Downloaded 151 times
















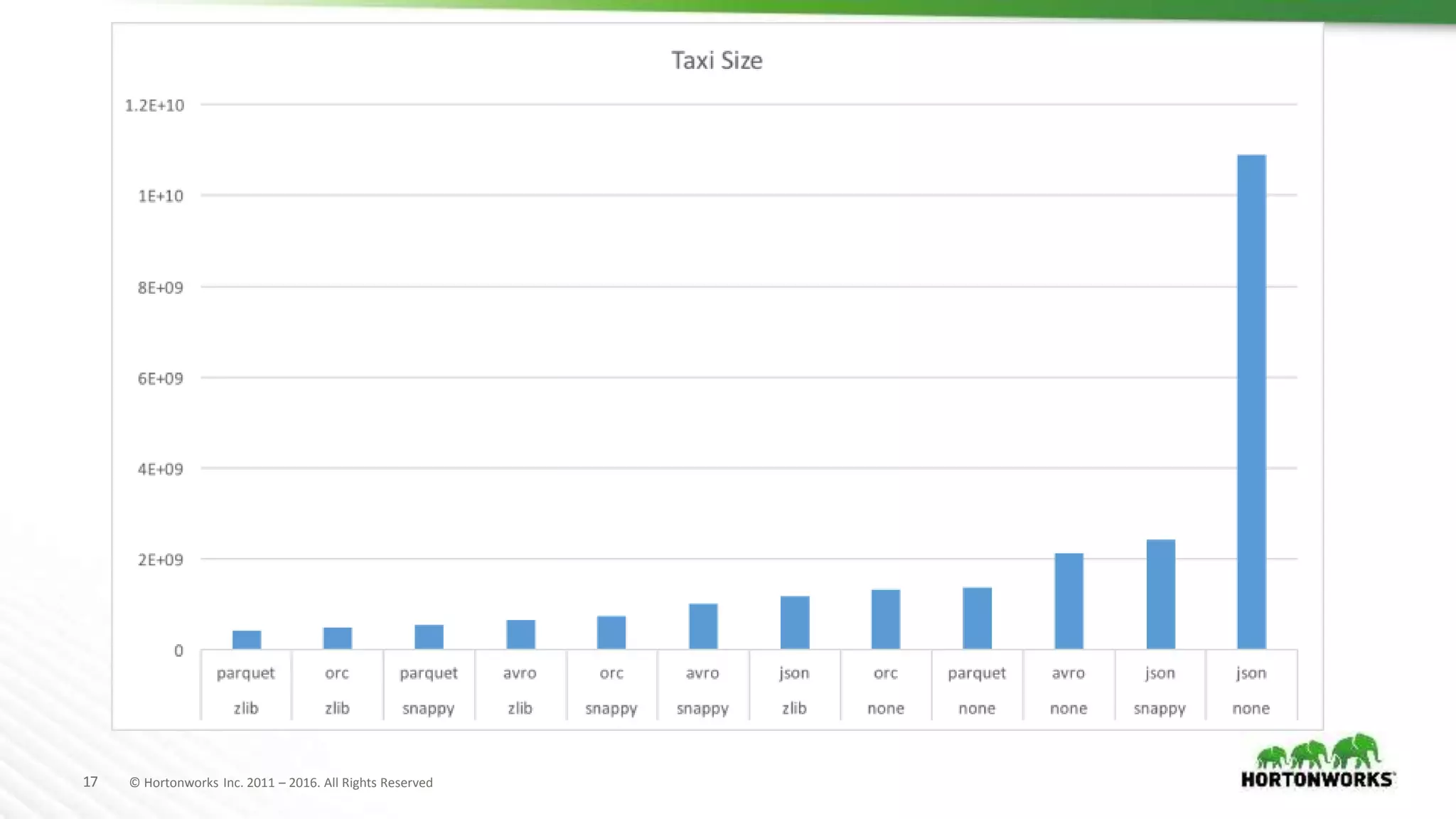

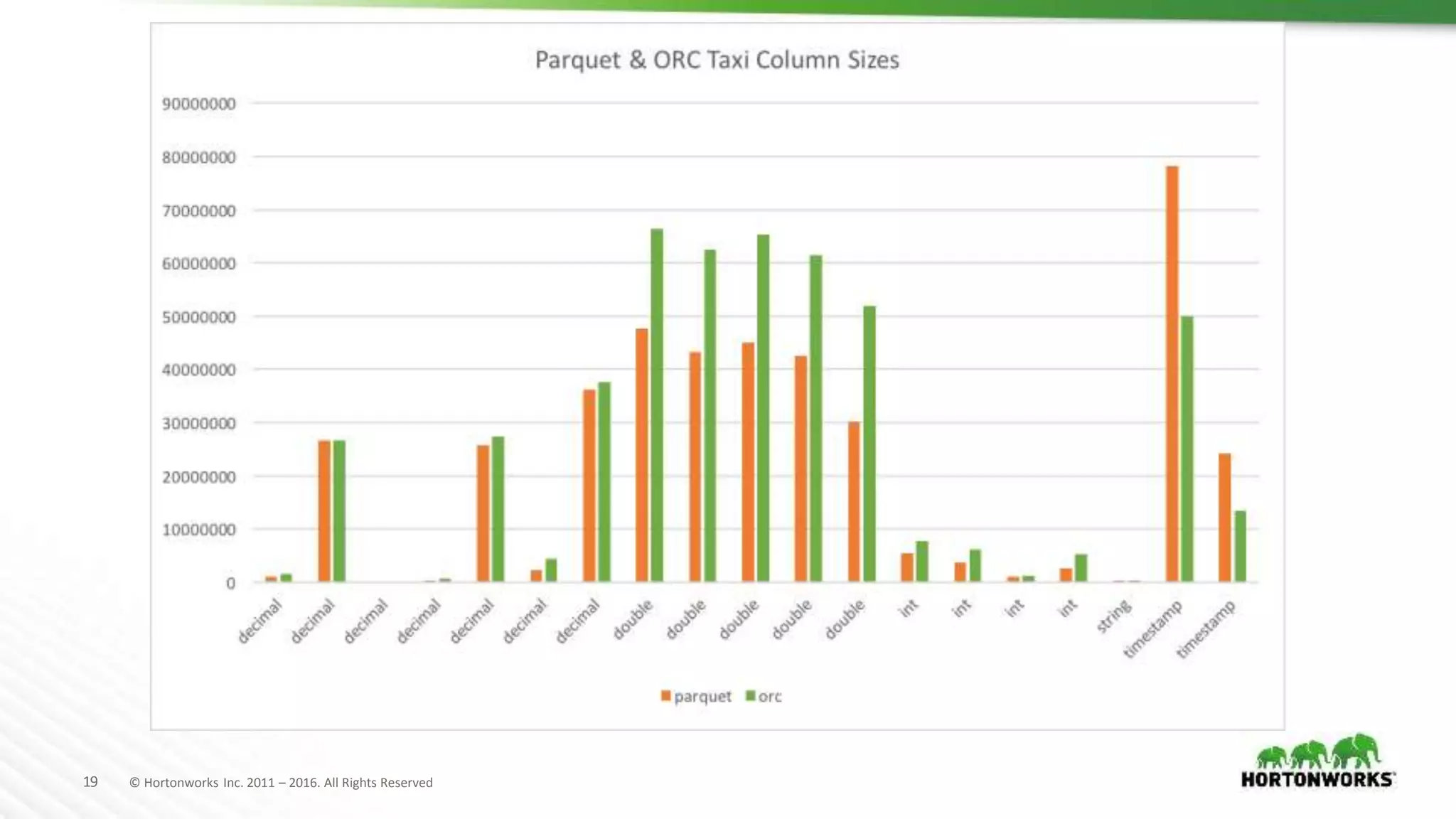
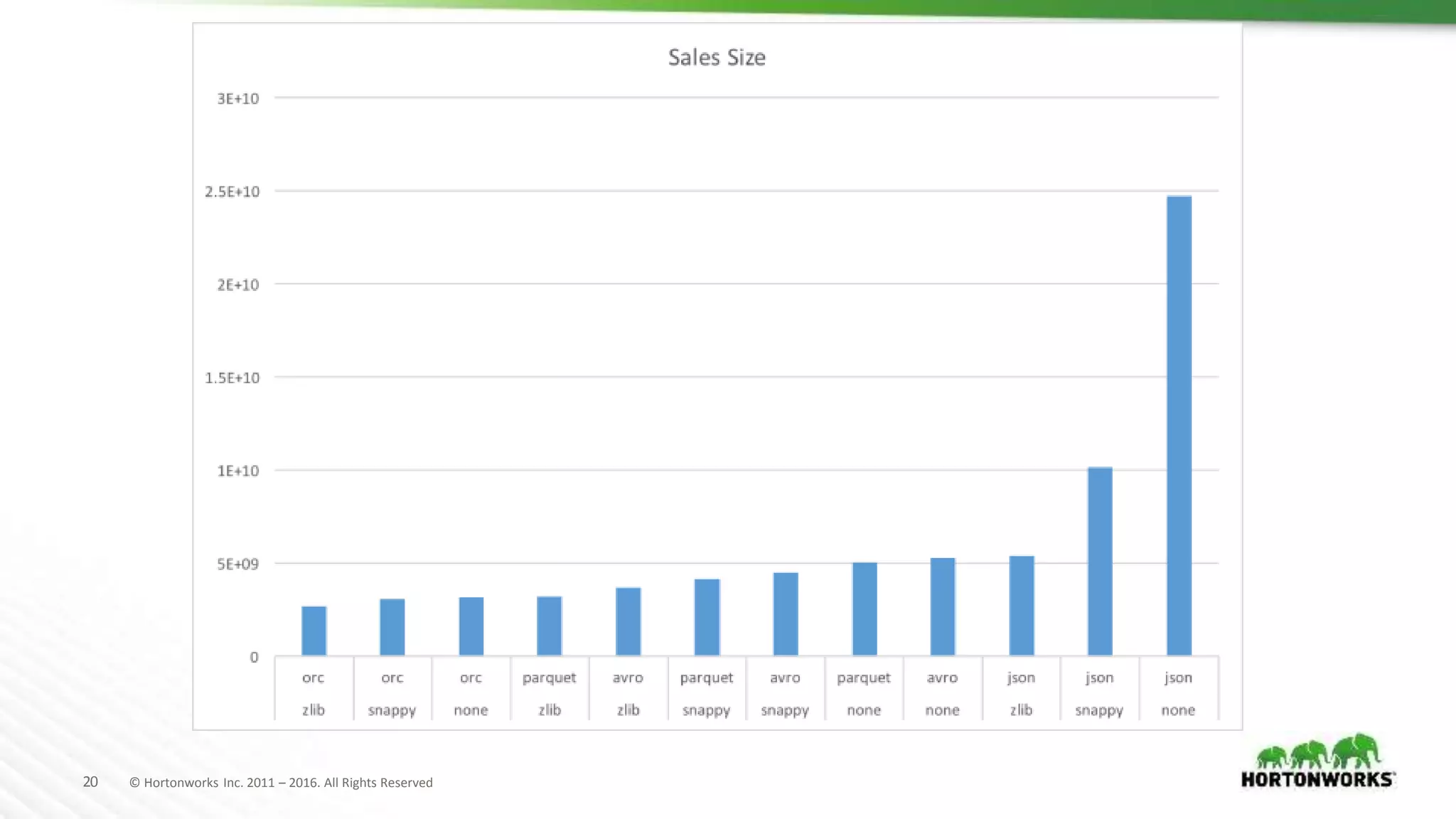

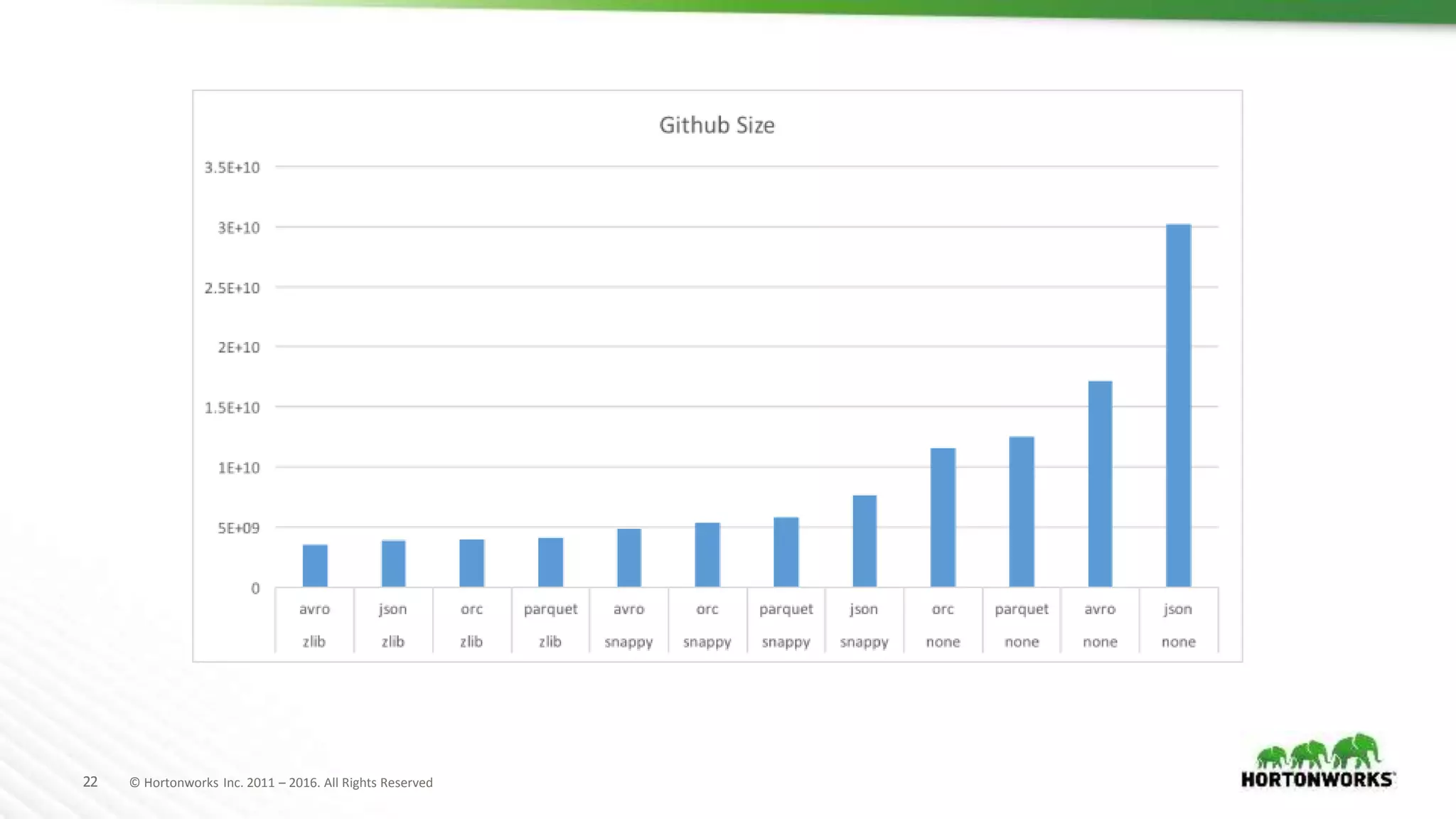



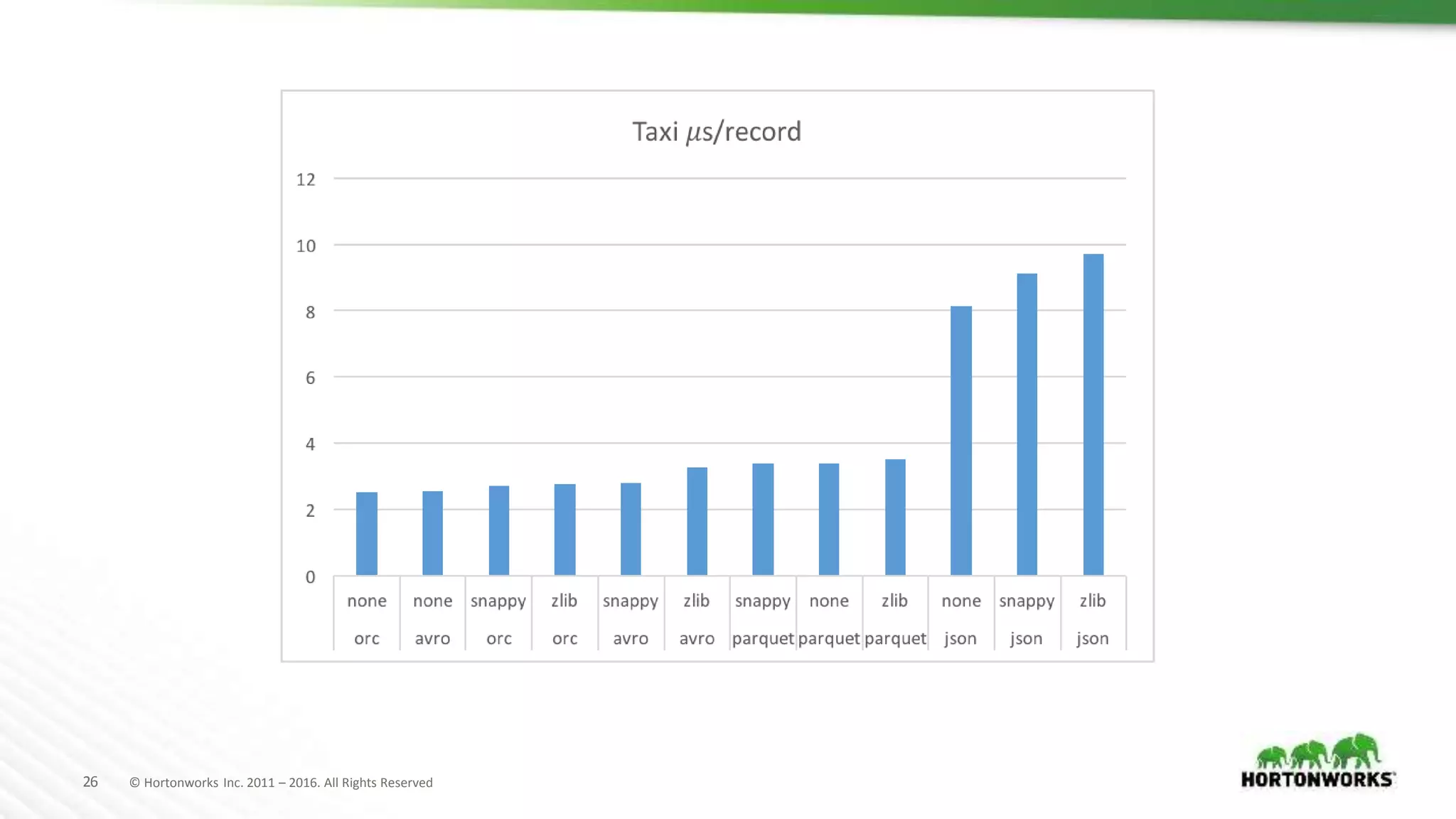

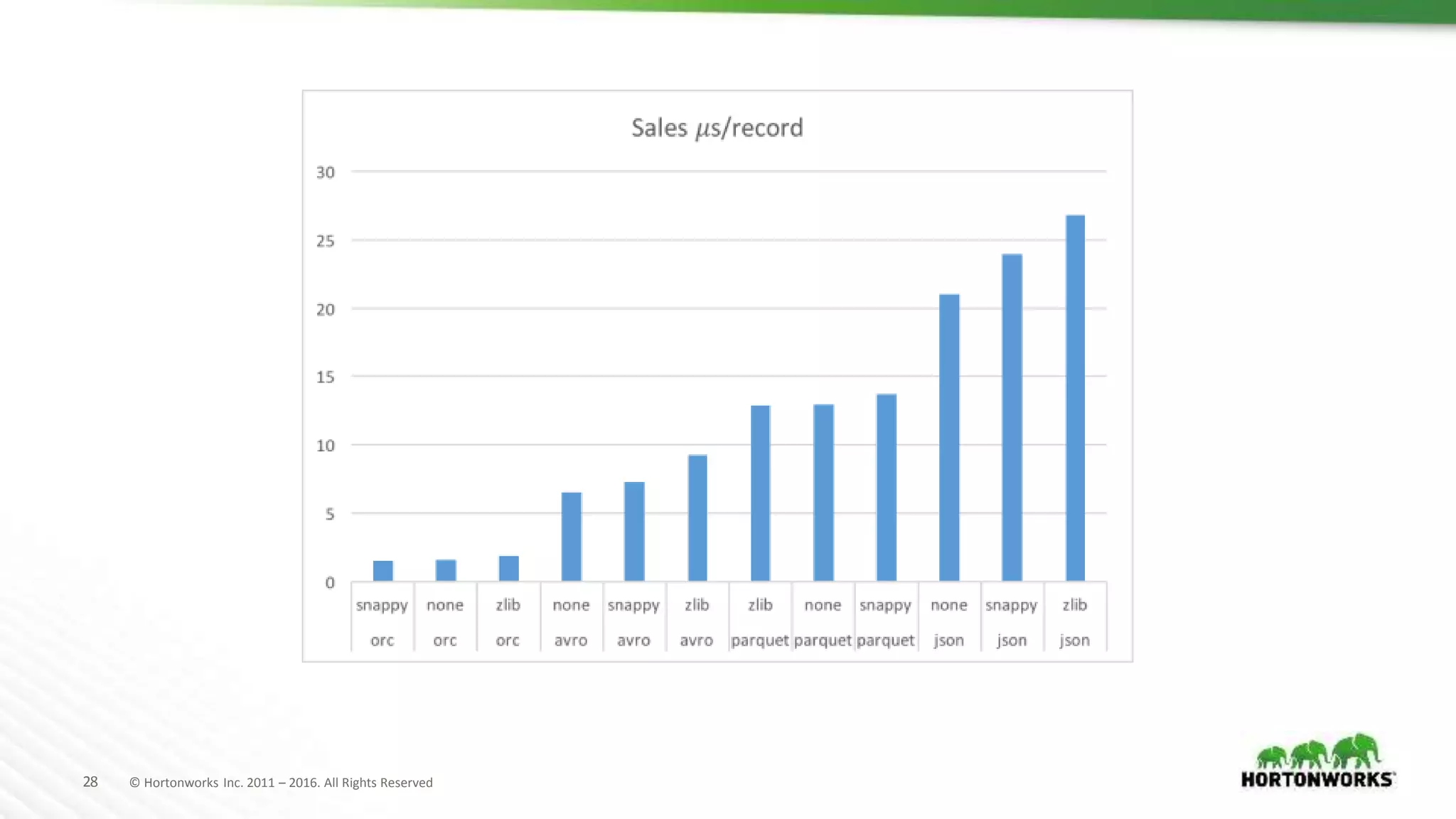

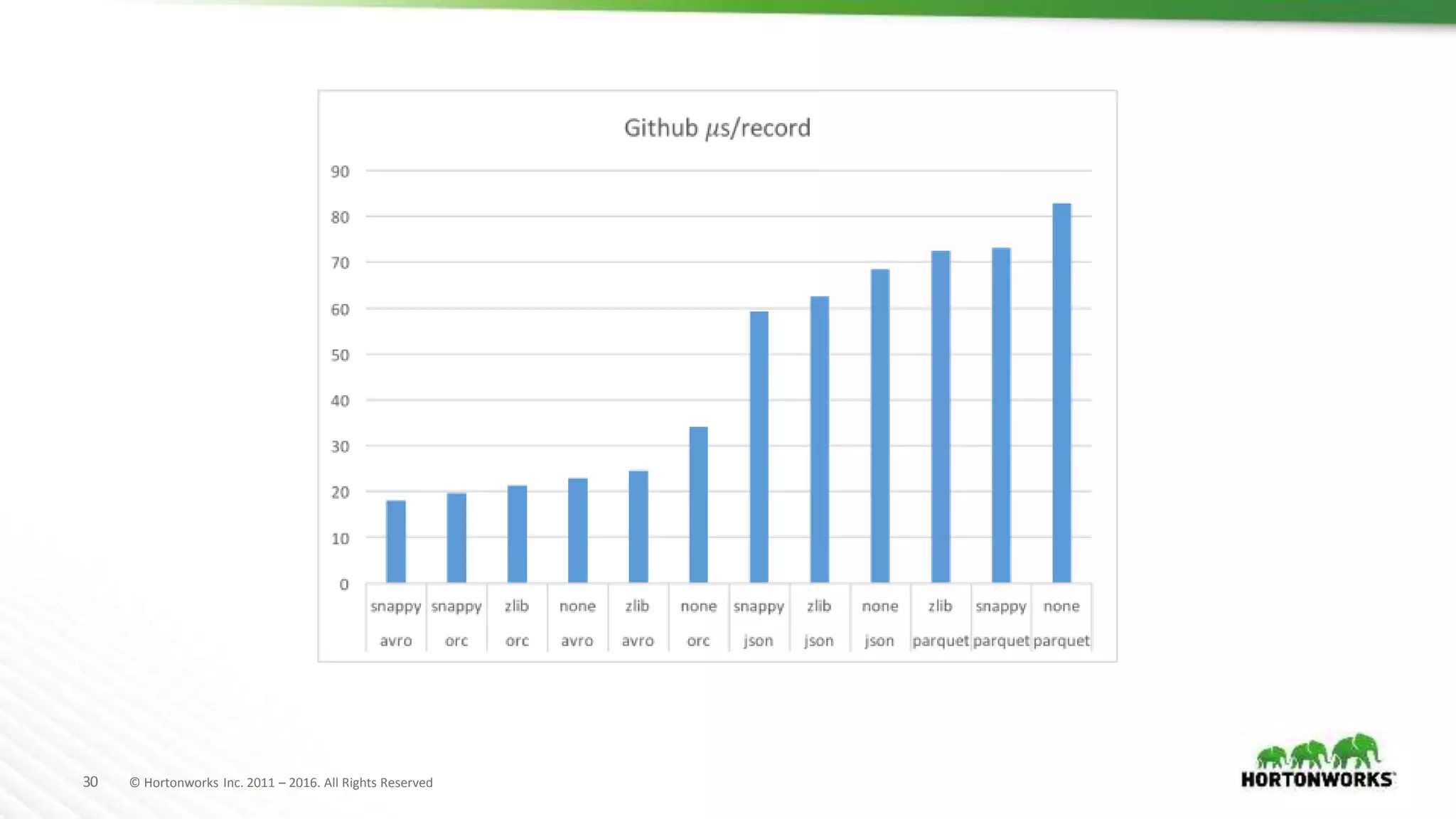

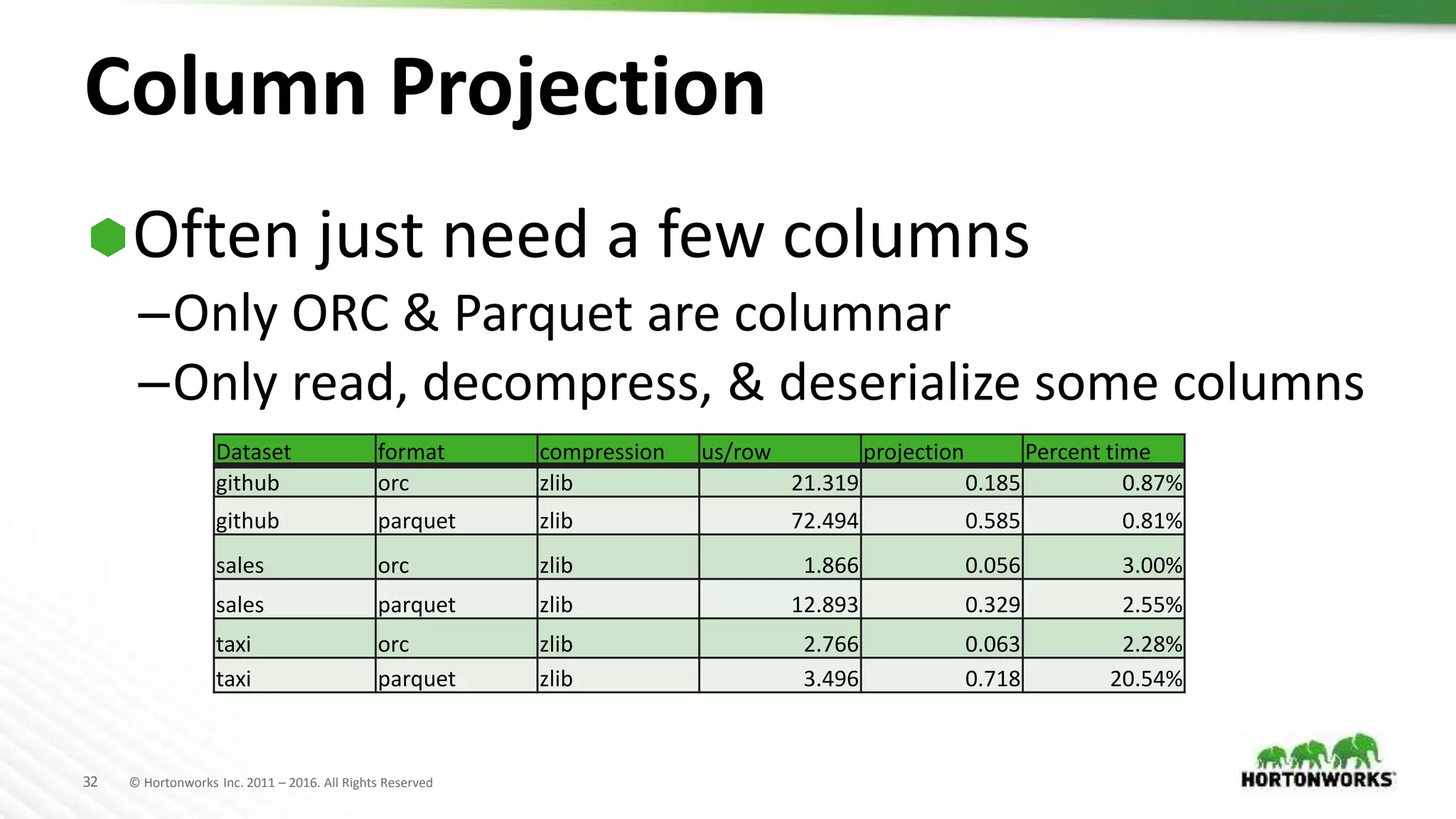









The document evaluates various file formats used in Hadoop, including Avro, JSON, ORC, and Parquet, focusing on their performance, compression, and use cases. It presents findings from benchmarks using real datasets such as NYC taxi data and GitHub logs, highlighting ORC and Parquet's advantages in read performance and space efficiency. The document concludes with recommendations for selecting file formats based on data characteristics and performance tests.



























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






