



























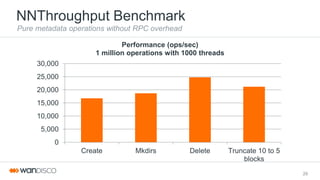




The document describes HDFS's implementation of file truncation, which allows reducing a file's length. It evolved HDFS's write-once semantics to support data mutation. Truncate uses the lease and block recovery framework to truncate block replicas in-place, except when snapshots exist, where it uses "copy-on-truncate" to preserve the snapshot. The truncate operation returns immediately after updating metadata, while block adjustments occur in the background.




































![Inspiring Travel at Airbnb [WIP]](https://cdn.slidesharecdn.com/ss_thumbnails/june91205pmairbnbqiancheng-150616222059-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





































































