Downloaded 46 times





![10 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Backward compatibility
New version of a schema would be compatible with earlier version of that schema.
Data written from earlier version of the schema, can be read with a new version of the
schema.
V1
{
"type": "record",
"name": "book",
"namespace": "registry.example",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "color",
"type": "string",
"default": "blue"
}
]
}
V2
{
"type": "record",
"name": "book",
"namespace": "registry.example",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "color",
"type": "string",
"default": "blue"
},
{
"name": "pages",
"type": "int",
"default": -1
}
]
}](https://image.slidesharecdn.com/sriharshachintalapanischemaregistry8211setyourdatafree-170621203914/85/Schema-Registry-Set-Your-Data-Free-10-320.jpg)
![11 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Forward compatibility
Existing schema is compatible with future versions of the schema.
That means the data written from new version of the schema can still be read with old
version of the schema.
V1
{
"type": "record",
"name": "book",
"namespace": "registry.example",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "color",
"type": "string",
"default": "blue"
}
]
}
V2
{
"type": "record",
"name": "book",
"namespace": "registry.example",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "color",
"type": "string",
"default": "blue"
},
{
"name": "pages",
"type": "int"
}
]
}](https://image.slidesharecdn.com/sriharshachintalapanischemaregistry8211setyourdatafree-170621203914/85/Schema-Registry-Set-Your-Data-Free-11-320.jpg)
![12 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Both/Full compatibility
New version of the schema provides both backward and forward compatibilities.
V1
{
"type": "record",
"name": "book",
"namespace": "registry.example",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "color",
"type": "string",
"default": "blue"
}
]
}
V2
{
"type": "record",
"name": "book",
"namespace": "registry.example",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "color",
"type": "string",
"default": "blue"
},
{
"name": "pages",
"type": "int",
"default": -1
},
{
"name": "title",
"type" : "string",
"default": ""
}
]
}](https://image.slidesharecdn.com/sriharshachintalapanischemaregistry8211setyourdatafree-170621203914/85/Schema-Registry-Set-Your-Data-Free-12-320.jpg)
![13 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Schema composition
Schemas can be shared and reused
Inbuilt support in default serializer/deserializer to build effective schemas
{
"name": "account",
"namespace": "com.hortonworks.example.types",
"includeSchemas": [
{
"name": "utils”
}
],
"type": "record",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "id",
"type": "com.hortonworks.datatypes.uuid"
}
]
}
{
"name": "uuid",
"type": "record",
"namespace": "com.hortonworks.datatypes",
"doc": "A Universally Unique Identifier, in canonical form in
lowercase. This is generated from java.util.UUID Example:
de305d54-75b4-431b-adb2-eb6b9e546014",
"fields": [
{
"name": "value",
"type": "string",
"default": ""
}
]
}](https://image.slidesharecdn.com/sriharshachintalapanischemaregistry8211setyourdatafree-170621203914/85/Schema-Registry-Set-Your-Data-Free-13-320.jpg)










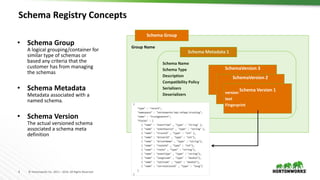
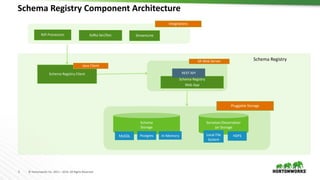
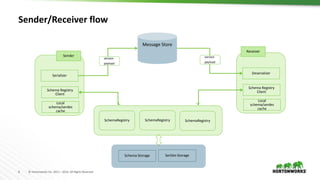
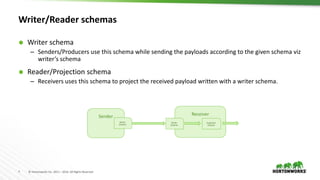
The document provides an overview of the Schema Registry developed by Hortonworks, emphasizing its role as a shared repository for managing reusable schemas that enhance data governance and operational efficiency. It explains key concepts, architecture components, integration with Kafka and NiFi, and compatibility policies, including backward and forward compatibility. Additionally, it outlines future roadmap features and security measures, promoting community engagement through contributions and open-source resources.






















































































