Downloaded 97 times






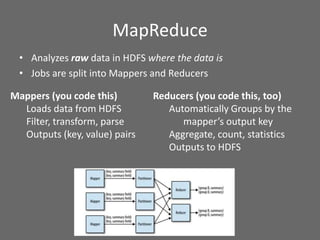















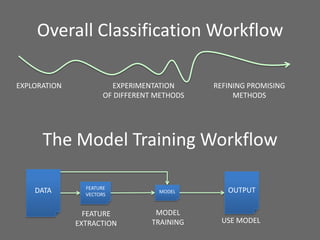

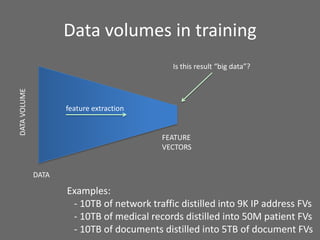




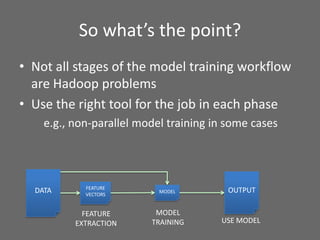















The document provides an overview of using Hadoop for data science, highlighting its distributed platform, data storage capabilities, and frameworks such as MapReduce, Pig, and Mahout. It discusses various data science tasks including data exploration, classification, natural language processing, and recommender systems, emphasizing Hadoop's ability to handle large datasets and unstructured data efficiently. The presentation also covers the integration of Hadoop with Python and other libraries for enhanced data processing and analysis tasks.





























































































