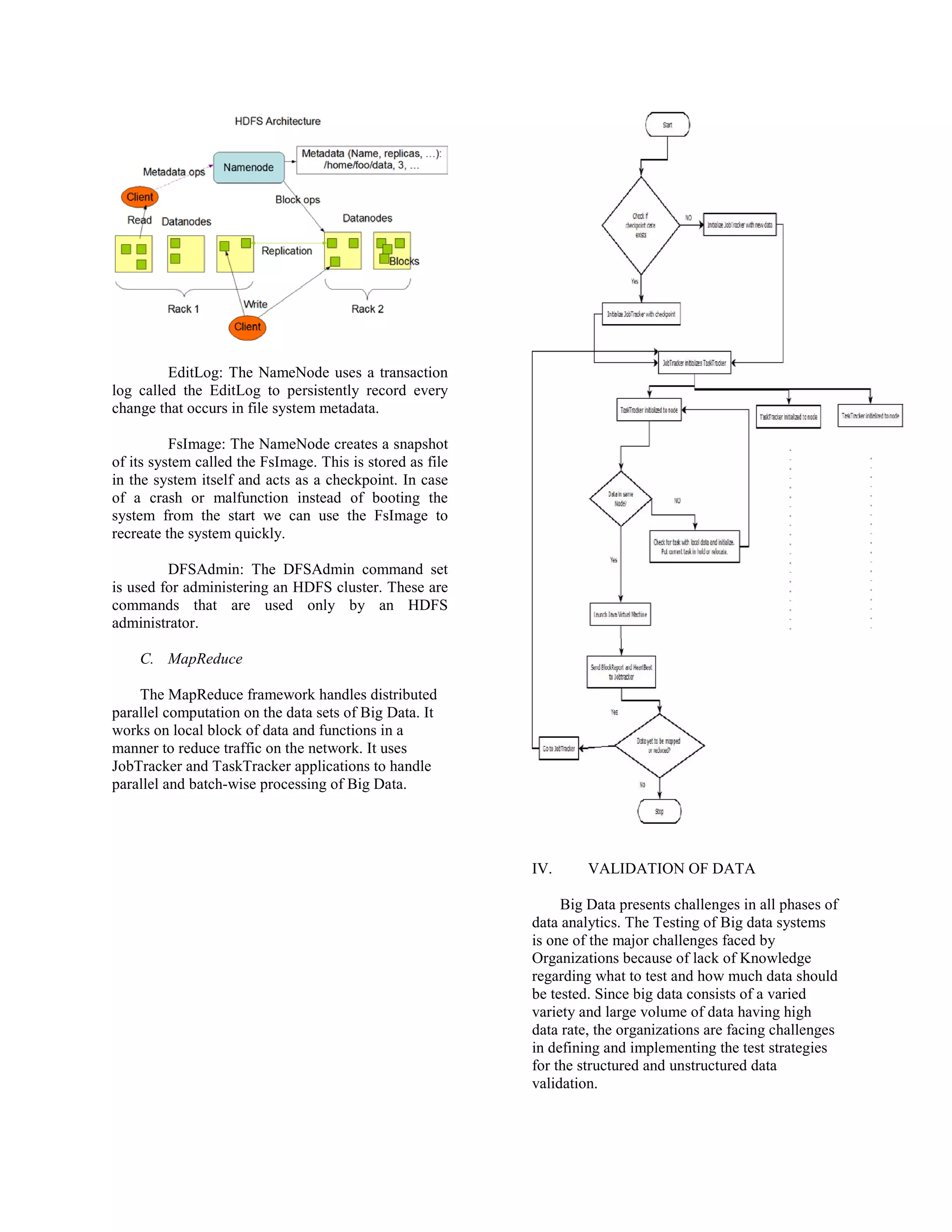
This document discusses big data analysis using Hadoop and proposes a system for validating data entering big data systems. It provides an overview of big data and Hadoop, describing how Hadoop uses MapReduce and HDFS to process and store large amounts of data across clusters of commodity hardware. The document then outlines challenges in validating big data and proposes a utility that would extract data from SQL and Hadoop databases, compare records to identify mismatches, and generate reports to ensure only correct data is processed.