Downloaded 19 times




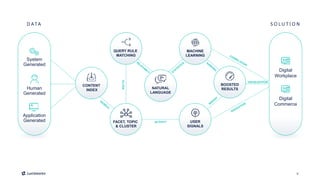

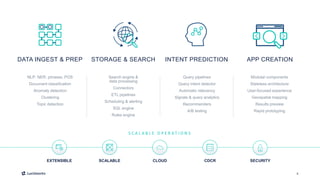




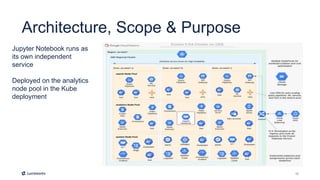
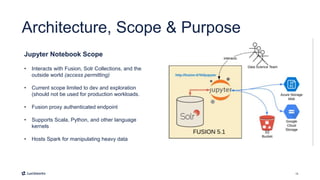
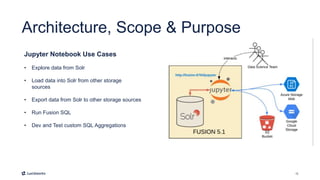

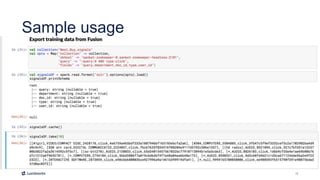

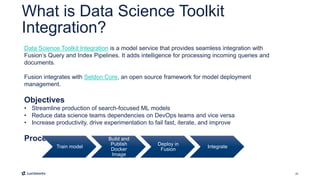
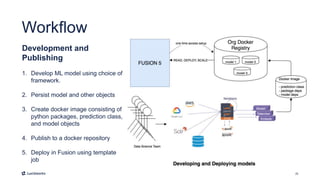
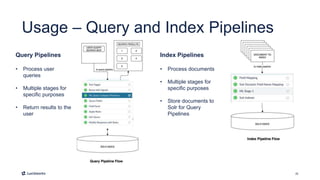
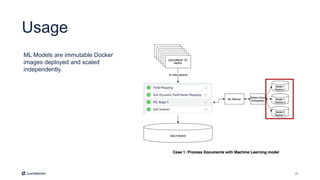
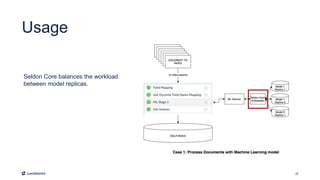
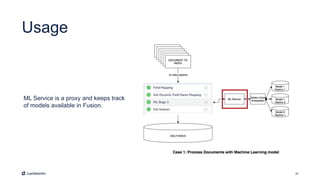
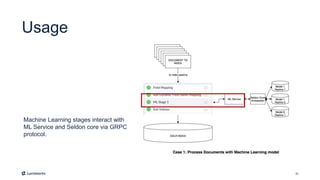
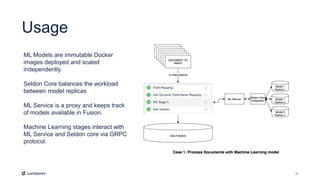





This document introduces Fusion 5.1 and its new capabilities for integrating with data science tools like Tensorflow, Scikit-Learn, and Spacy. It provides an overview of Fusion's capabilities for understanding content, users, and delivering insights at scale. The document then demonstrates Fusion's Jupyter Notebook integration for reading and writing data and running SQL queries. Finally, it shows how Fusion integrates with Seldon Core to easily deploy machine learning models with tools like Tensorflow and Scikit-Learn. A live demo is provided of deploying a custom model and using it in Fusion's query and indexing pipelines.


















































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)


























![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)









