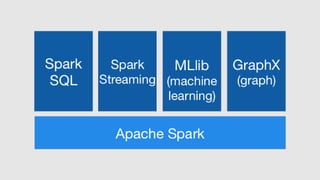
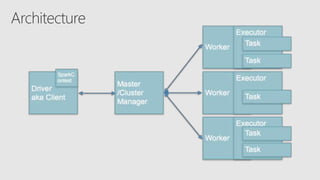
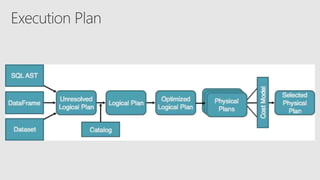
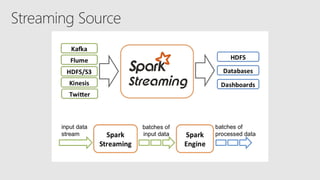
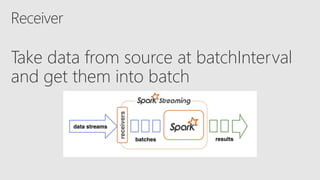
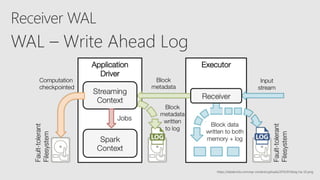
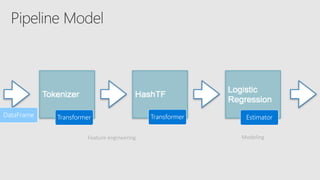
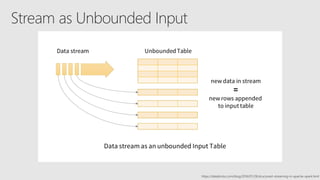
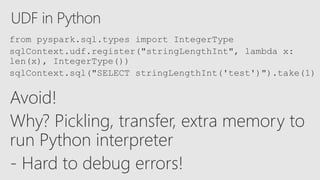
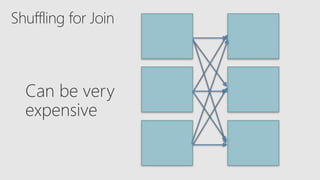
Starting with Apache Spark, Best Practices and Learning from the Field discusses optimizing Spark performance. It recommends using Parquet format for storage, avoiding UDFs, caching frequently used data, and checkpointing for streaming jobs. Predicate pushdown and broadcast joins can improve query performance. Structured streaming extends DataFrames to streams, enabling exactly-once processing with checkpointing.



















![Dataset[Row]
Partition = set of Row's](https://image.slidesharecdn.com/apachecon-startingwithapachesparkbestpractices-170520185427/85/Apache-Big-Data-Starting-with-Apache-Spark-Best-Practices-25-320.jpg)



















![Pattern matching
Mix pattern with SQL syntax
motifs = g.find("(a)-[e]->(b); (b)-
[e2]->(a); !(c)-[]->(a)").filter("a.id
= 'MIA'")](https://image.slidesharecdn.com/apachecon-startingwithapachesparkbestpractices-170520185427/85/Apache-Big-Data-Starting-with-Apache-Spark-Best-Practices-51-320.jpg)




















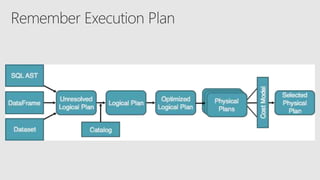
![Understanding Queries
explain() is your friend
but it could be hard to understand at
times == Parsed Logical Plan ==
Aggregate [count(1) AS count#79L]
+- Sort [speed_y#49 ASC], true
+- Join Inner, (speed_x#48 = speed_y#49)
:- Project [speed#2 AS speed_x#48, dist#3]
: +- LogicalRDD [speed#2, dist#3]
+- Project [speed#18 AS speed_y#49, dist#19]
+- LogicalRDD [speed#18, dist#19]](https://image.slidesharecdn.com/apachecon-startingwithapachesparkbestpractices-170520185427/85/Apache-Big-Data-Starting-with-Apache-Spark-Best-Practices-76-320.jpg)
![== Physical Plan ==
*HashAggregate(keys=[], functions=[count(1)], output=[count#79L])
+- Exchange SinglePartition
+- *HashAggregate(keys=[], functions=[partial_count(1)],
output=[count#83L])
+- *Project
+- *Sort [speed_y#49 ASC], true, 0
+- Exchange rangepartitioning(speed_y#49 ASC, 200)
+- *Project [speed_y#49]
+- *SortMergeJoin [speed_x#48], [speed_y#49], Inne
:- *Sort [speed_x#48 ASC], false, 0
: +- Exchange hashpartitioning(speed_x#48, 200
: +- *Project [speed#2 AS speed_x#48]
: +- *Filter isnotnull(speed#2)
: +- Scan ExistingRDD[speed#2,dist#3]
+- *Sort [speed_y#49 ASC], false, 0
+- Exchange hashpartitioning(speed_y#49, 200](https://image.slidesharecdn.com/apachecon-startingwithapachesparkbestpractices-170520185427/85/Apache-Big-Data-Starting-with-Apache-Spark-Best-Practices-78-320.jpg)

![UDF vs Builtin Example
Remember Predicate Pushdown?
val isSeattle = udf { (s: String) => s == "Seattle" }
cities.where(isSeattle('name))
*Filter UDF(name#2)
+- *FileScan parquet [id#128L,name#2] Batched: true, Format:
ParquetFormat, InputPaths: file:/Users/b/cities.parquet,
PartitionFilters: [], PushedFilters: [], ReadSchema:
struct<id:bigint,name:string>](https://image.slidesharecdn.com/apachecon-startingwithapachesparkbestpractices-170520185427/85/Apache-Big-Data-Starting-with-Apache-Spark-Best-Practices-80-320.jpg)
![UDF vs Builtin Example
cities.where('name === "Seattle")
*Project [id#128L, name#2]
+- *Filter (isnotnull(name#2) && (name#2 = Seattle))
+- *FileScan parquet [id#128L,name#2] Batched: true, Format:
ParquetFormat, InputPaths: file:/Users/b/cities.parquet,
PartitionFilters: [], PushedFilters: [IsNotNull(name),
EqualTo(name,Seattle)], ReadSchema:
struct<id:bigint,name:string>](https://image.slidesharecdn.com/apachecon-startingwithapachesparkbestpractices-170520185427/85/Apache-Big-Data-Starting-with-Apache-Spark-Best-Practices-81-320.jpg)



![BroadcastHashJoin
left.join(right, Seq("id"), "leftanti").explain
== Physical Plan ==
*BroadcastHashJoin [id#50], [id#60], LeftAnti,
BuildRight
:- LocalTableScan [id#50, left#51]
+- BroadcastExchange
HashedRelationBroadcastMode(List(cast(input[0, int,
false] as bigint)))
+- LocalTableScan [id#60]](https://image.slidesharecdn.com/apachecon-startingwithapachesparkbestpractices-170520185427/85/Apache-Big-Data-Starting-with-Apache-Spark-Best-Practices-87-320.jpg)
































































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Sumarac - Real-World Applications of Computer Vision in...](https://cdn.slidesharecdn.com/ss_thumbnails/fiksms22smcpopvvld03-jovan-sumarac-real-life-applications-of-computer-vision-in-automotive-systems-260120105855-de622abb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)

