Downloaded 40 times









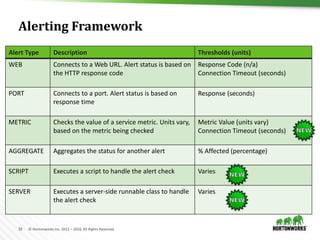
![12 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
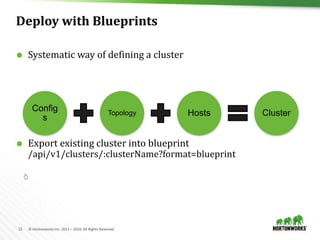
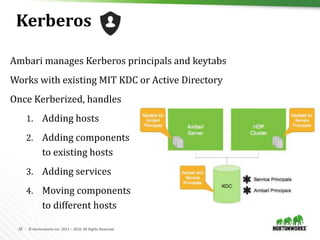
Create a cluster with Blueprints
{
"configurations" : [
{
"hdfs-site" : {
"dfs.datanode.data.dir" : "/hadoop/1,
/hadoop/2,/hadoop/3"
}
}
],
"host_groups" : [
{
"name" : "master-host",
"components" : [
{ "name" : "NAMENODE” },
{ "name" : "RESOURCEMANAGER” },
…
],
"cardinality" : "1"
},
{
"name" : "worker-host",
"components" : [
{ "name" : "DATANODE" },
{ "name" : "NODEMANAGER” },
…
],
"cardinality" : "1+"
},
],
"Blueprints" : {
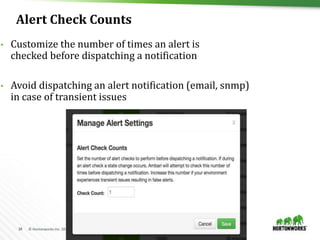
"stack_name" : "HDP",
"stack_version" : "2.5"
}
}
{
"blueprint" : "my-blueprint",
"host_groups" :[
{
"name" : "master-host",
"hosts" : [
{
"fqdn" : "master001.ambari.apache.org"
}
]
},
{
"name" : "worker-host",
"hosts" : [
{
"fqdn" : "worker001.ambari.apache.org"
},
{
"fqdn" : "worker002.ambari.apache.org"
},
…
{
"fqdn" : "worker099.ambari.apache.org"
}
]
}
]
}
1. POST /api/v1/blueprints/my-blueprint 2. POST /api/v1/clusters/my-cluster](https://image.slidesharecdn.com/1500jayushluniyav1-161031165141/85/Streamline-Hadoop-DevOps-with-Apache-Ambari-12-320.jpg)
![13 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Create a cluster with Blueprints
{
"configurations" : [
{
"hdfs-site" : {
"dfs.datanode.data.dir" : "/hadoop/1,
/hadoop/2,/hadoop/3"
}
}
],
"host_groups" : [
{
"name" : "master-host",
"components" : [
{ "name" : "NAMENODE” },
{ "name" : "RESOURCEMANAGER” },
…
],
"cardinality" : "1"
},
{
"name" : "worker-host",
"components" : [
{ "name" : "DATANODE" },
{ "name" : "NODEMANAGER” },
…
],
"cardinality" : "1+"
},
],
"Blueprints" : {
"stack_name" : "HDP",
"stack_version" : "2.5"
}
}
{
"blueprint" : "my-blueprint",
"host_groups" :[
{
"name" : "master-host",
"hosts" : [
{
"fqdn" : "master001.ambari.apache.org"
}
]
},
{
"name" : "worker-host",
"hosts" : [
{
"fqdn" : "worker001.ambari.apache.org"
},
{
"fqdn" : "worker002.ambari.apache.org"
},
…
{
"fqdn" : "worker099.ambari.apache.org"
}
]
}
]
}
1. POST /api/v1/blueprints/my-blueprint 2. POST /api/v1/clusters/my-cluster](https://image.slidesharecdn.com/1500jayushluniyav1-161031165141/85/Streamline-Hadoop-DevOps-with-Apache-Ambari-13-320.jpg)
![14 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Create a cluster with Blueprints
{
"configurations" : [
{
"hdfs-site" : {
"dfs.datanode.data.dir" : "/hadoop/1,
/hadoop/2,/hadoop/3"
}
}
],
"host_groups" : [
{
"name" : "master-host",
"components" : [
{ "name" : "NAMENODE” },
{ "name" : "RESOURCEMANAGER” },
…
],
"cardinality" : "1"
},
{
"name" : "worker-host",
"components" : [
{ "name" : "DATANODE" },
{ "name" : "NODEMANAGER” },
…
],
"cardinality" : "1+"
},
],
"Blueprints" : {
"stack_name" : "HDP",
"stack_version" : "2.5"
}
}
{
"blueprint" : "my-blueprint",
"host_groups" :[
{
"name" : "master-host",
"hosts" : [
{
"fqdn" : "master001.ambari.apache.org"
}
]
},
{
"name" : "worker-host",
"hosts" : [
{
"fqdn" : "worker001.ambari.apache.org"
},
{
"fqdn" : "worker002.ambari.apache.org"
},
…
{
"fqdn" : "worker099.ambari.apache.org"
}
]
}
]
}
1. POST /api/v1/blueprints/my-blueprint 2. POST /api/v1/clusters/my-cluster](https://image.slidesharecdn.com/1500jayushluniyav1-161031165141/85/Streamline-Hadoop-DevOps-with-Apache-Ambari-14-320.jpg)
![15 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Create a cluster with Blueprints
{
"configurations" : [
{
"hdfs-site" : {
"dfs.datanode.data.dir" : "/hadoop/1,
/hadoop/2,/hadoop/3"
}
}
],
"host_groups" : [
{
"name" : "master-host",
"components" : [
{ "name" : "NAMENODE” },
{ "name" : "RESOURCEMANAGER” },
…
],
"cardinality" : "1"
},
{
"name" : "worker-host",
"components" : [
{ "name" : "DATANODE" },
{ "name" : "NODEMANAGER” },
…
],
"cardinality" : "1+"
},
],
"Blueprints" : {
"stack_name" : "HDP",
"stack_version" : "2.5"
}
}
{
"blueprint" : "my-blueprint",
"host_groups" :[
{
"name" : "master-host",
"hosts" : [
{
"fqdn" : "master001.ambari.apache.org"
}
]
},
{
"name" : "worker-host",
"hosts" : [
{
"fqdn" : "worker001.ambari.apache.org"
},
{
"fqdn" : "worker002.ambari.apache.org"
},
…
{
"fqdn" : "worker099.ambari.apache.org"
}
]
}
]
}
1. POST /api/v1/blueprints/my-blueprint 2. POST /api/v1/clusters/my-cluster](https://image.slidesharecdn.com/1500jayushluniyav1-161031165141/85/Streamline-Hadoop-DevOps-with-Apache-Ambari-15-320.jpg)

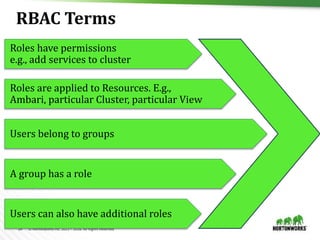
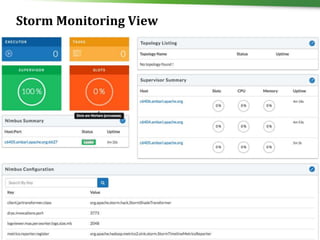
![17 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
POST /api/v1/clusters/MyCluster/hosts
[
{
"blueprint" : "single-node-hdfs-test2",
"host_groups" :[
{
"host_group" : "slave",
"host_count" : 3,
"host_predicate" : "Hosts/cpu_count>1”
}, {
"host_group" : "super-slave",
"host_count" : 5,
"host_predicate" : "Hosts/cpu_count>2&
Hosts/total_mem>3000000"
}
]
}
]
Blueprint Host Discovery](https://image.slidesharecdn.com/1500jayushluniyav1-161031165141/85/Streamline-Hadoop-DevOps-with-Apache-Ambari-17-320.jpg)










The document discusses how Apache Ambari can be used to streamline Hadoop DevOps. It describes how Ambari can be used to provision, manage, and monitor Hadoop clusters. It highlights new features in Ambari 2.4 like support for additional services, role-based access control, management packs, and Grafana integration. It also covers how Ambari supports automated deployment and cluster management using blueprints.


























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















