Download as PDF, PPTX










![12
db.runCommand({
"collMod": "peaks",
"validator": {
$jsonSchema: {
"bsonType": "object",
"description": "Document describing a mountain peak",
"required": ["name", "height", "location"],
"properties": {
"name": {
"bsonType": "string",
"description": "Name must be a string and is required"
},
"height": {
"bsonType": "number",
"description": "Height must be a number between 100 and 10000 and is required",
"minimum": 100,
"maximum": 10000
},
"location": {
"bsonType": "array",
"description": "Location must be an array of strings",
"minItems": 1,
"uniqueItems": true,
"items": {
"bsonType": "string"
}
}
},
}
}
})
https://www.digitalocean.com/community/tutorials/how-to-use-schema-validation-in-mongodb](https://image.slidesharecdn.com/ramirezjavierwedyourdatabasecannotdothiswell-230530115707-c0999e78/75/Your-Database-Cannot-Do-this-well-12-2048.jpg)
![13
db.createCollection( "orders",
{
validator: {
$expr:
{
$eq: [
"$totalWithVAT",
{ $multiply: [ "$total", { $sum:[ 1, "$VAT" ] } ] }
]
}
}
}
)
db.orders.insertOne( {
total: NumberDecimal("141"),
VAT: NumberDecimal("0.20"),
totalWithVAT: NumberDecimal("169")
} )
db.orders.insertOne( {
total: NumberDecimal("141"),
VAT: NumberDecimal("0.20"),
totalWithVAT: NumberDecimal("169.2")
} )
https://www.mongodb.com/docs/manual/core/schema-validation/specify-query-expression-rules/#std-label-schema-validation-query-expression](https://image.slidesharecdn.com/ramirezjavierwedyourdatabasecannotdothiswell-230530115707-c0999e78/75/Your-Database-Cannot-Do-this-well-13-2048.jpg)




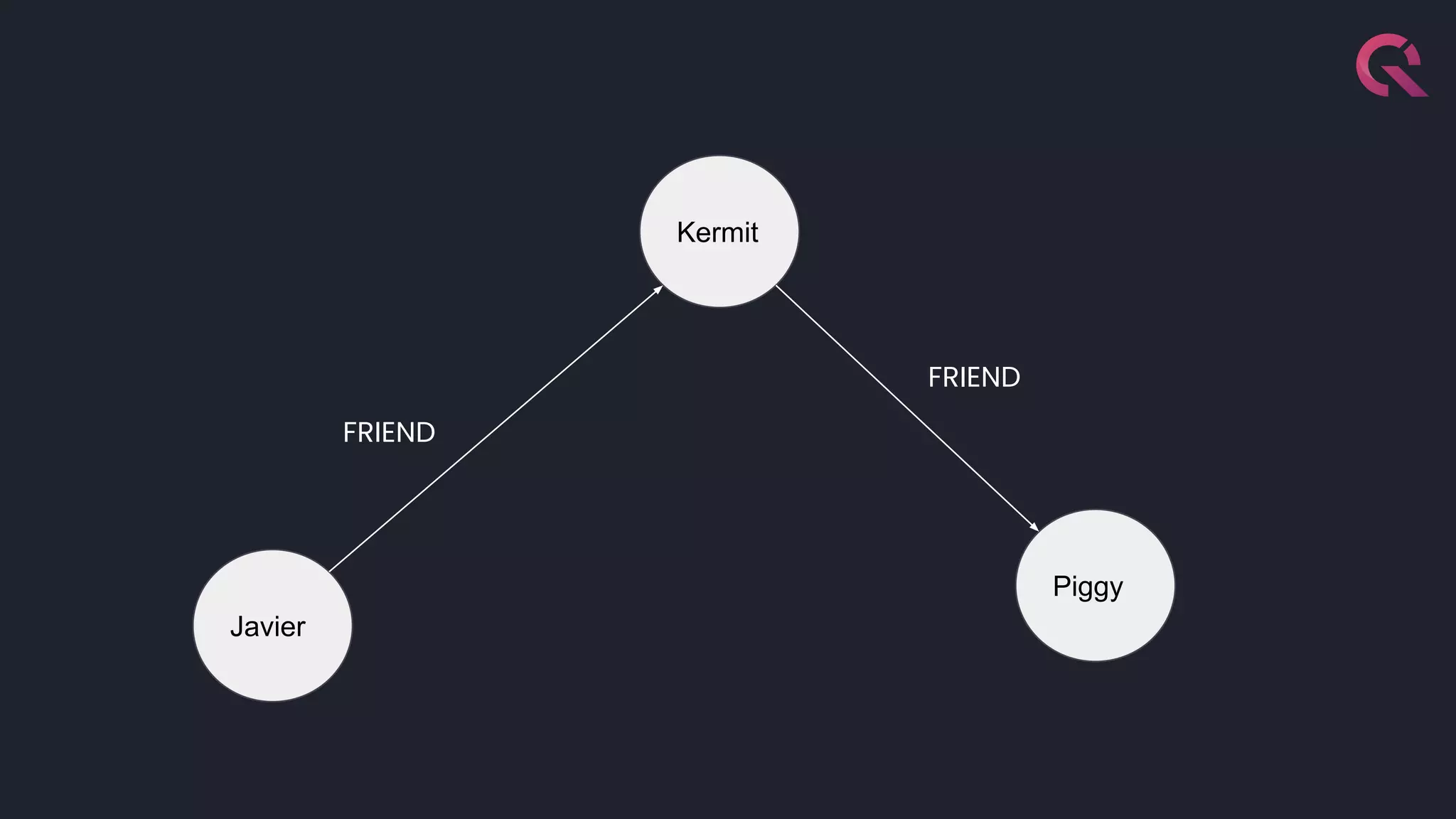
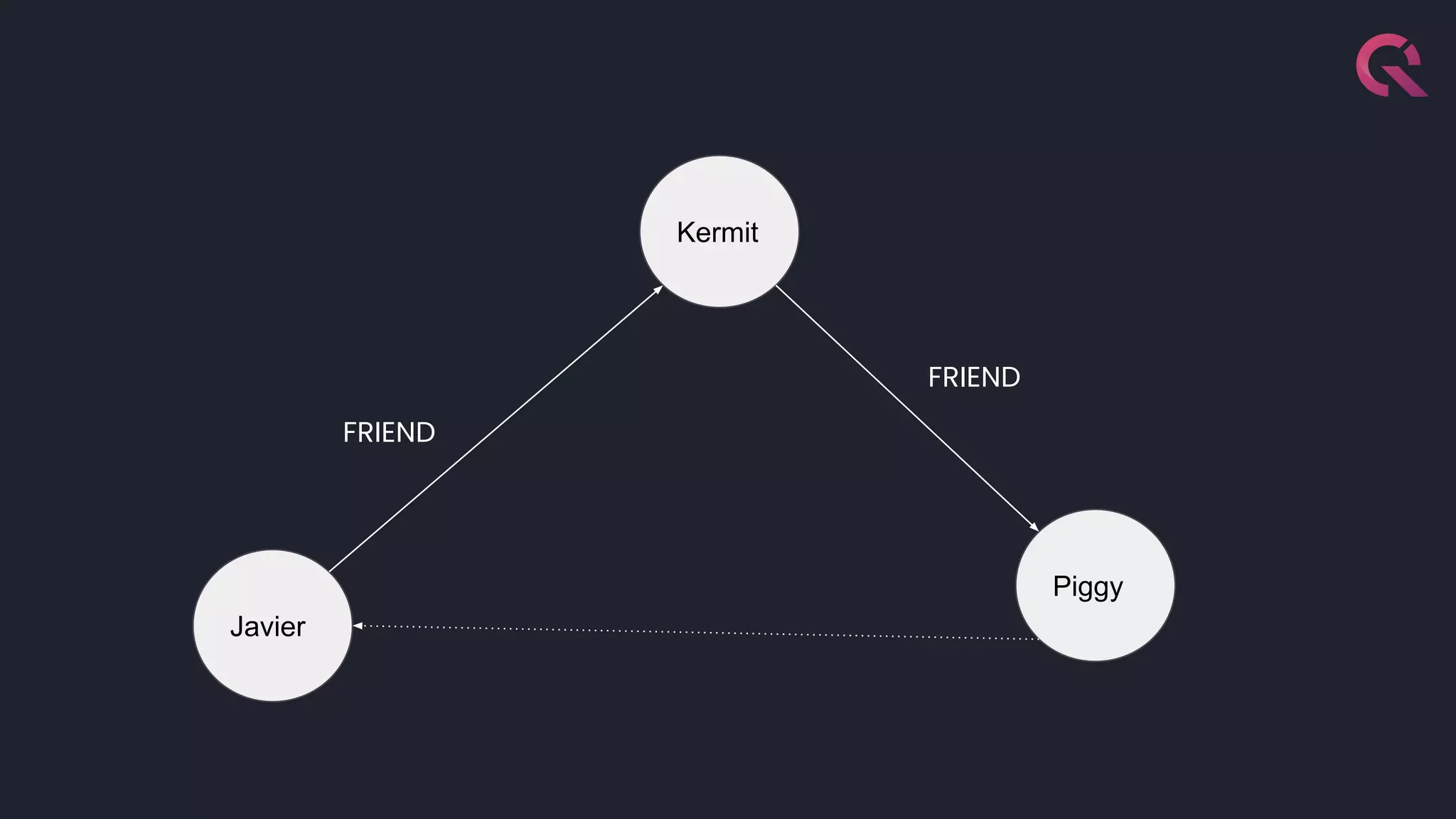
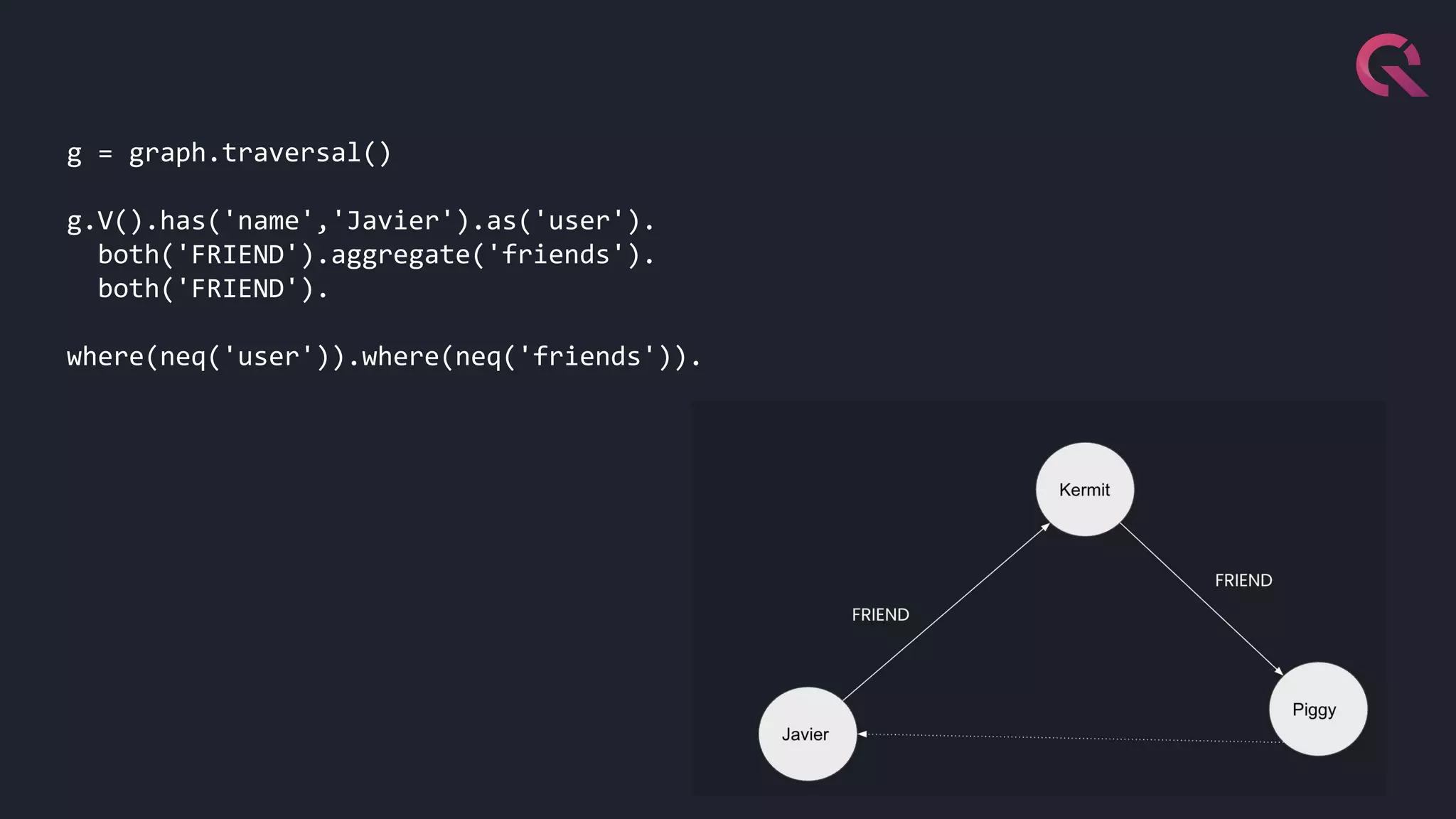
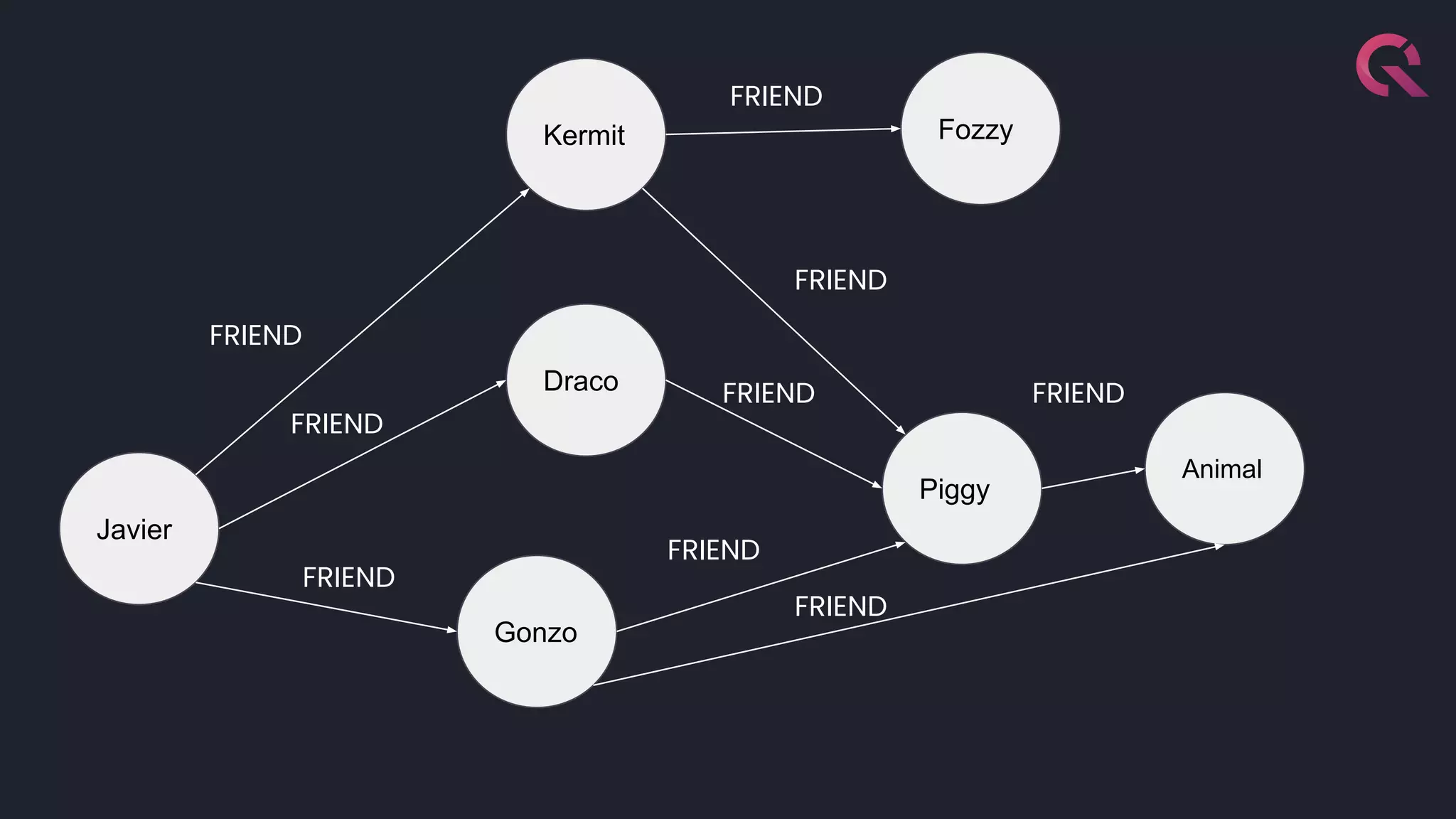
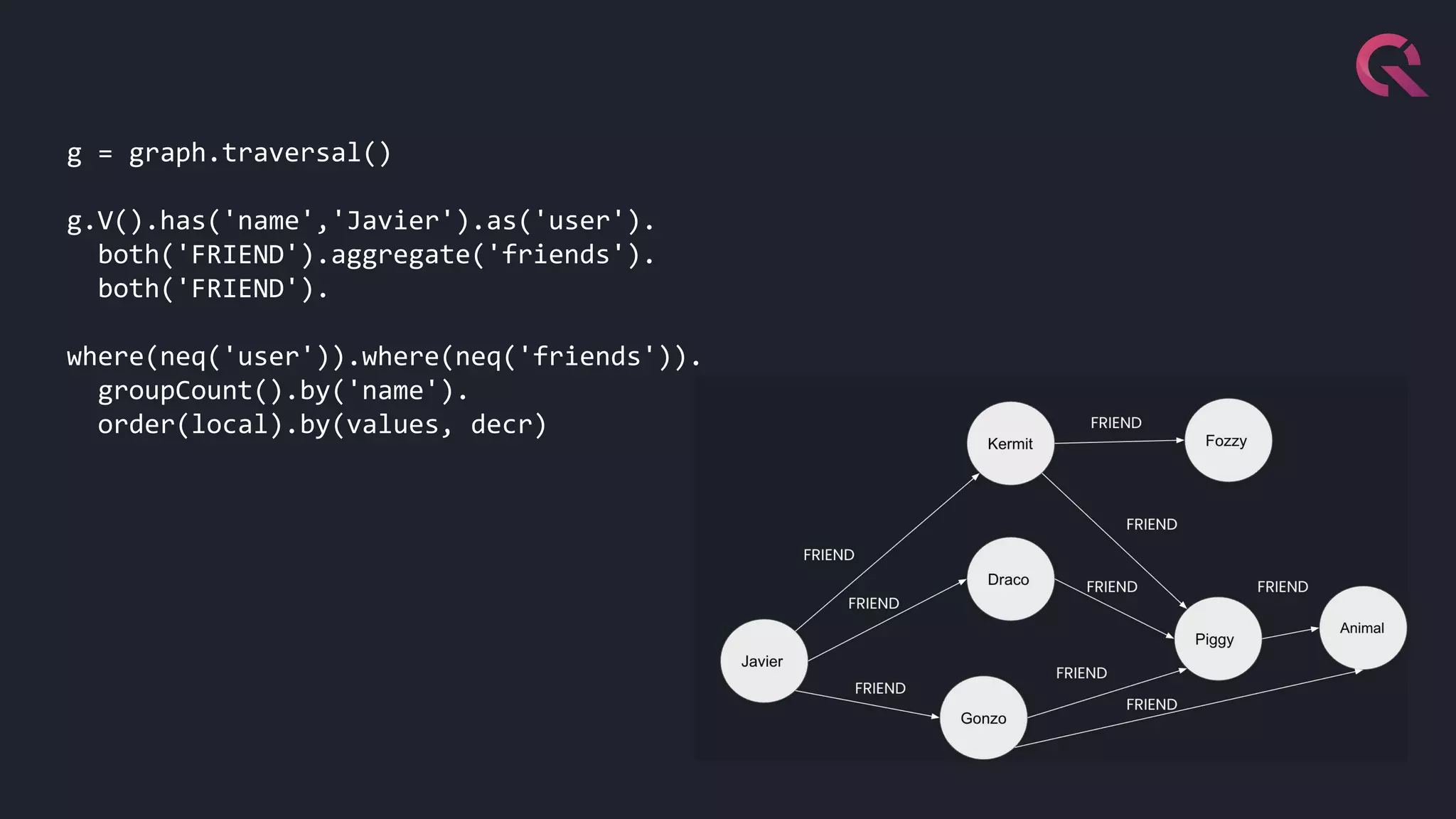










Javier Ramirez, a leading figure in developer relations at QuestDB, discusses various database technologies, emphasizing the strengths and limitations of relational, document, graph, and time-series databases. He highlights PostgreSQL as a strong choice for traditional database needs but notes the inefficacy of RDBMS for handling highly nested schemas and rapid write operations. Additionally, Ramirez showcases QuestDB's performance in comparison to other databases for time-series data handling and emphasizes the importance of optimization for developer experience.




















![[Mas 500] Data Basics](https://cdn.slidesharecdn.com/ss_thumbnails/mas-500-4-data-basics-131120205428-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)














































