Downloaded 37 times



















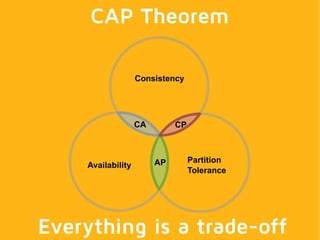




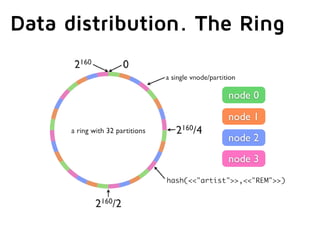






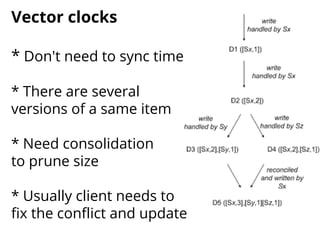



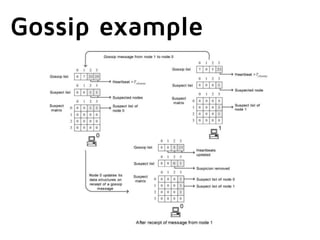


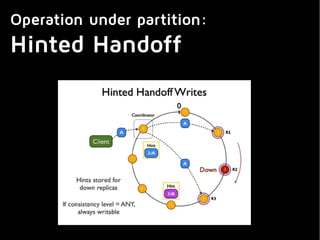









This document summarizes key aspects of distributed databases. It discusses master-slave and multi-master replication approaches. It then covers the challenges of achieving availability, partition tolerance and consistency as defined by Brewer's CAP theorem. The rest of the document dives deeper into data distribution, replication, conflict resolution, membership protocols, and allowing the system to operate during network partitions or node failures. It provides examples of gossip protocols, vector clocks, hinted handoff, and anti-entropy processes used in distributed databases. Finally, it notes that building these systems requires clients to be aware of some internal workings and allows for extra credit in building your own distributed database.




































































































