Download as PDF, PPTX

























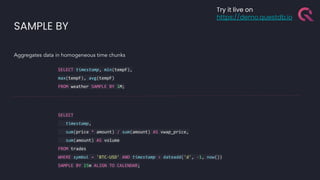


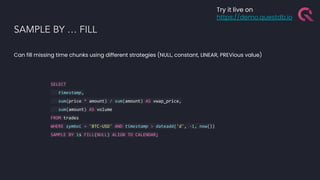
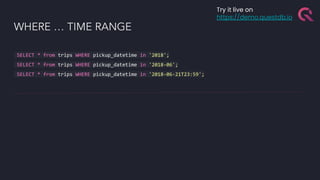
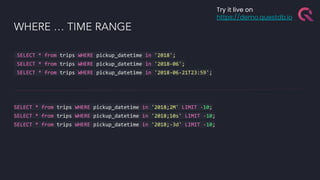
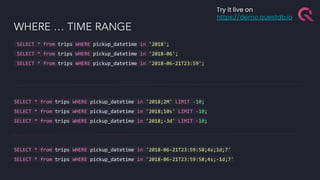

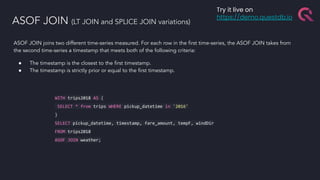




The document discusses the building blocks of a time-series database, emphasizing challenges with timestamp data handling and the suitability of QuestDB for high-speed data ingestion and analytics. It covers features like partitioning data by time, optimized storage, and various connectivity protocols, while also detailing the query engine's efficiencies and capabilities. The text outlines current and future performance optimizations and various deployment options for QuestDB, including open-source and cloud-managed solutions.























































































