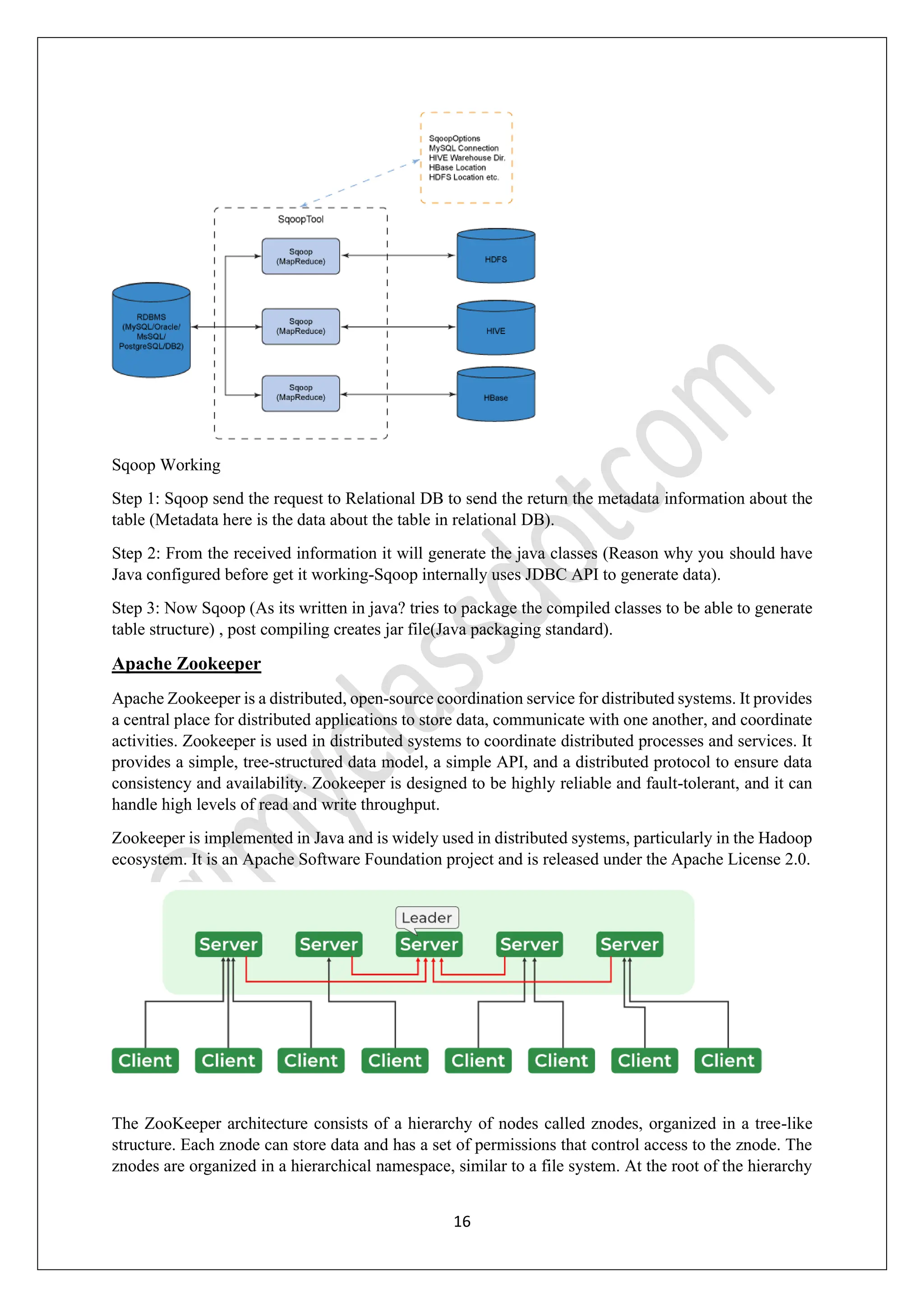
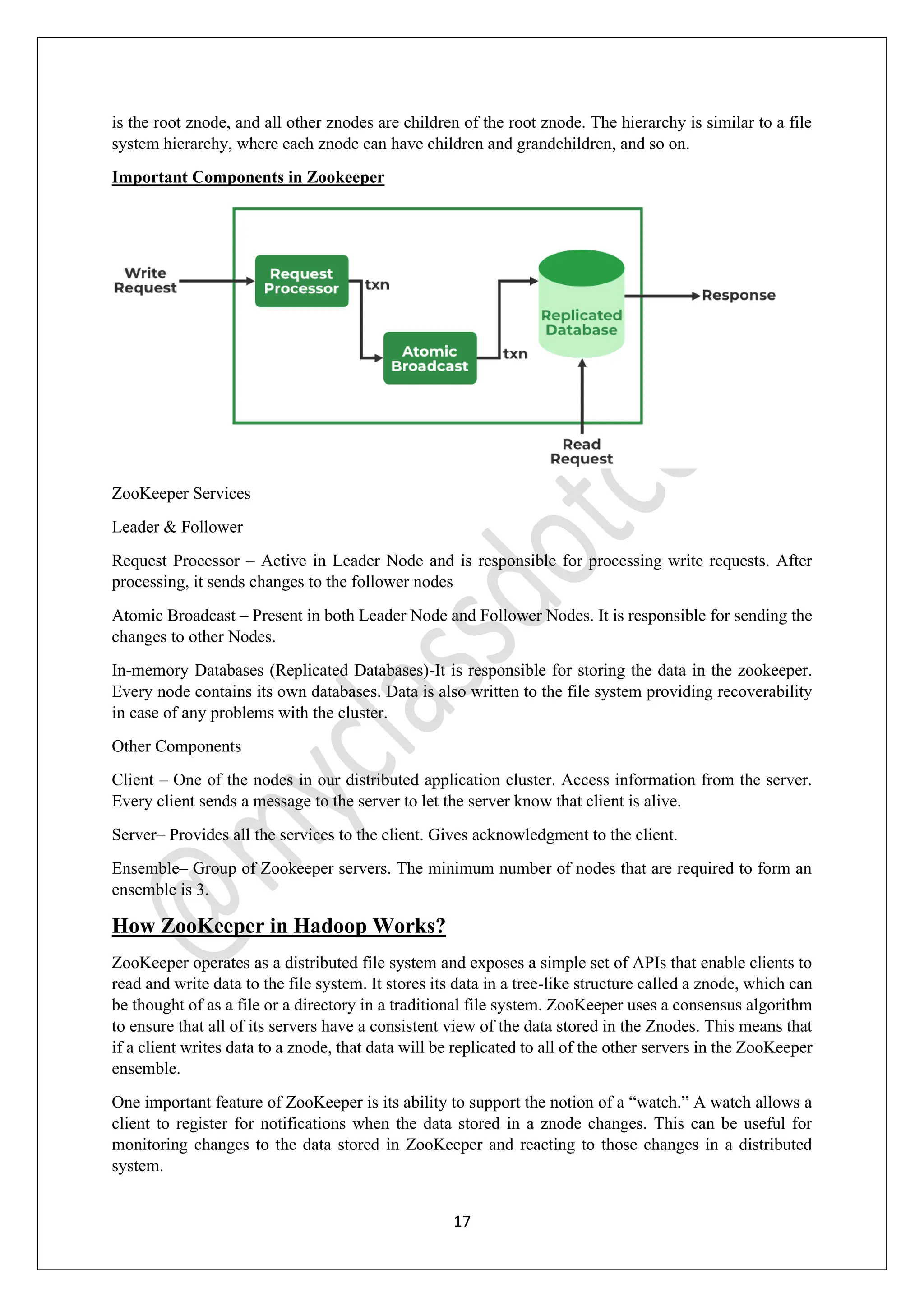
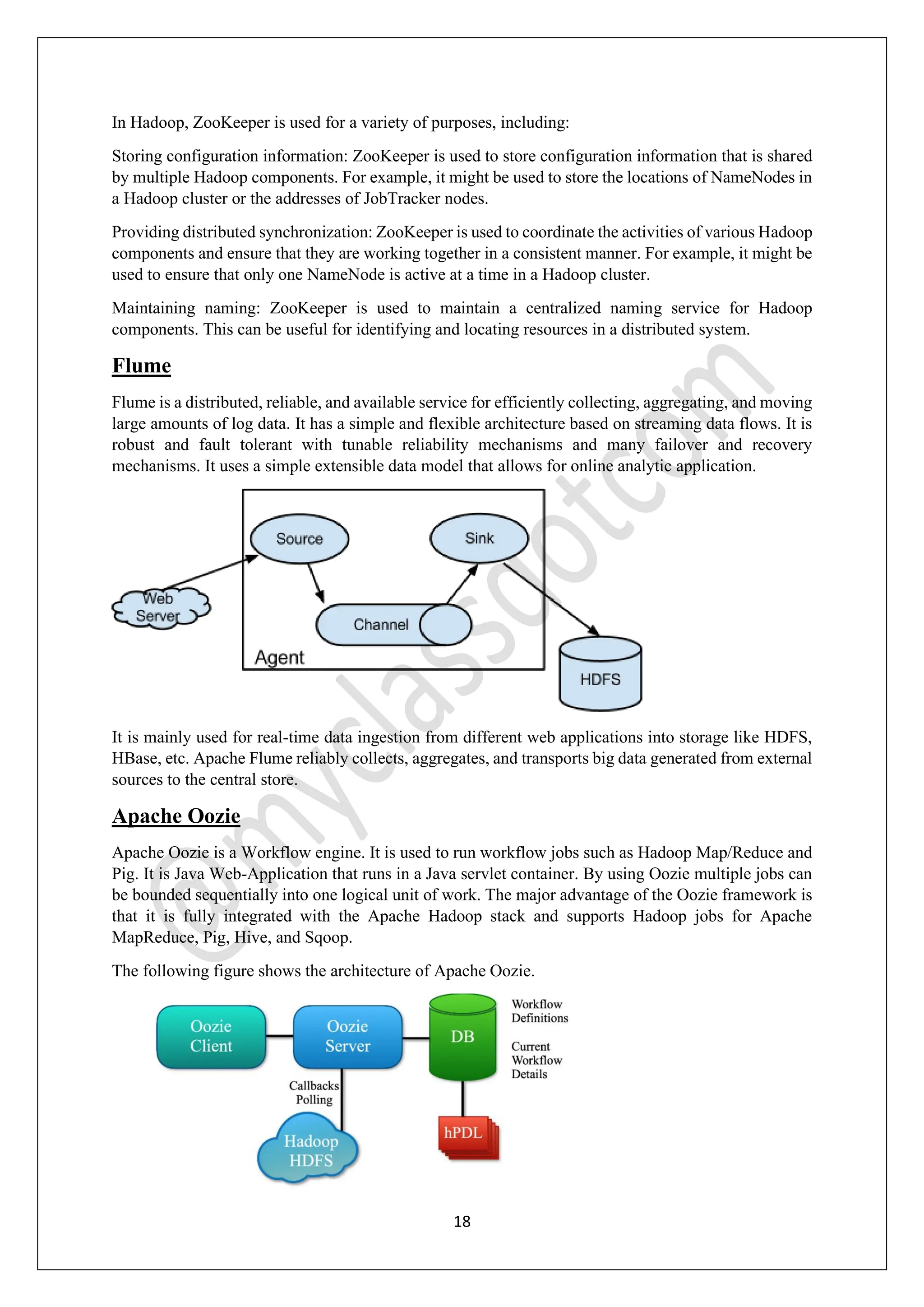
The Hadoop Ecosystem is an open-source framework designed for efficient processing and management of large data sets, known as big data, across various clusters. It comprises several core components including HDFS for storage, MapReduce for processing, YARN for resource management, and additional tools like Hive, Pig, and HBase for data querying and analytics. Together, these components work to provide scalable, reliable, and fault-tolerant data solutions, making Hadoop a critical technology for industries handling vast amounts of data.











![13
also ensures that there is no other application with the same ID that has already been submitted that
could cause an error. After performing these checks, it finally forwards the application to the scheduler.
Schedulers
The scheduler as the name suggests is responsible for scheduling the tasks. The scheduler neither
monitors nor tracks the status of the application nor does restart if there is any failure occurred. There
are three types of Schedulers available in YARN: FIFO [First In, First Out] schedulers, capacity
schedulers, and Fair schedulers. Out of these clusters to run large jobs executed promptly, it’s better to
use Capacity and Fair Schedulers.
Node Manager
The Node Manager works as a slave installed at each node and functions as a monitoring and reporting
agent for the Resource Manager. It also transmits the health status of each node to the Resource Manager
and offers resources to the cluster.
It is responsible for monitoring resource usage by individual containers and reporting it to the Resource
manager. The Node Manager can also kill or destroy the container if it receives a command from the
Resource Manager to do so.
It also monitors the usage of resources, performs log Management, and helps in creating container
processes and executing them on the request of the application master.
Now we shall discuss the components of Node Manager:
Containers
Containers are a fraction of Node Manager capacity, whose responsibility is to provide physical
resources like a disk space on a single node. All of the actual processing takes place inside the container.
An application can use a specific amount of memory from the CPU only after permission has been
granted by the container.
Application Master
Application master is the framework-specific process that negotiates resources for a single application.
It works along with the Node Manager and monitors the execution of the task. Application Master also
sends heartbeats to the resource manager which provides a report after the application has started.
Application Master requests the container in the node manager by launching CLC (Container Launch
Context) which takes care of all the resources required an application needs to execute.
HBase
HBase is a top-level Apache project written in java which fulfills the need to read and write data in real-
time. It provides a simple interface to the distributed data. It can be accessed by Apache Hive, Apache
Pig, MapReduce, and store information in HDFS.
HDFS-vs-HBase
HBase architecture has 3 main components: HMaster, Region Server, Zookeeper.](https://image.slidesharecdn.com/bigdatamodule3-231125055434-4bbf00ec/75/BIGDATA-MODULE-3-pdf-13-2048.jpg)