Downloaded 85 times




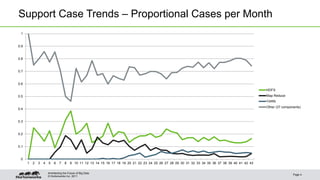
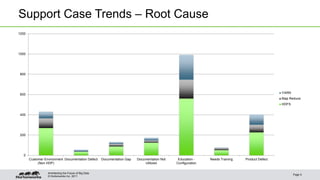











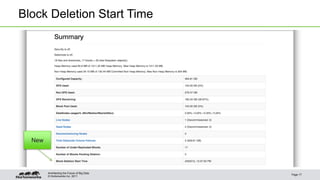








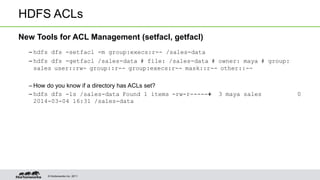












This document outlines best practices for Hadoop operations, emphasizing the analysis of support case trends, optimal configuration, and software improvements. Key learnings include leveraging HDFS access control lists and snapshots to enhance operational efficiency and safeguard data. The guide suggests various configurations for hardware, JVM tuning, and monitoring to prevent common operational issues.













































































