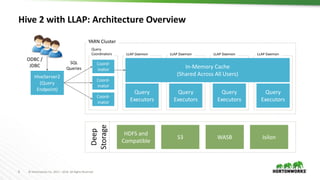
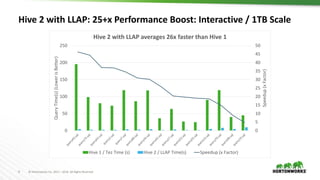
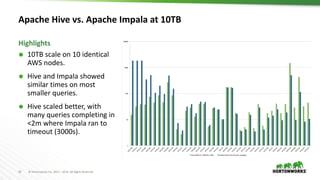
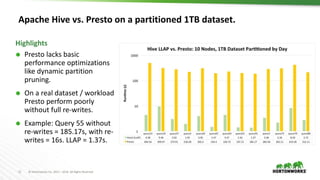
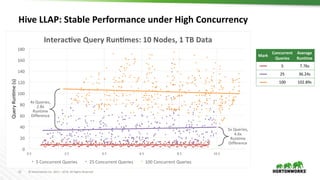
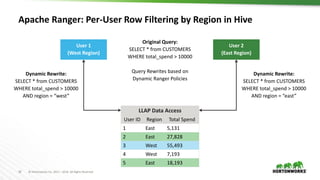
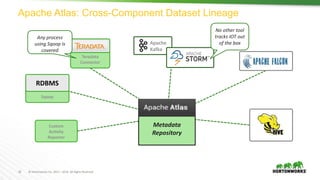
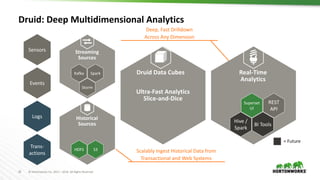
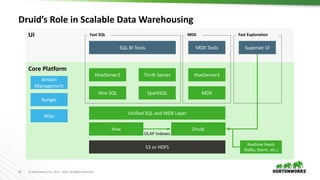
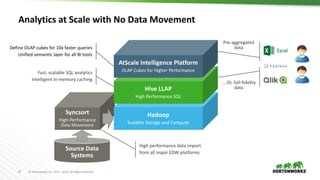
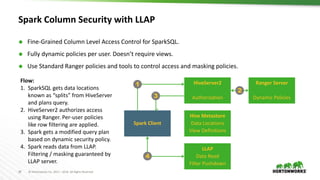
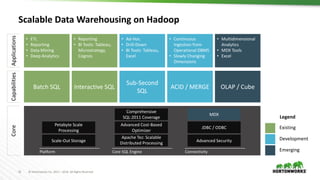
The document discusses scalable data warehousing on Hadoop, highlighting the capabilities and performance of Apache Hive, which supports extensive SQL functionalities and is designed for high efficiency at a petabyte scale. It addresses key features such as security, data governance, and various optimization strategies that enhance performance, including LLAP for faster query responses. Furthermore, it explores integration with BI tools, and the role of additional technologies like Apache Druid and Apache Atlas in managing and analyzing large datasets.