Downloaded 245 times



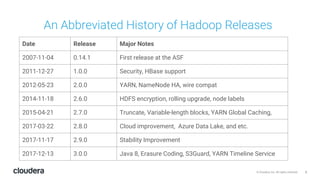




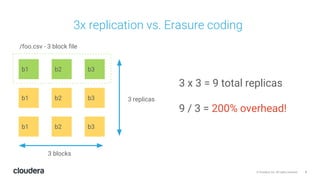



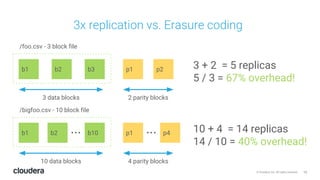


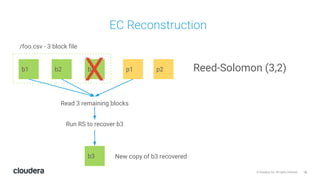


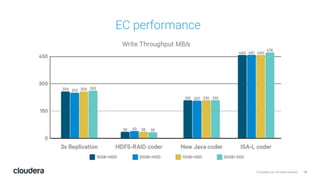
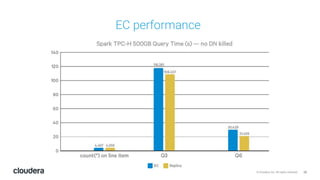
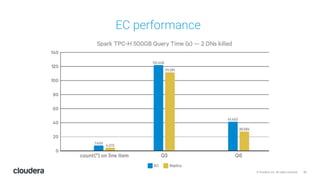




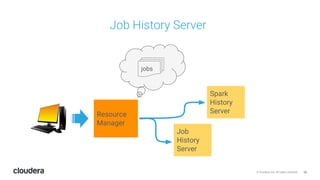
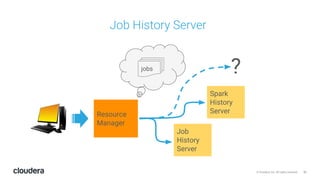

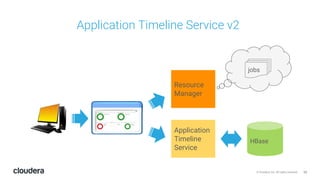
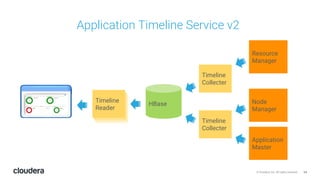
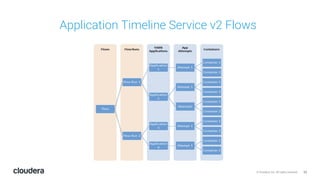
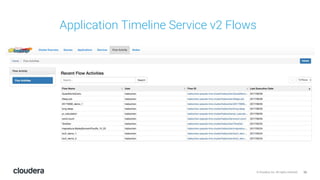

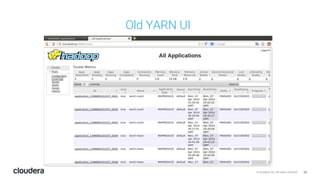





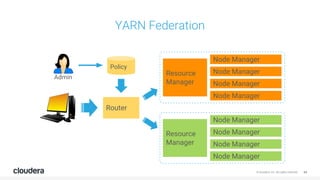










The document discusses the release and key features of Hadoop 3.0, which includes enhancements such as HDFS erasure coding for improved storage efficiency, and a new YARN UI for better visibility into cluster operation. It highlights the motivation for this upgrade, the timeline of its development, and mentions compatibility with previous versions. Additionally, it covers various optimizations and improvements in resource management and operational efficiency.



























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Hadoop Meetup] Apache Hadoop 3 community update - Rohith Sharma](https://cdn.slidesharecdn.com/ss_thumbnails/apachehadoop3communityupdate-rohith-171222071357-thumbnail.jpg?width=640&height=640&fit=bounds)




































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

















