Downloaded 36 times








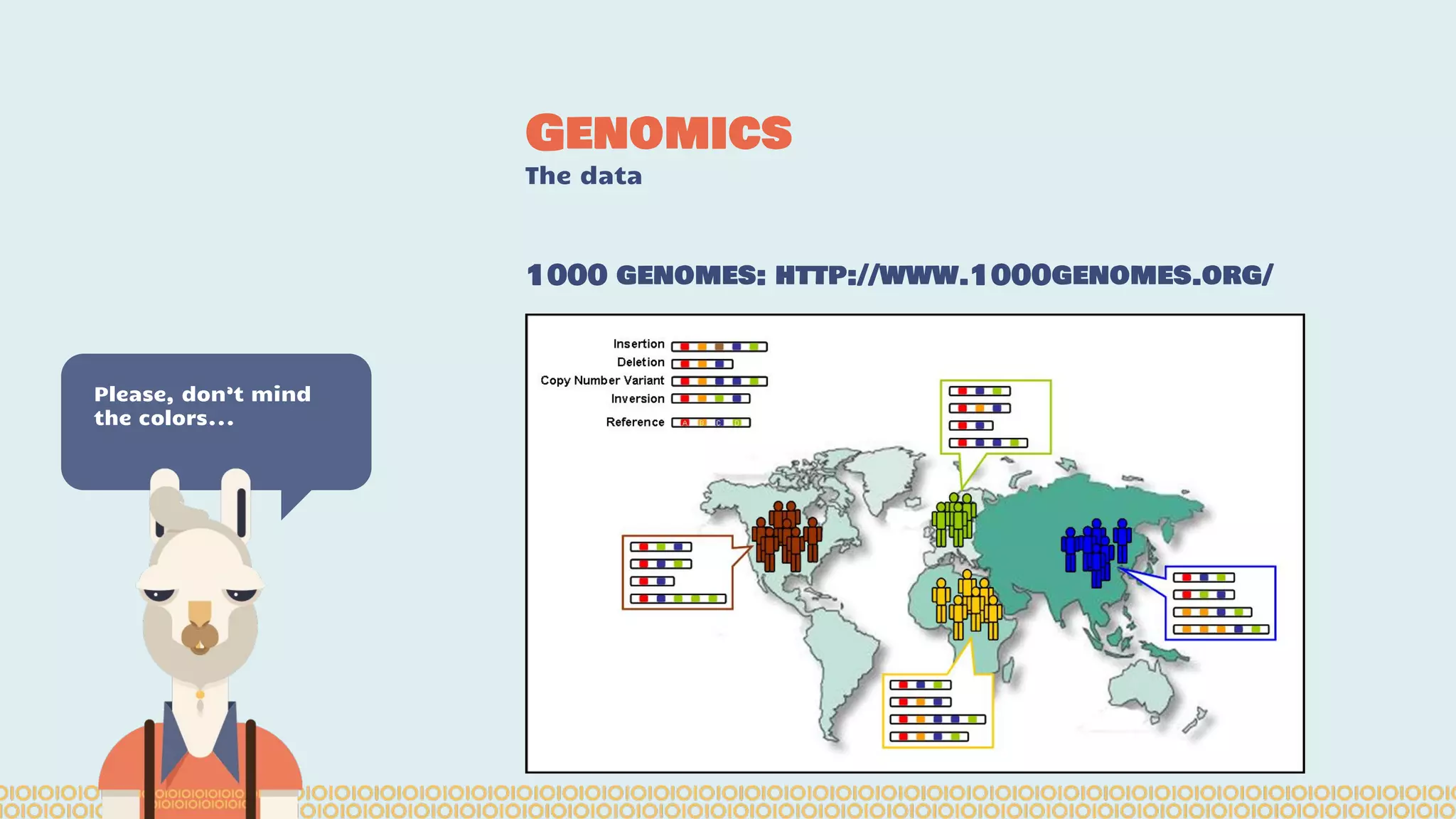
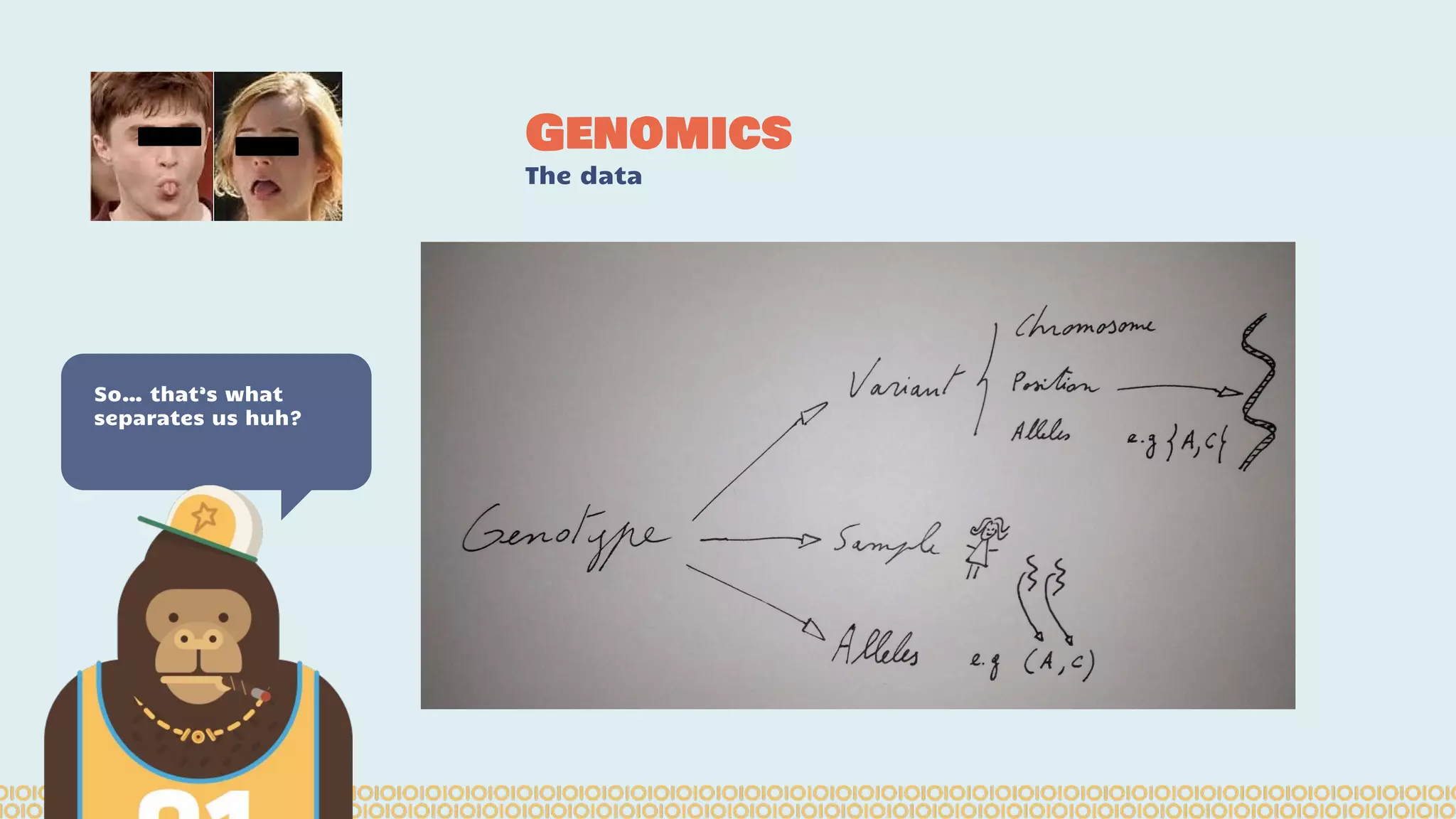




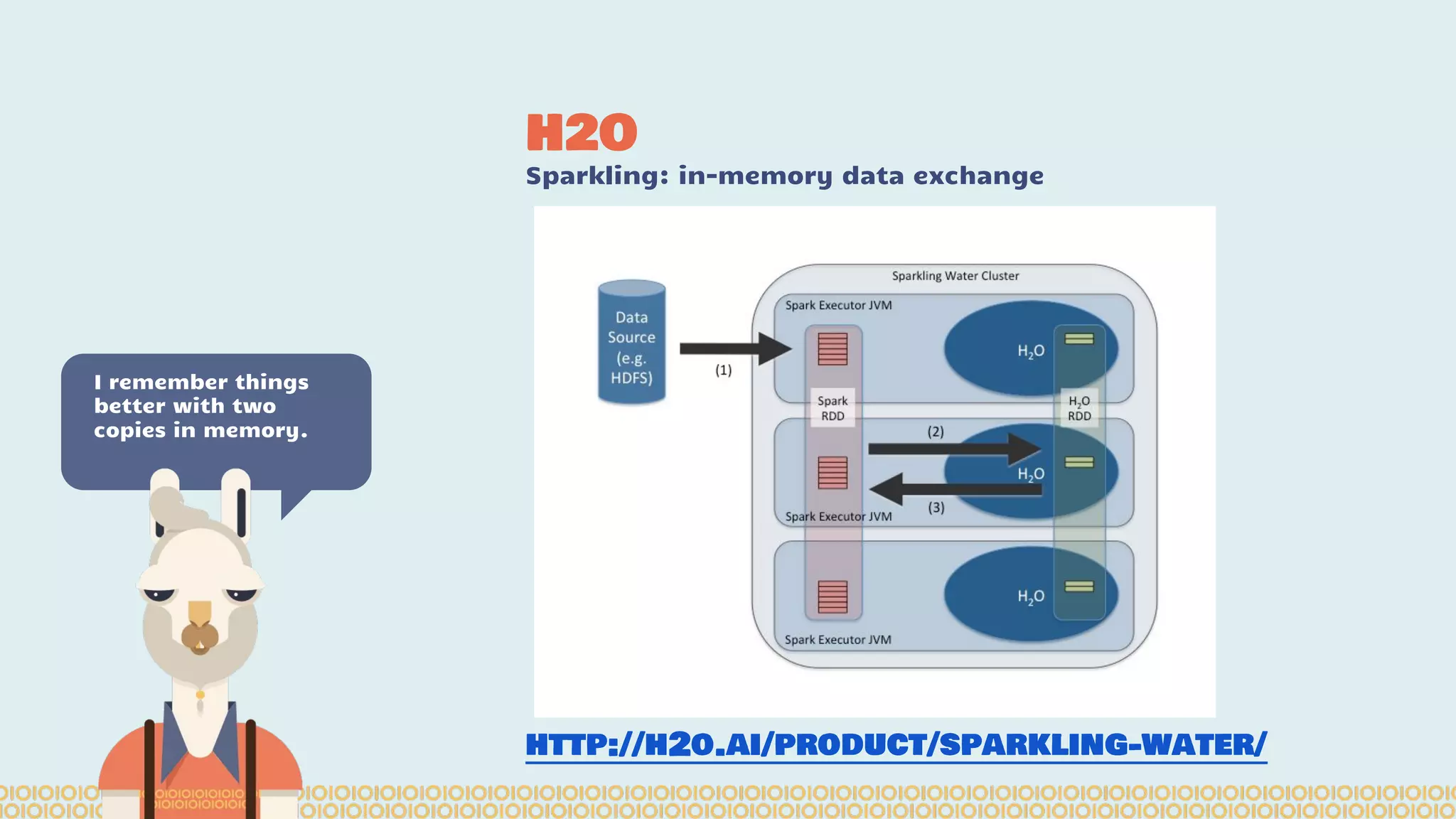


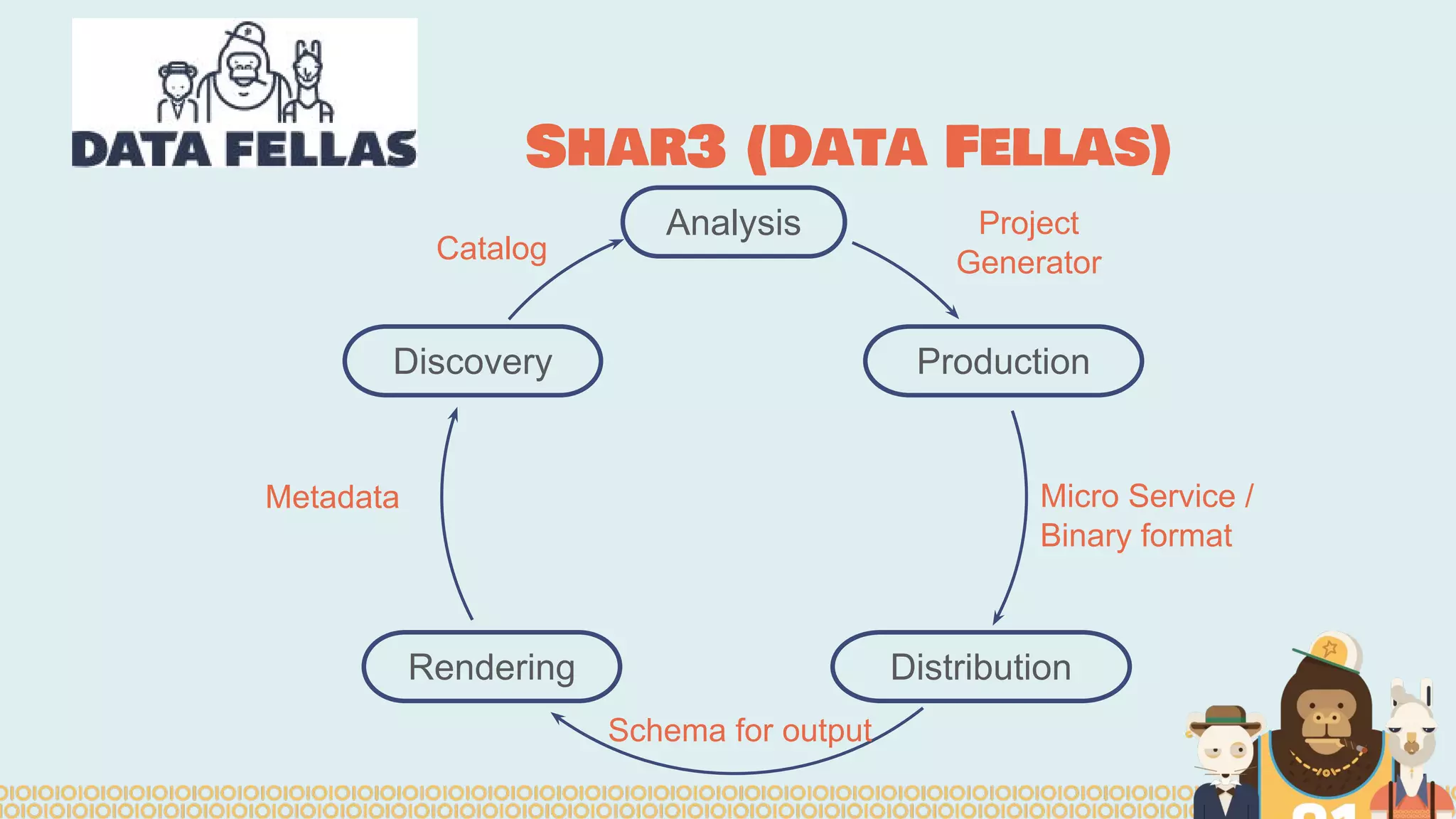



Spark is a distributed computing framework that can handle large scale data processing. The Spark notebook provides an interactive environment for working with Spark. ADAM is a data format and API for genomic data on Spark that optimizes for large datasets. Sparkling Water integrates H2O machine learning with Spark to enable techniques like deep learning on genomic data in a distributed manner using the Spark notebook. Data scientists and developers can collaborate using these tools to access, manipulate, and analyze massive genomic datasets.










































































































