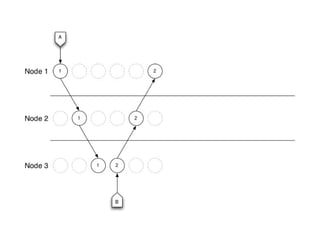
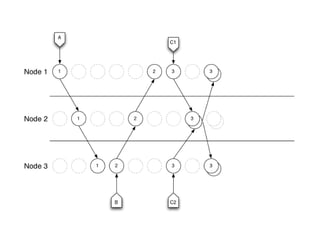
The document discusses distributed systems, their advantages and challenges, focusing on consistency and the CAP theorem. It covers various strategies for achieving consistency, such as vector clocks, CRDTs, and log structured storage, while highlighting the economic shifts that make distributed systems appealing. The conclusion emphasizes the importance of designing data structures that leverage cheap storage and operational commutativity to solve consistency issues.