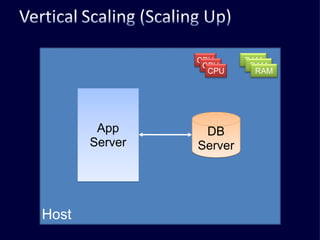
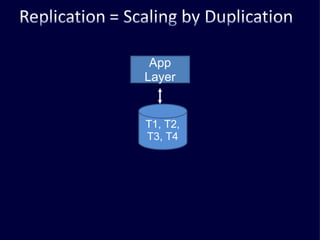
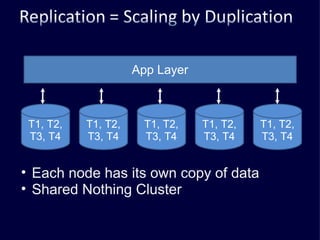
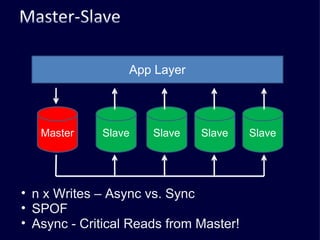
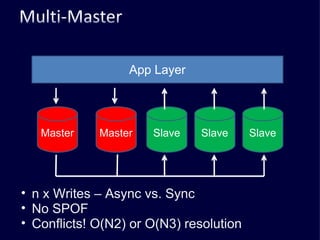
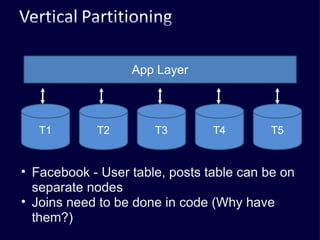
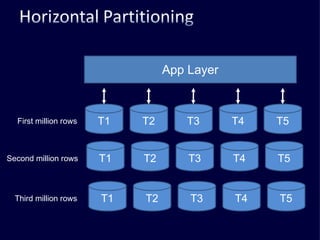
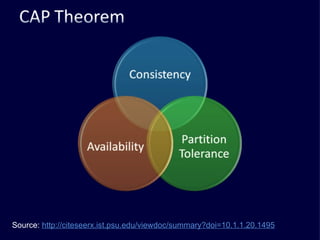
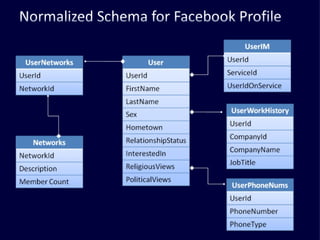
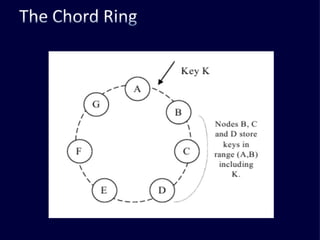
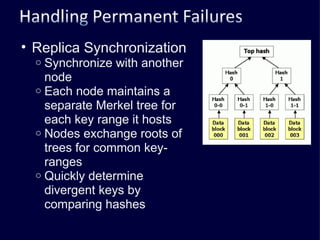
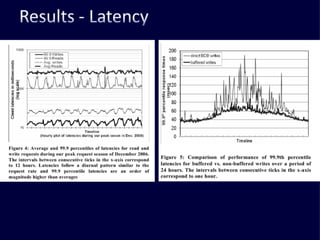
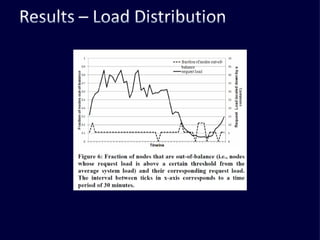
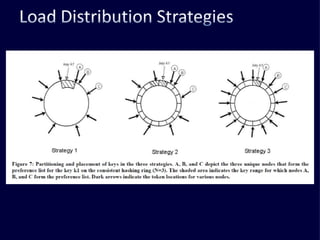
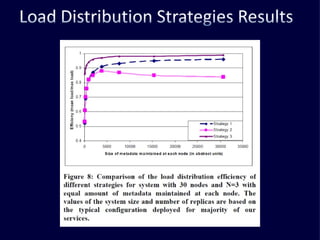
The document discusses several challenges faced by large-scale web companies in managing enormous and rapidly growing amounts of data. It provides examples of architectures developed by companies like Google, Amazon, Facebook and others to distribute data and queries across thousands of servers. Key approaches discussed include distributed databases, data partitioning, replication, and eventual consistency.