Downloaded 124 times




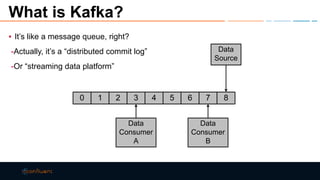

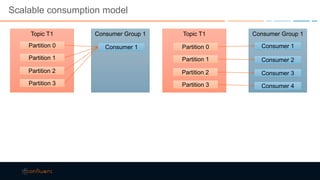

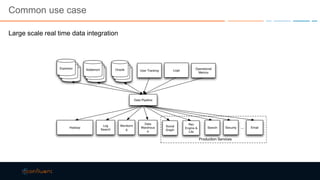




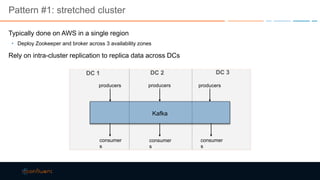
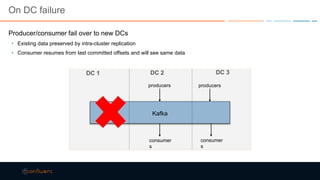
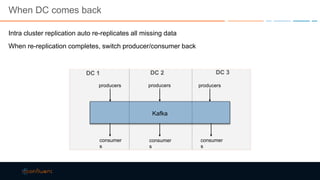

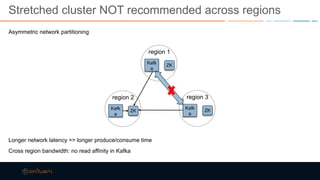
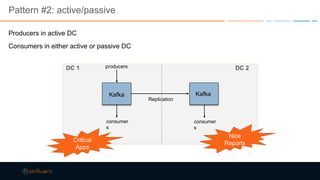

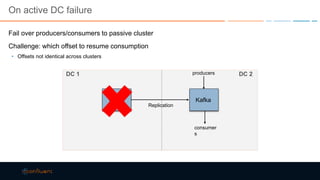

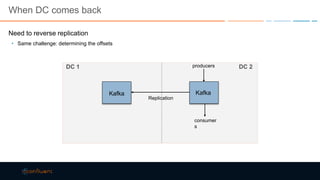

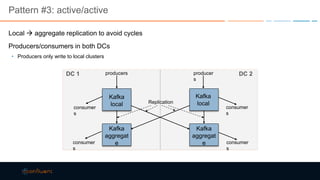
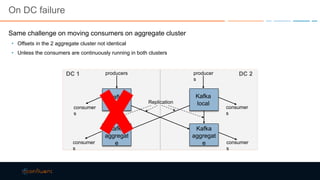
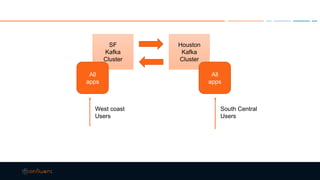
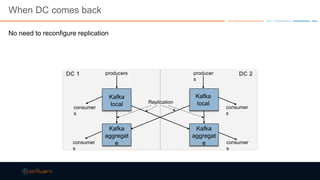
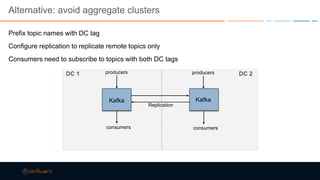
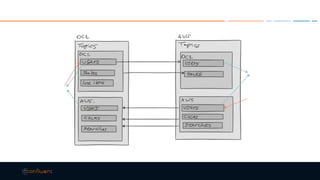

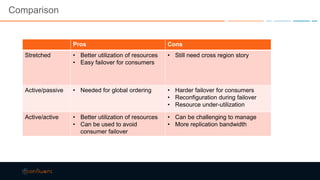
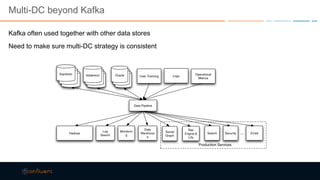

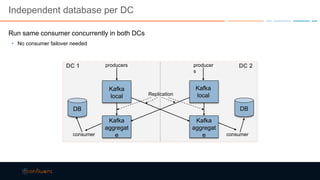
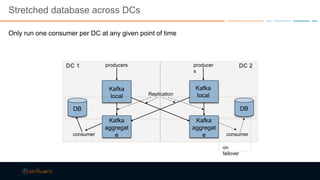





This document discusses strategies for building large-scale stream infrastructures across multiple data centers using Apache Kafka. It outlines common multi-data center patterns like stretched clusters, active/passive clusters, and active/active clusters. It also covers challenges like maintaining ordering and consumer offsets across data centers and potential solutions.























































































