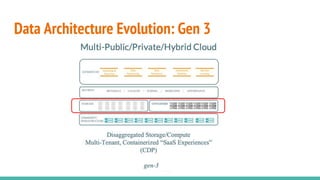
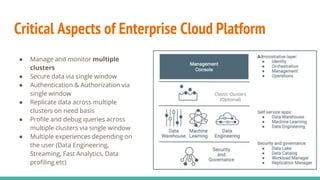
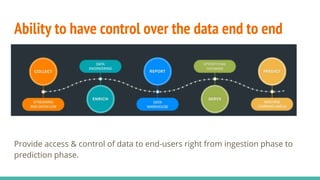
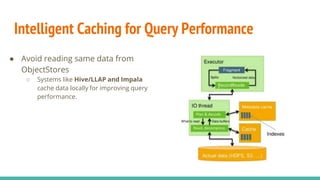
The document discusses the migration of big data workloads to cloud platforms, highlighting advantages such as scalable, cost-effective access to data storage and compute resources. It addresses challenges faced in cloud environments including consistency, latency, autoscaling, and security, while emphasizing the need for an open data architecture without vendor lock-in. The speakers advocate for the evolution of data architecture and the role of open-source solutions in facilitating enterprise-ready cloud platforms.



















![K8S: Pods can have same hostname/port
● Pods can have same hostname/port after restart
● This causes trouble for processes tracking nodes based on
hostname/port
● Added flexibility in the stack to take care of this situation
○ E.g TEZ-4179: [Kubernetes] Extend NodeId in tez to support unique worker identity](https://image.slidesharecdn.com/bigdataoncloudnativeplatform2-201214070238/85/Big-Data-on-Cloud-Native-Platform-24-320.jpg)































![Paul Dix [InfluxData] | InfluxDays Opening Keynote | InfluxDays Virtual Exper...](https://cdn.slidesharecdn.com/ss_thumbnails/2020-11-10influxdays-introducinginfluxdbiox-201110182839-thumbnail.jpg?width=640&height=640&fit=bounds)








































