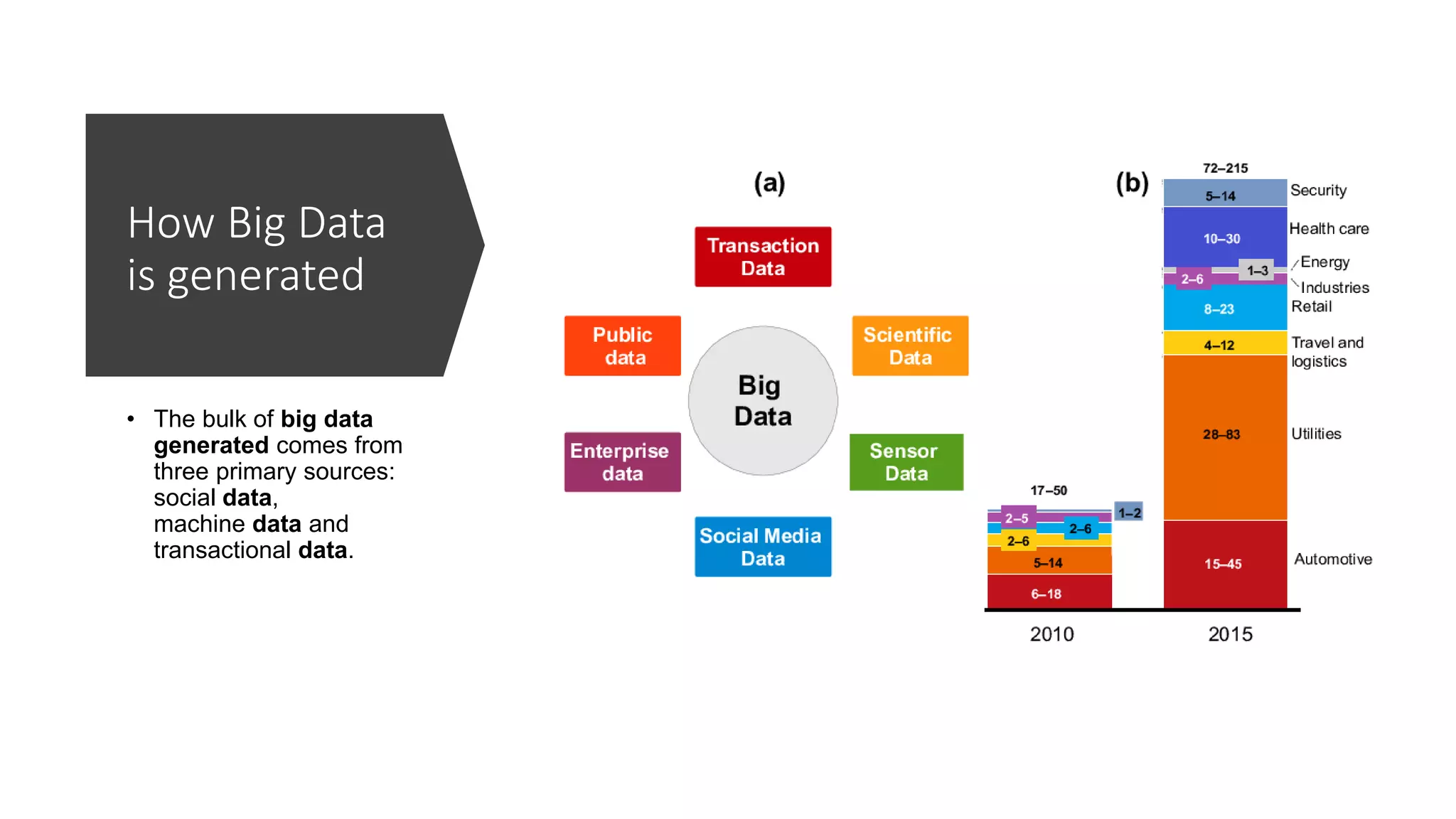
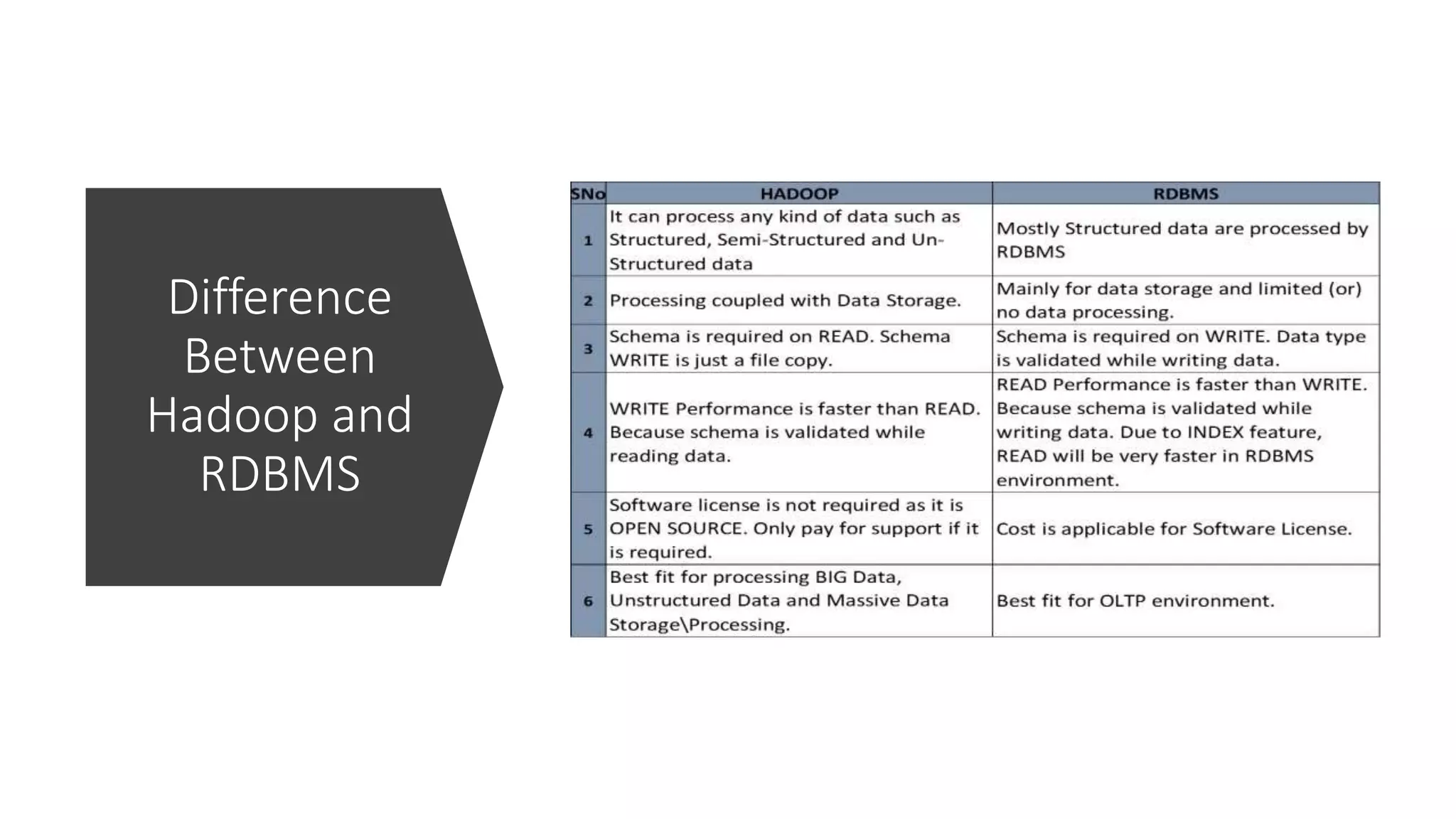
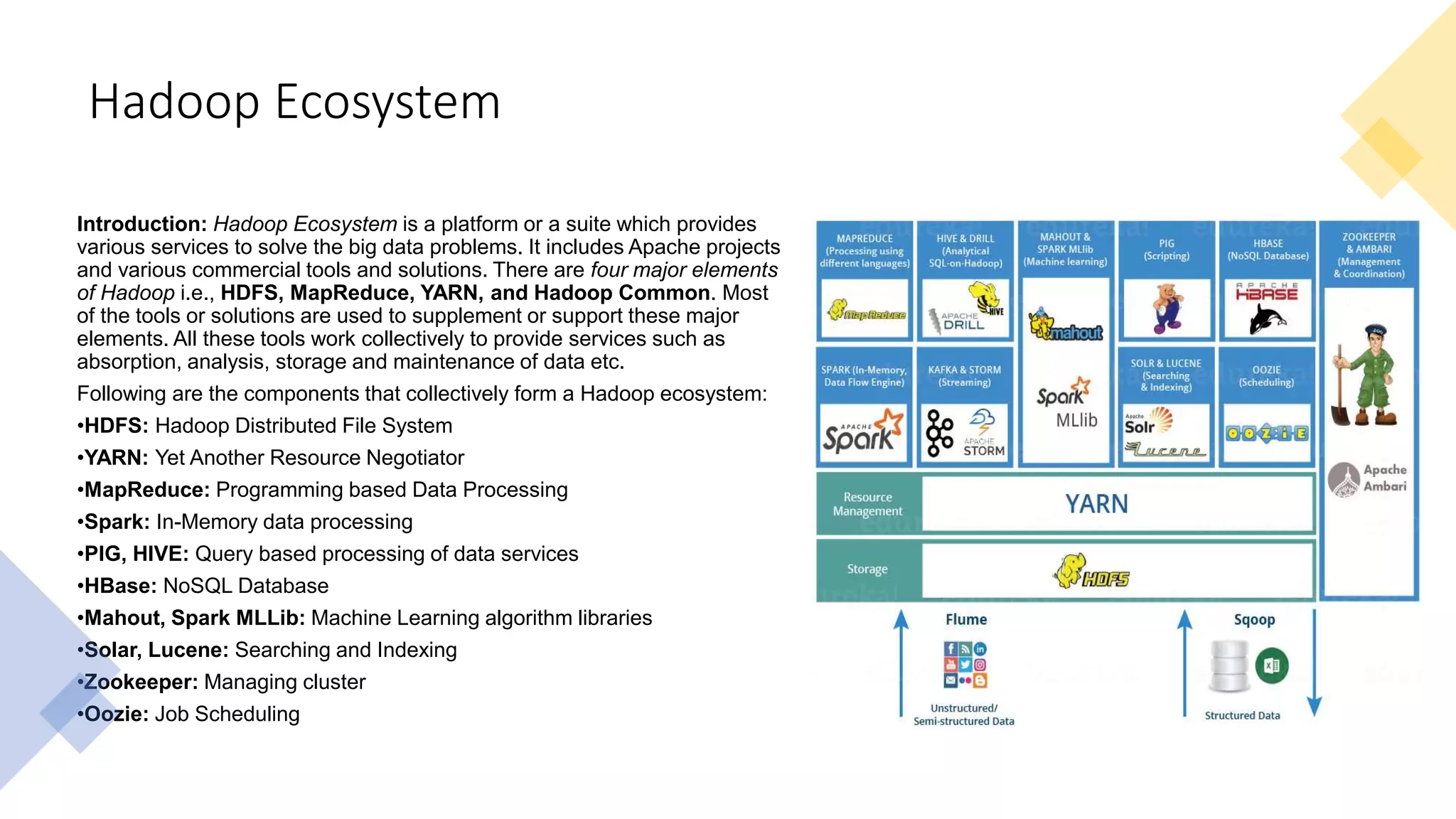
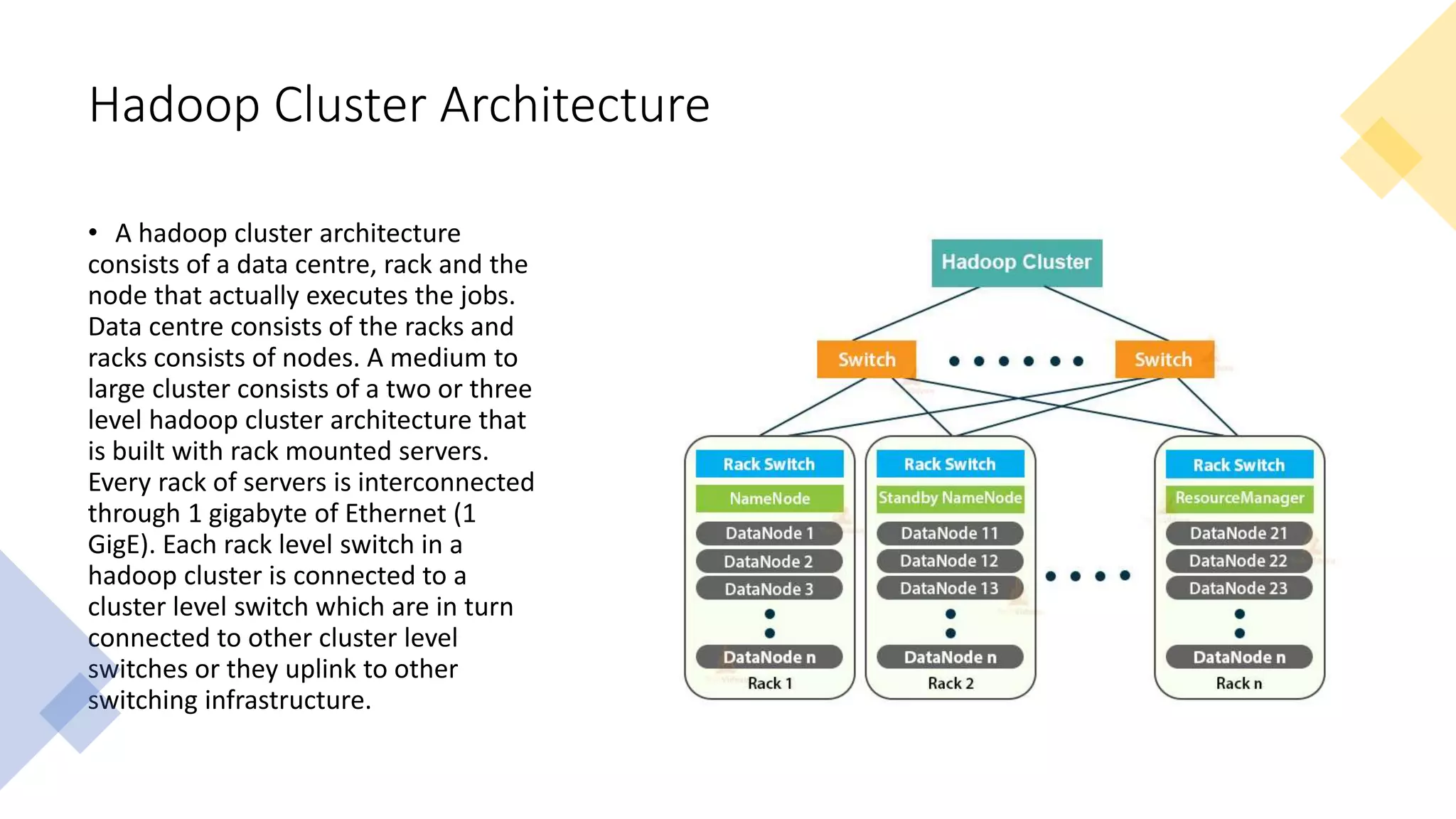
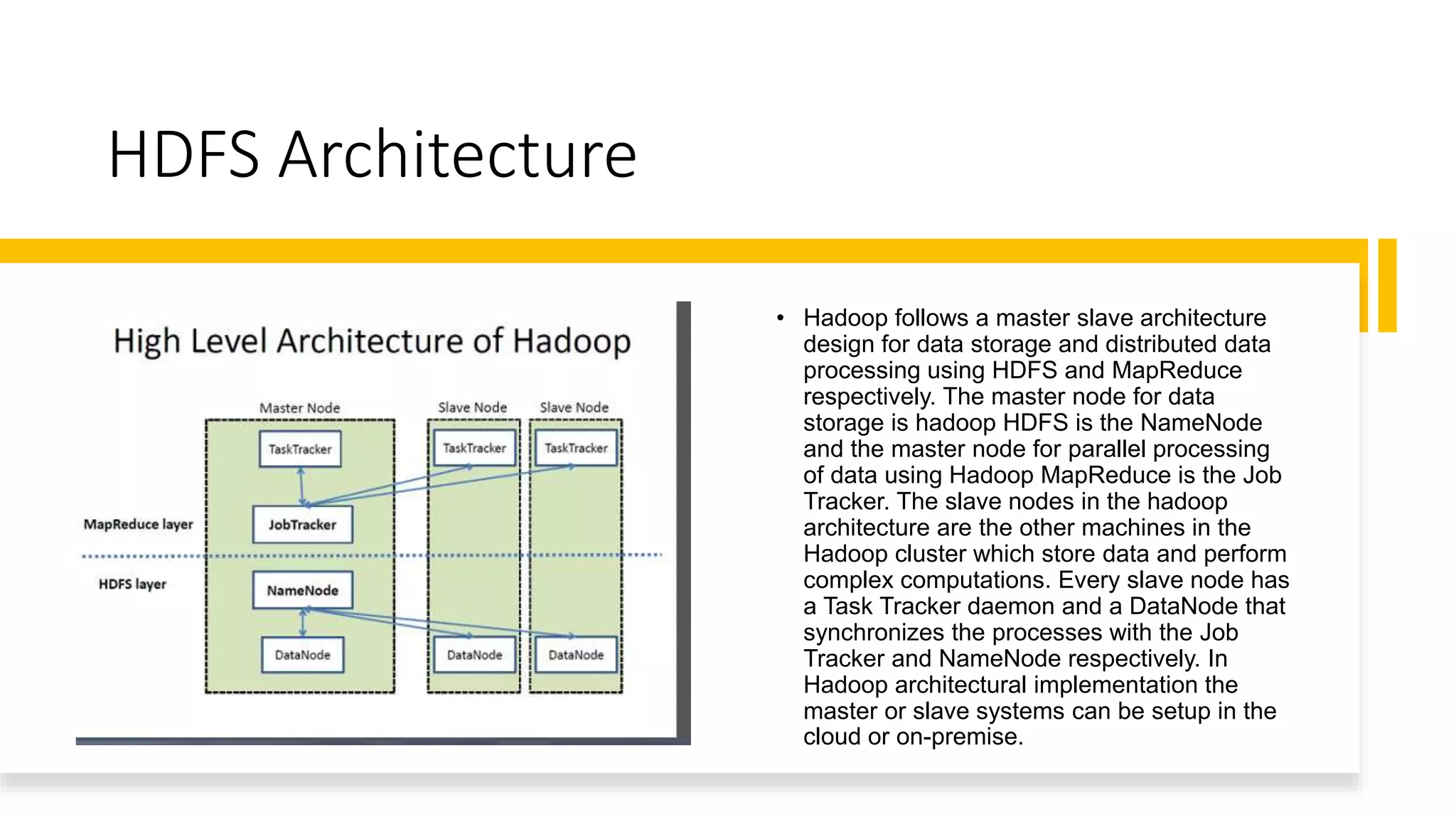
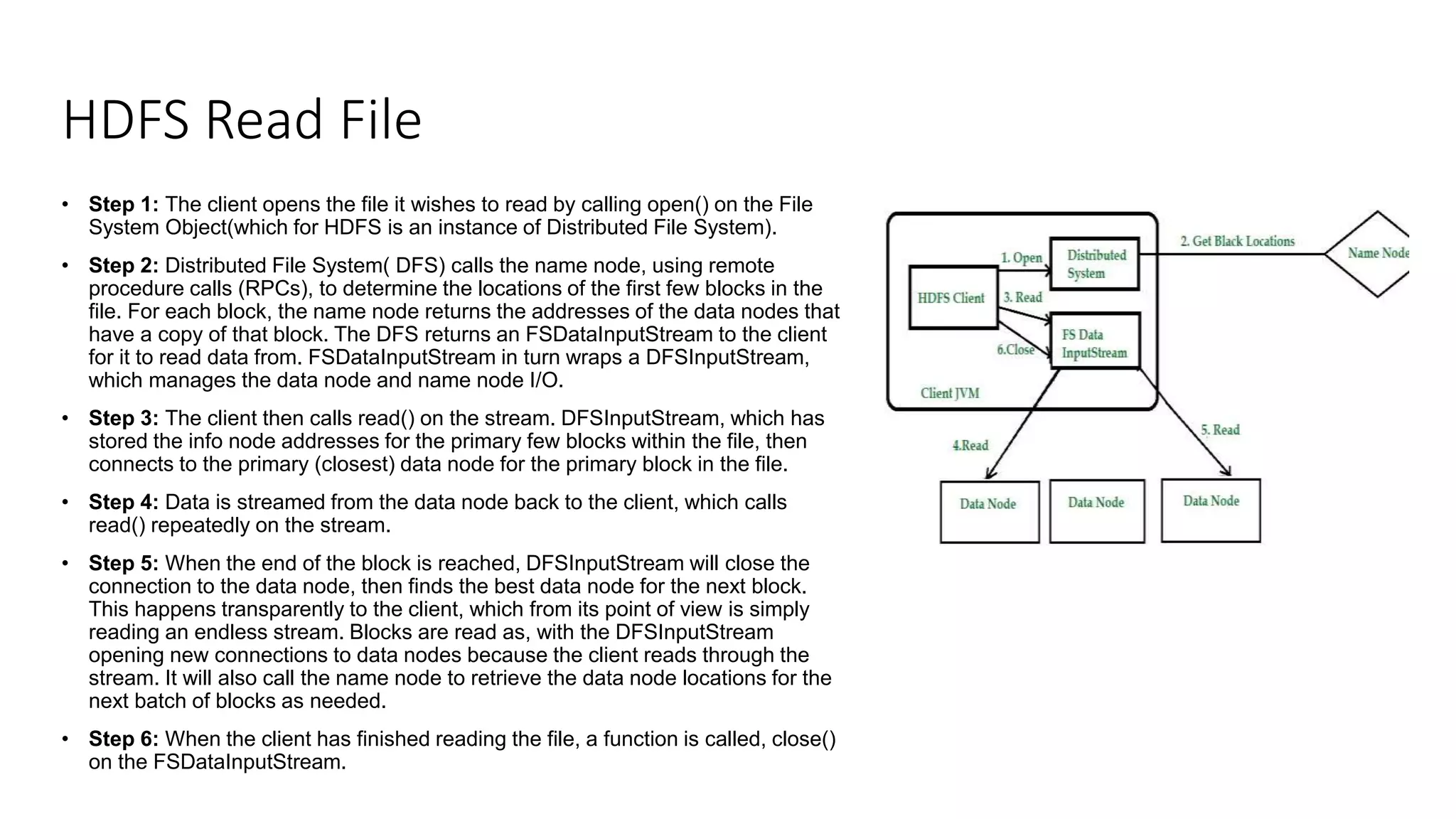
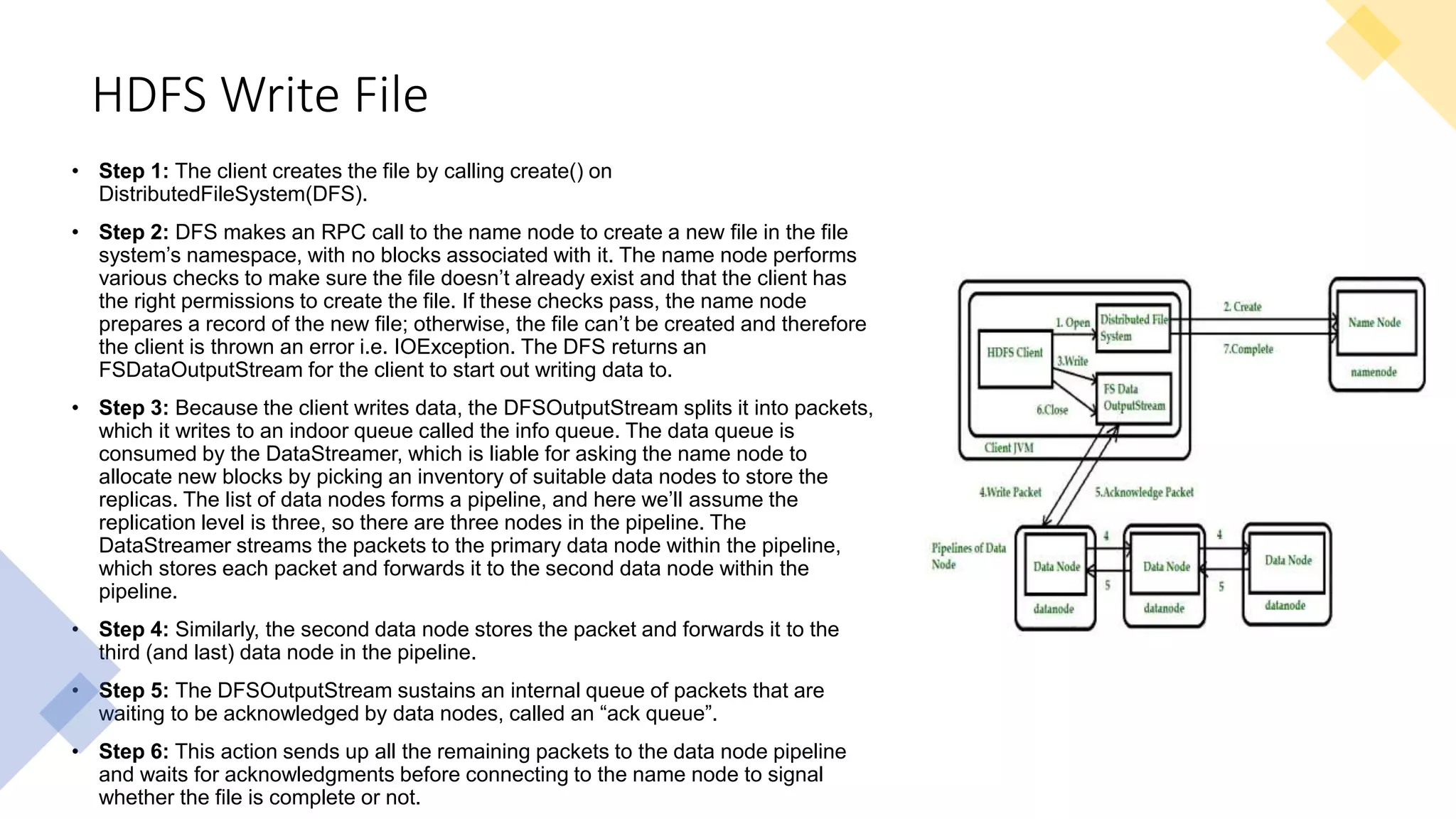
This document provides an introduction to Hadoop and big data concepts. It discusses what big data is, the four V's of big data (volume, velocity, variety, and veracity), different data types (structured, semi-structured, unstructured), how data is generated, and the Apache Hadoop framework. It also covers core Hadoop components like HDFS, YARN, and MapReduce, common Hadoop users, the difference between Hadoop and RDBMS systems, Hadoop cluster modes, the Hadoop ecosystem, HDFS daemons and architecture, and basic Hadoop commands.