Download as PDF, PPTX













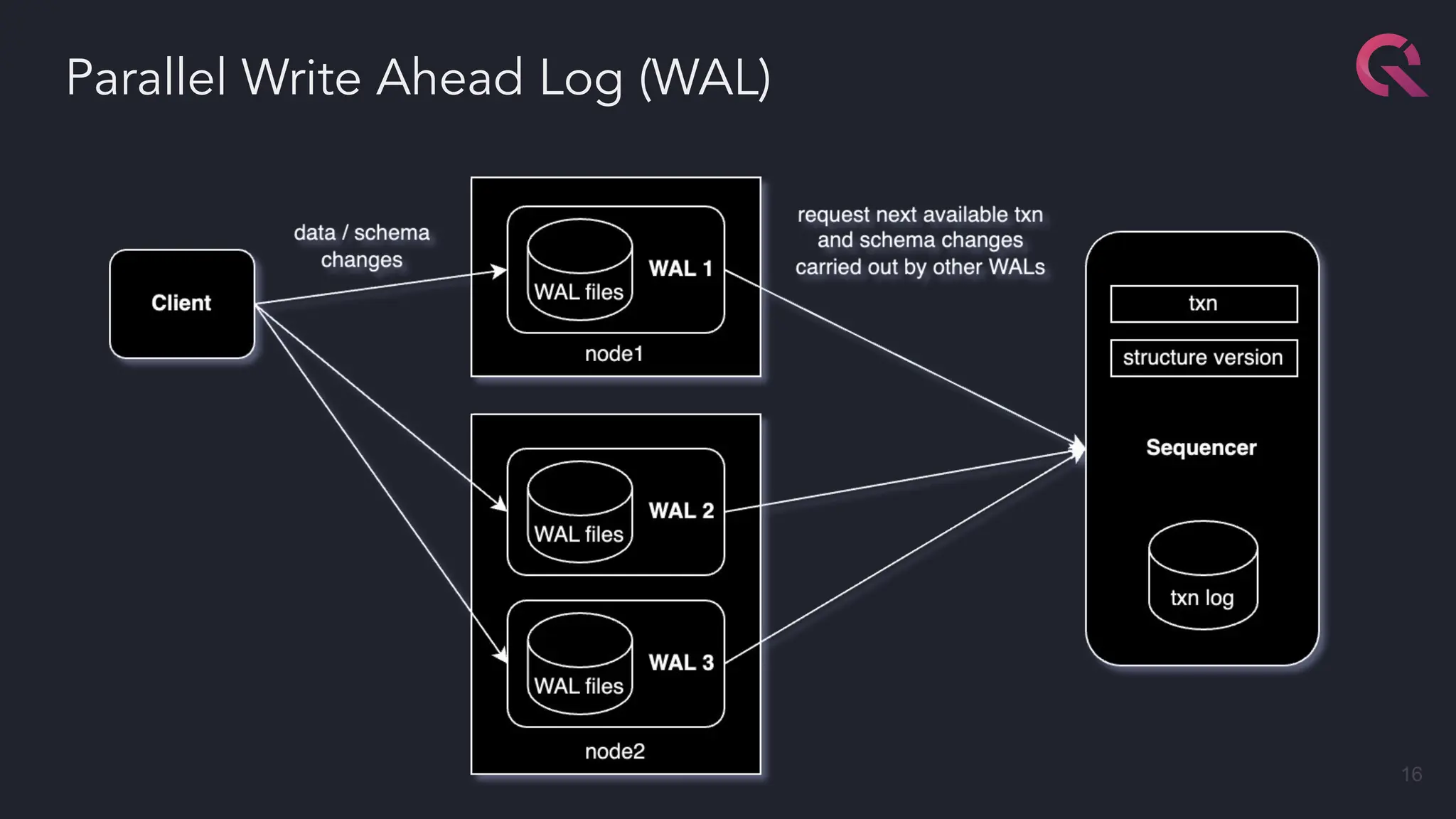
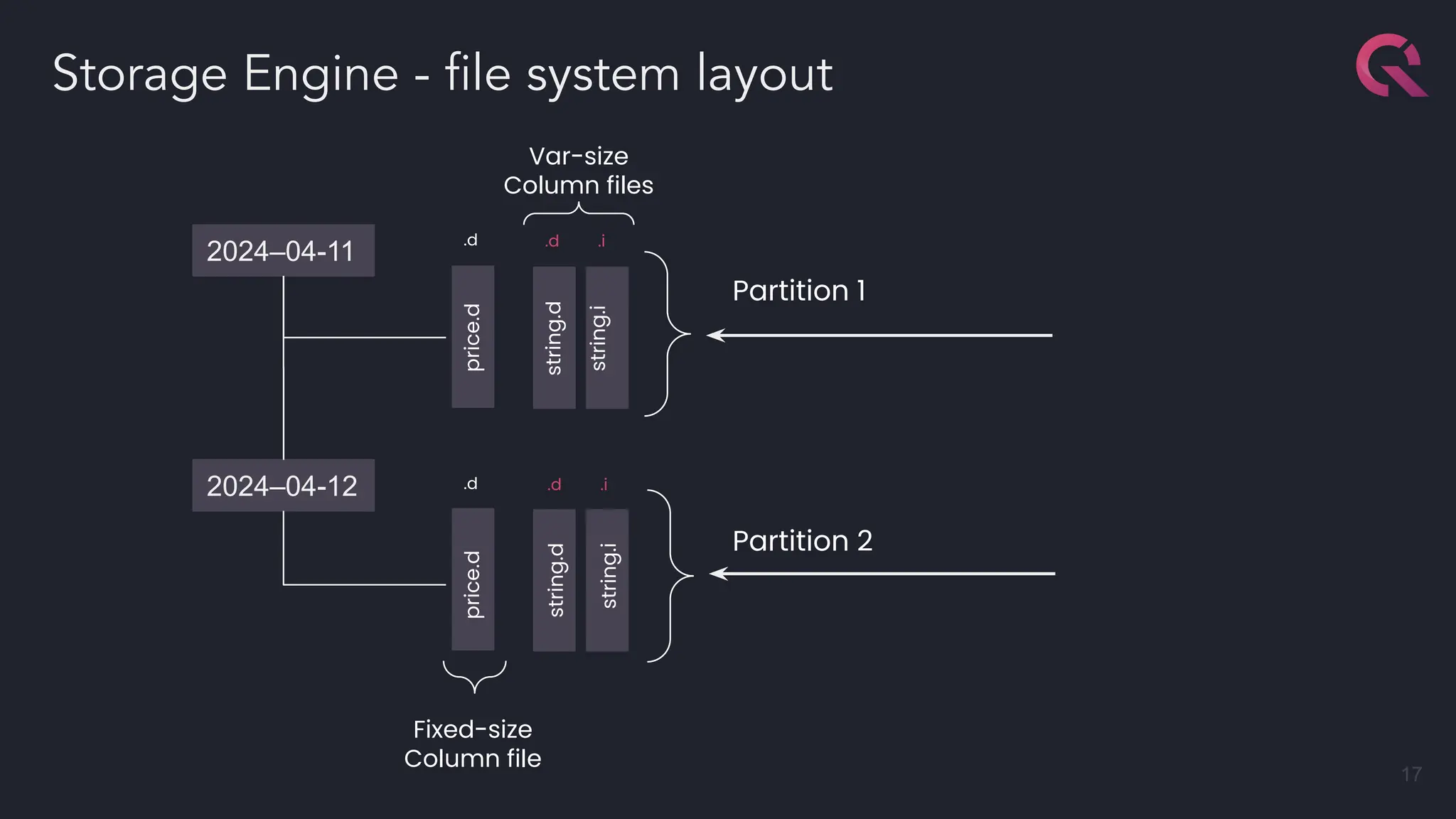
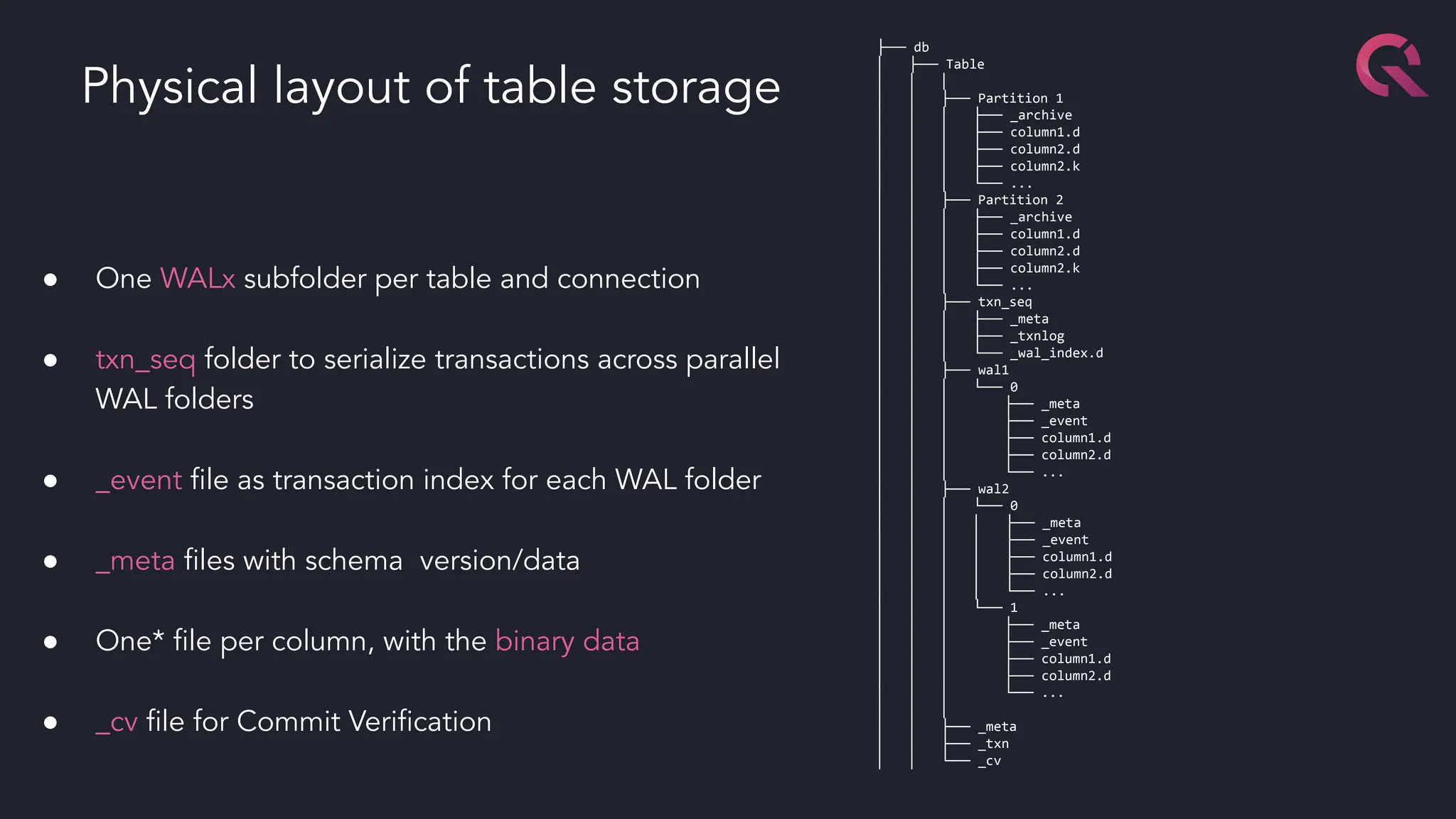










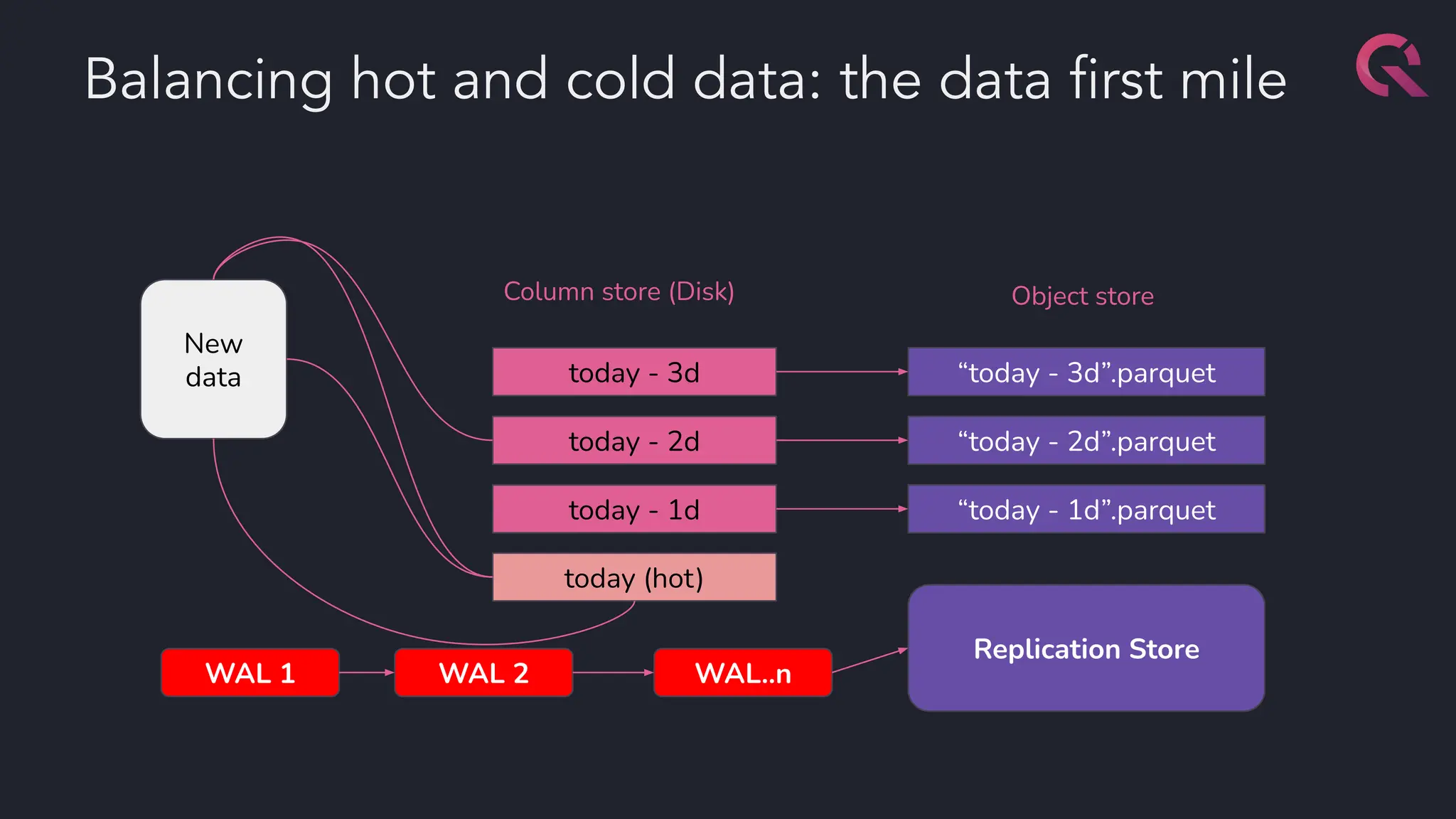
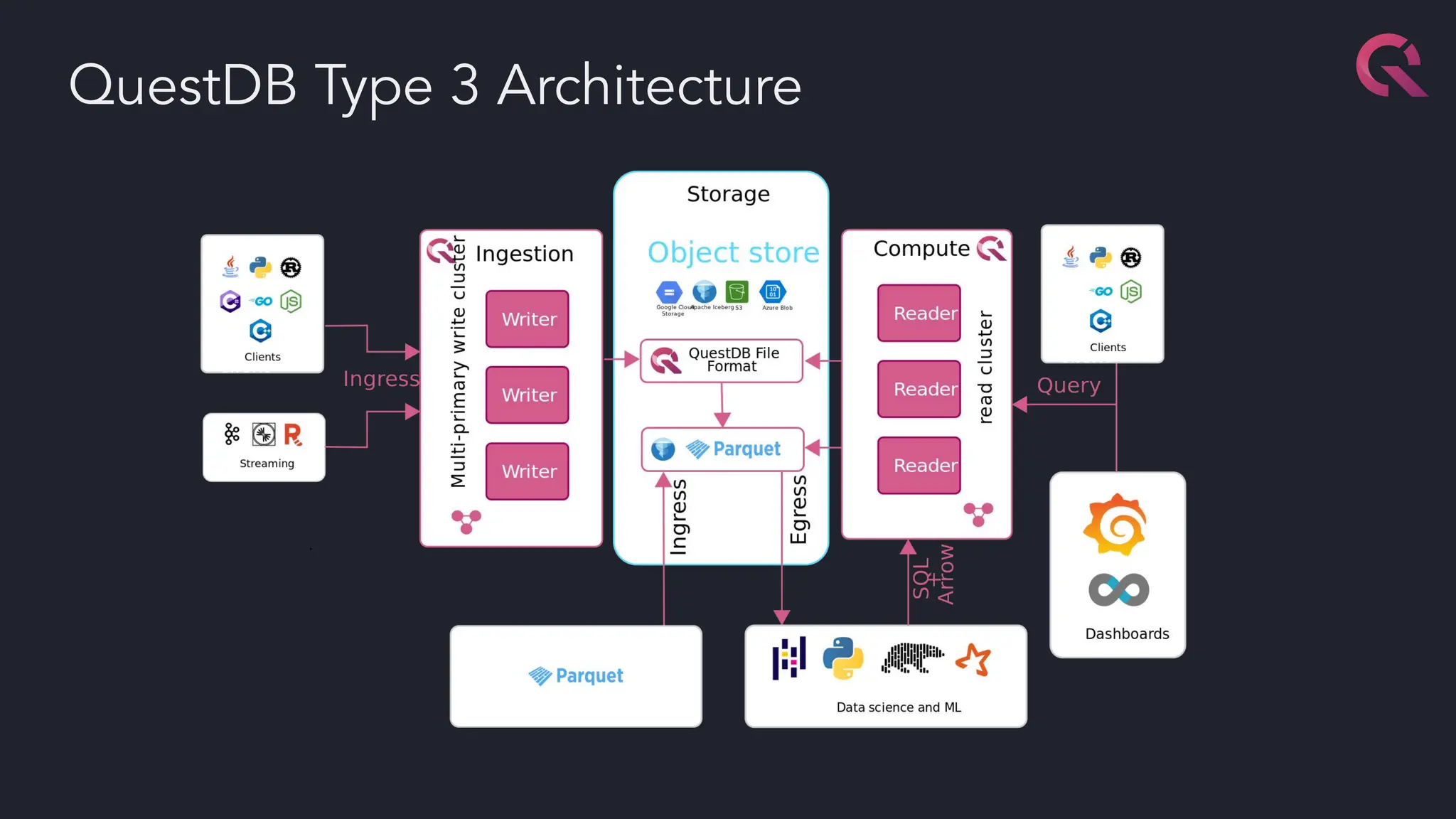





The document discusses advancements in fast databases, particularly focusing on QuestDB, which is designed for efficient ingestion and querying of large datasets. It highlights the evolution of database technology from OLTP and OLAP models to the integration of open formats like Apache Arrow for improved performance. The future vision includes a convergence of time series databases and OLAP, with enhanced capabilities for data handling and analysis.

















































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)



