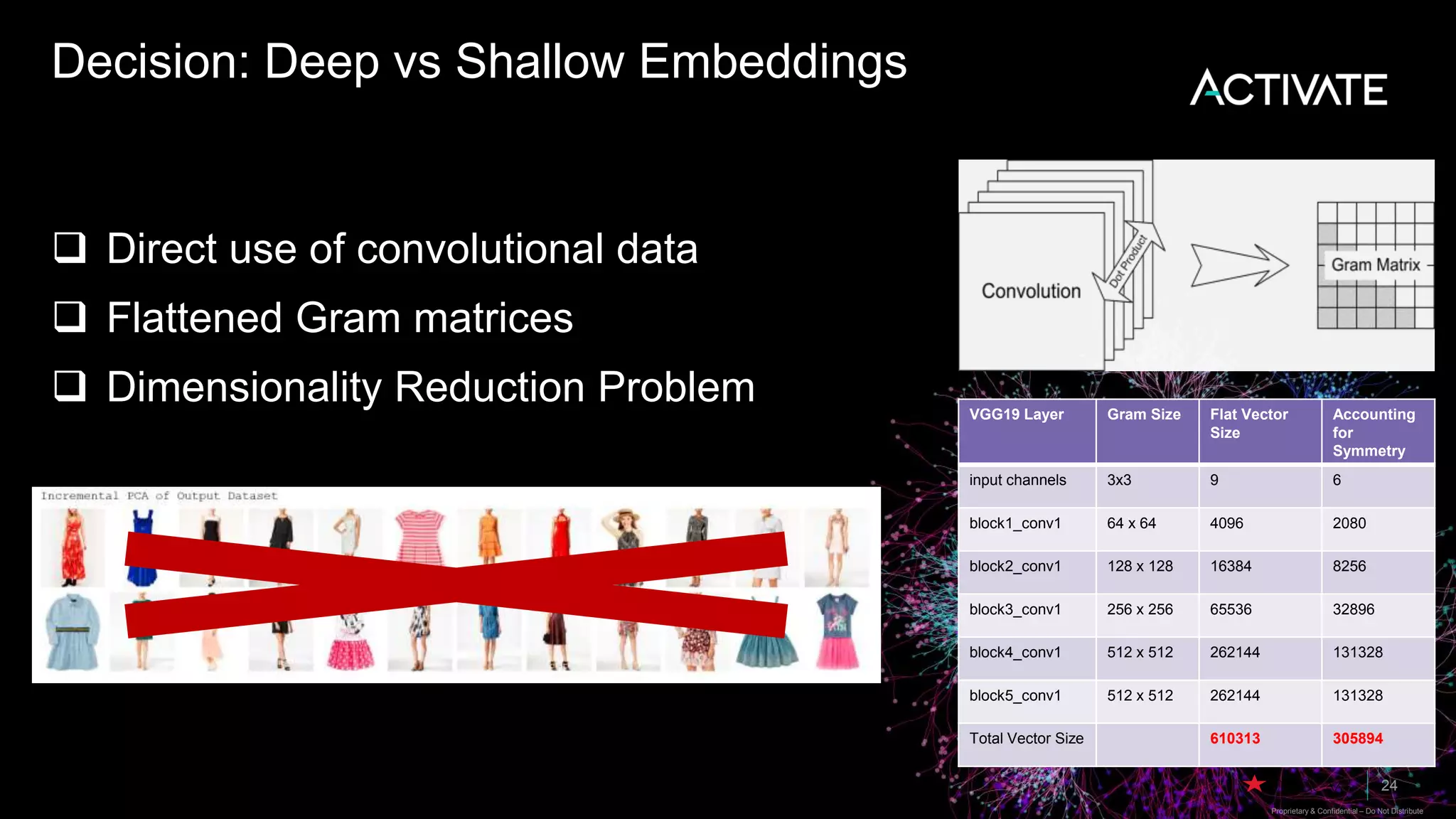
1) Macy's is launching an image-based "More Like This" deep learning feature to provide similar product recommendations to customers on their website. 2) The feature implementation uses transfer learning with pretrained models like MobileNet that are fine-tuned using a triplet loss approach and indexed in Lucene to support fast nearest neighbor search. 3) Engineering decisions around model architecture, embeddings, feature fusion, distance metrics, and indexing were required to deploy the solution at scale for Macy's large product catalog.













![[Lecture 2] AI and Deep Learning: Logistic Regression (Theory)](https://cdn.slidesharecdn.com/ss_thumbnails/lecture2-ink-180216131533-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[CVPR 2018] Visual Search (Image Retrieval) and Metric Learning](https://cdn.slidesharecdn.com/ss_thumbnails/cvpr2018imageretrieval-180817015945-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)















![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)




