Download as PDF, PPTX


























































































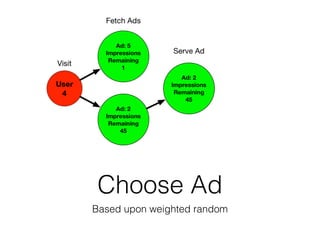
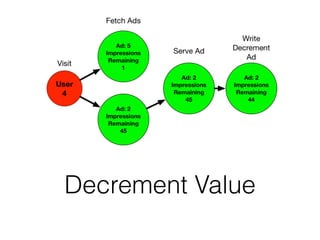
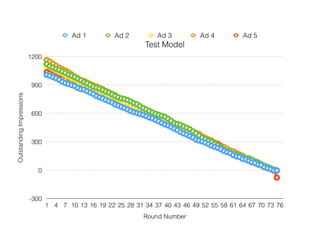
![Test Model
• 50 actors
• 5 Ads with inventory between 1000, and 1200
• Actors randomly get [1,3] times to choose per
round
• Rounds continue until entire inventory is exhausted](https://image.slidesharecdn.com/databasesandstuff-150307115800-conversion-gate01/85/Why-Distributed-Databases-148-320.jpg)
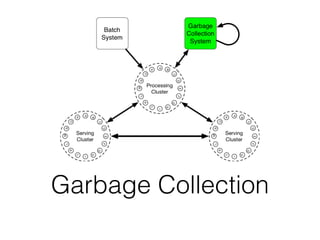








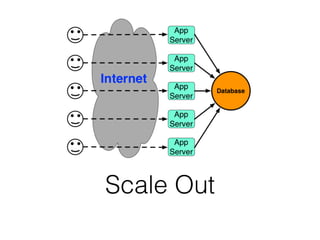
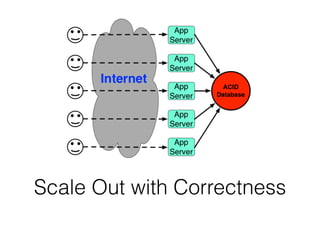
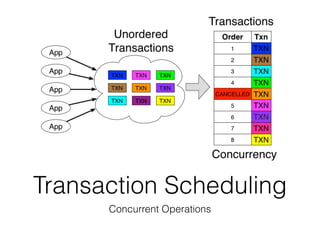
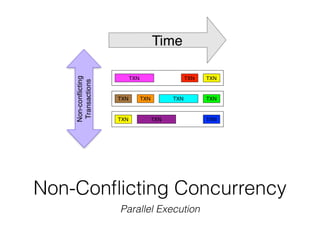
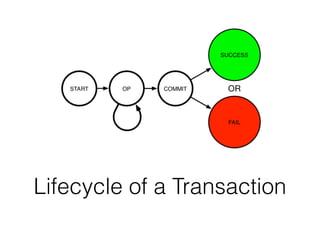
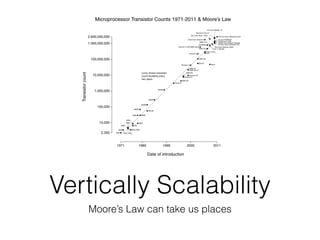
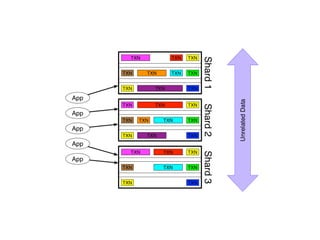
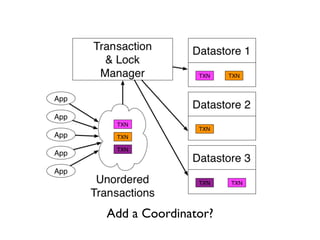
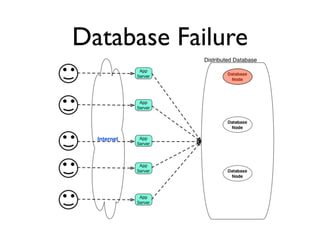
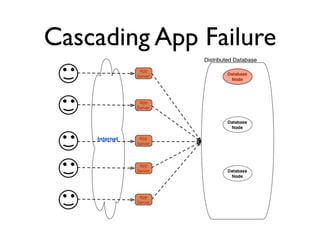
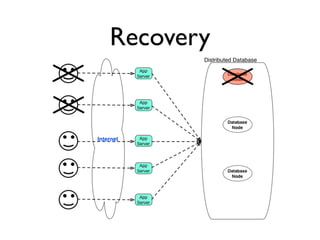
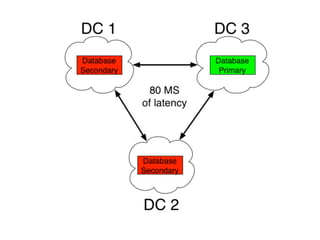
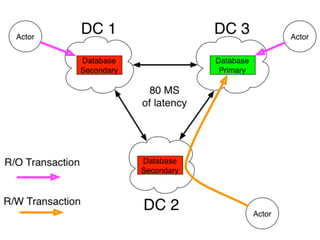
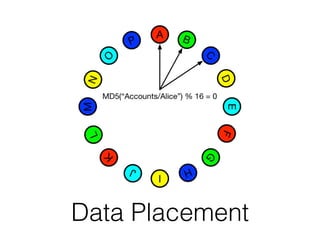
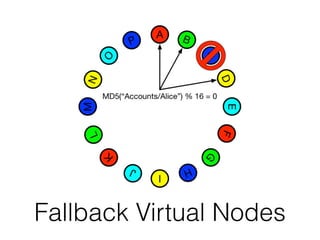
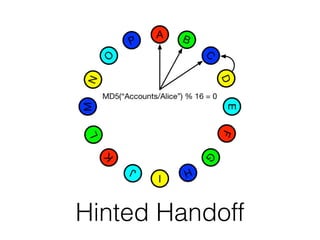
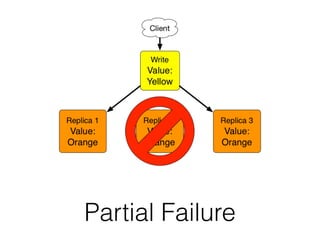
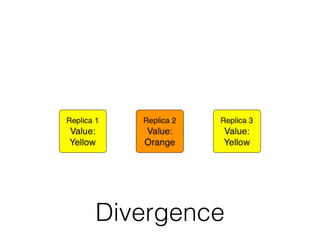
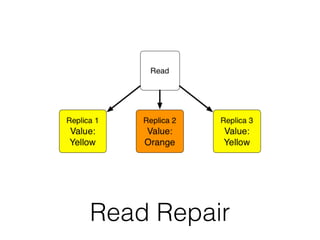
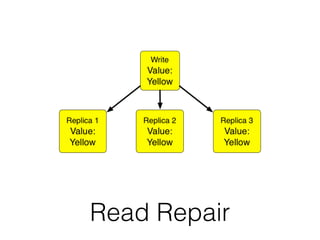
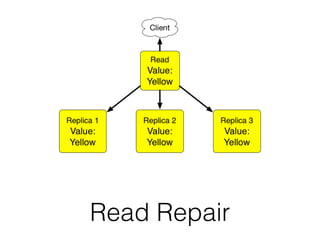
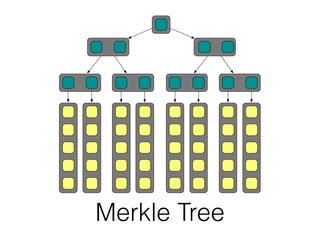
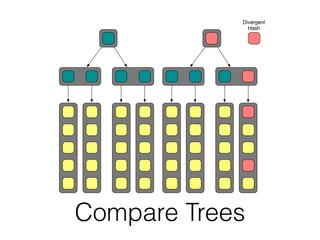
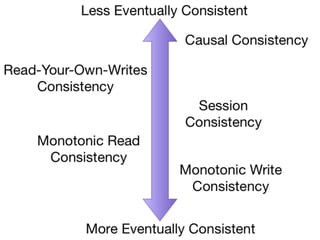
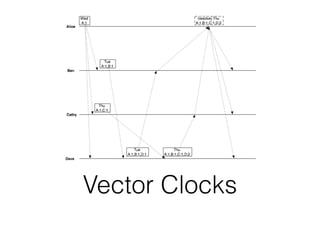
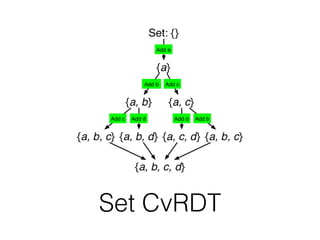
The document discusses databases and distributed systems. It provides an overview of databases, their uses, and how they are built to handle large scale and failures. It describes concepts like transactions, consistency models, and how databases are designed for horizontal and vertical scalability. Key-value store systems like Dynamo and Riak that sacrifice consistency for availability and partition tolerance are examined. The document also covers techniques like CRDTs, vector clocks, and multi-partition transactions that aim to provide both consistency and availability in distributed systems.























































































