Downloaded 63 times









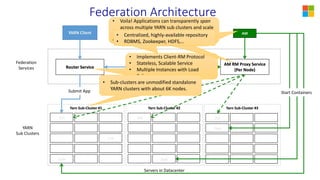
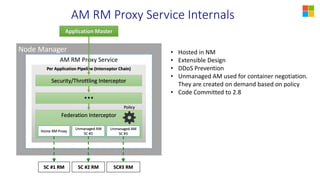

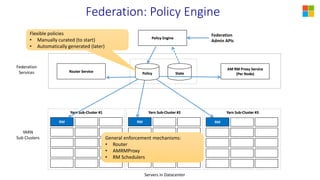

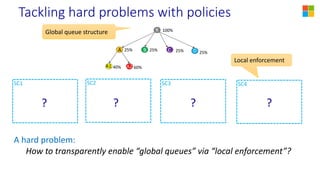
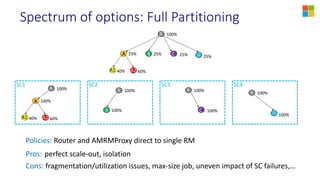
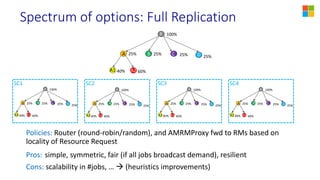
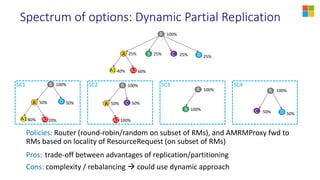



This document discusses YARN federation, which allows multiple YARN clusters to be connected together. It summarizes: - YARN is used at Microsoft for resource management but faces challenges of large scale and diverse workloads. Federation aims to address this. - The federation architecture connects multiple independent YARN clusters through centralized services for routing, policies, and state. Applications are unaware and can seamlessly run across clusters. - Federation policies determine how work is routed and scheduled across clusters, balancing objectives like load balancing, scaling, fairness, and isolation. A spectrum of policy options is discussed from full partitioning to full replication to dynamic partial replication. - A demo is presented showing a job running across



















































![[Hadoop Meetup] Yarn at Microsoft - The challenges of scale](https://cdn.slidesharecdn.com/ss_thumbnails/yarnatmicrosoft-171222065628-thumbnail.jpg?width=640&height=640&fit=bounds)























































