Downloaded 20 times









![Basic Linux Commands
cat [filename] Display file’s contents to the standard output
device
(usually your monitor).
cd /directorypath Change to directory.
chmod [options] mode filename Change a file’s permissions.
clear Clear a command line screen/window for a
fresh start.
cp [options] source destination Copy files and directories.
ls [options] List directory contents.
mkdir [options] directory Create a new directory.
mv [options] source destination Rename or move file(s) or directories.
pwd Display the pathname for the current
directory.touch filename Create an empty file with the specified name.
who [options] Display who is logged on.](https://image.slidesharecdn.com/hadoopinaction-161211171948/85/Hadoop-in-action-24-320.jpg)



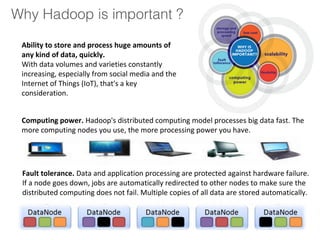
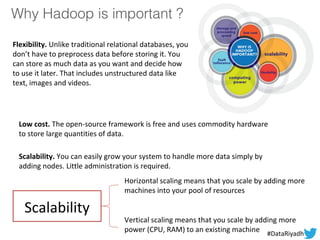
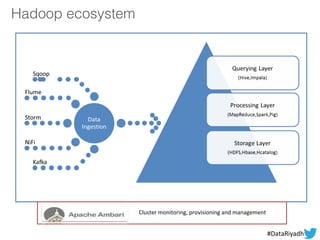
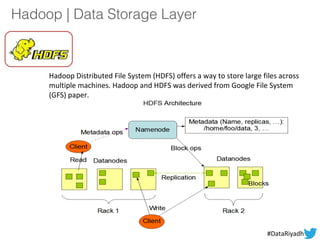
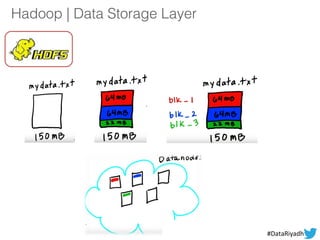
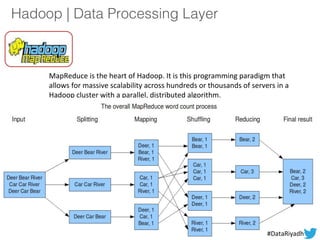
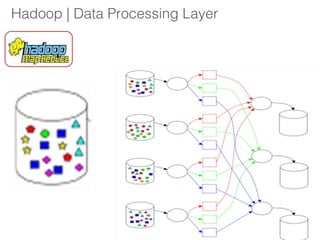
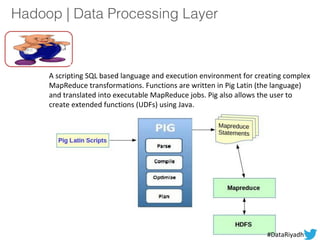
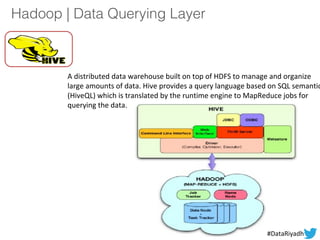
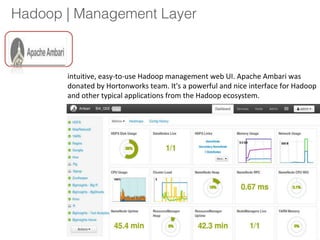
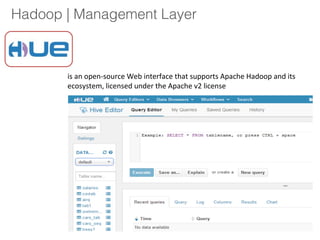
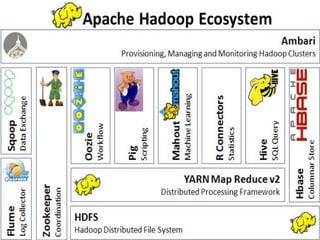
The document outlines a hands-on session on Hadoop, covering its definition, importance, and ecosystem, followed by a practical demonstration of data ingestion and processing using various tools. Key topics include data storage in HDFS, querying with Hive and MapReduce, and the use of Apache Sqoop for data transfer. The session aims to provide participants with a comprehensive understanding of how to implement Hadoop in real-world scenarios.



































































