Downloaded 66 times

















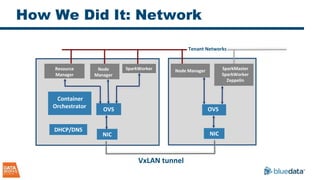




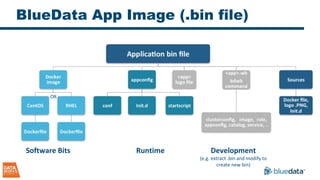
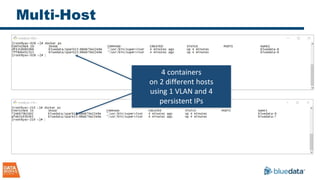



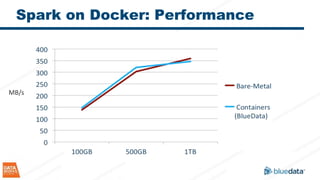











The document discusses the implementation and challenges of running Apache Spark on Docker containers, emphasizing the benefits of agility, flexibility, and efficient resource utilization in big data environments. It highlights various deployment models, key design decisions, and performance considerations involved in integrating Docker with Spark for enterprise-level applications. Additionally, it cautions about potential pitfalls and suggests that a turnkey solution, like that offered by Bluedata, can mitigate infrastructure complexities.













































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








