Downloaded 14 times






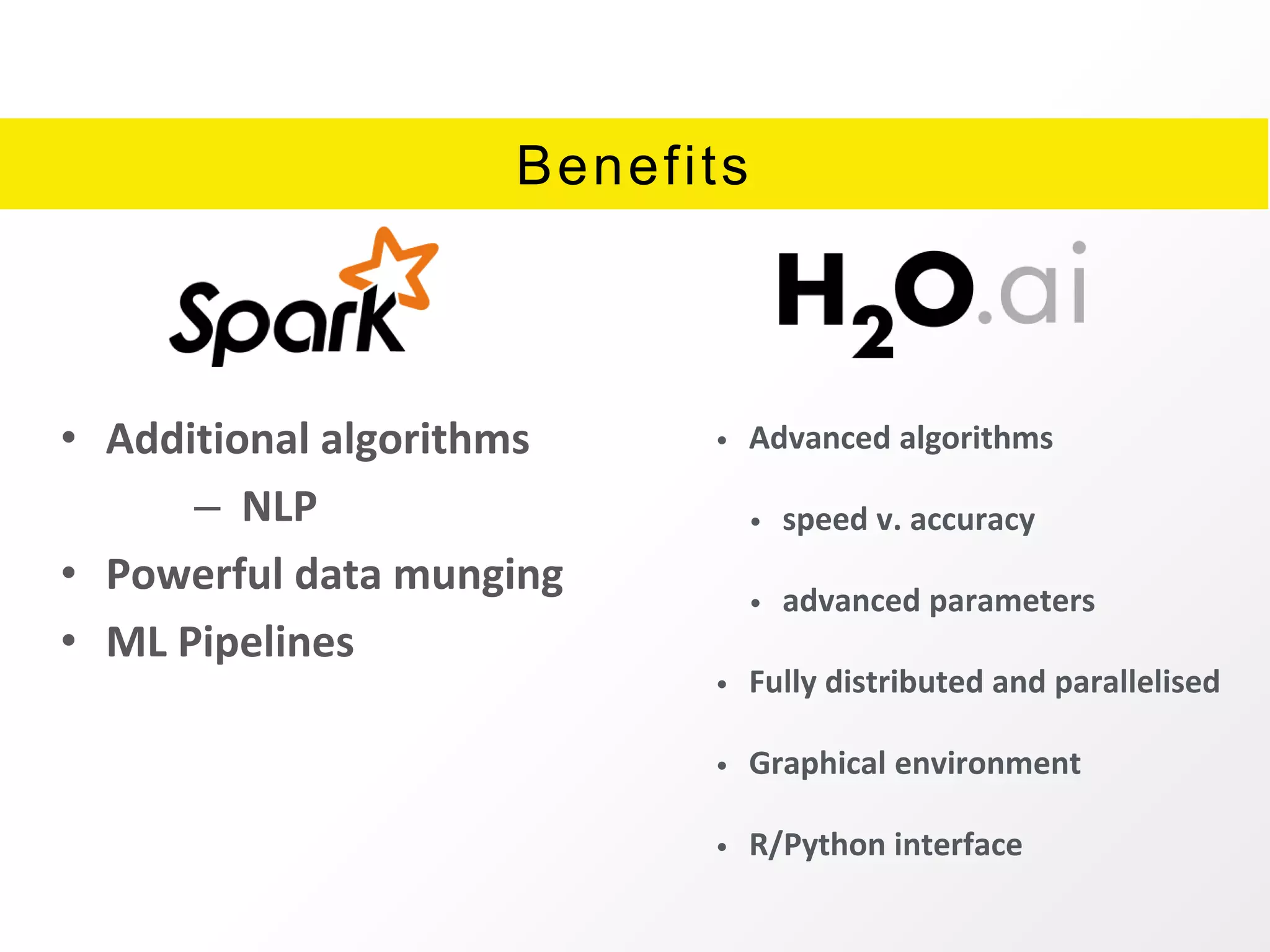

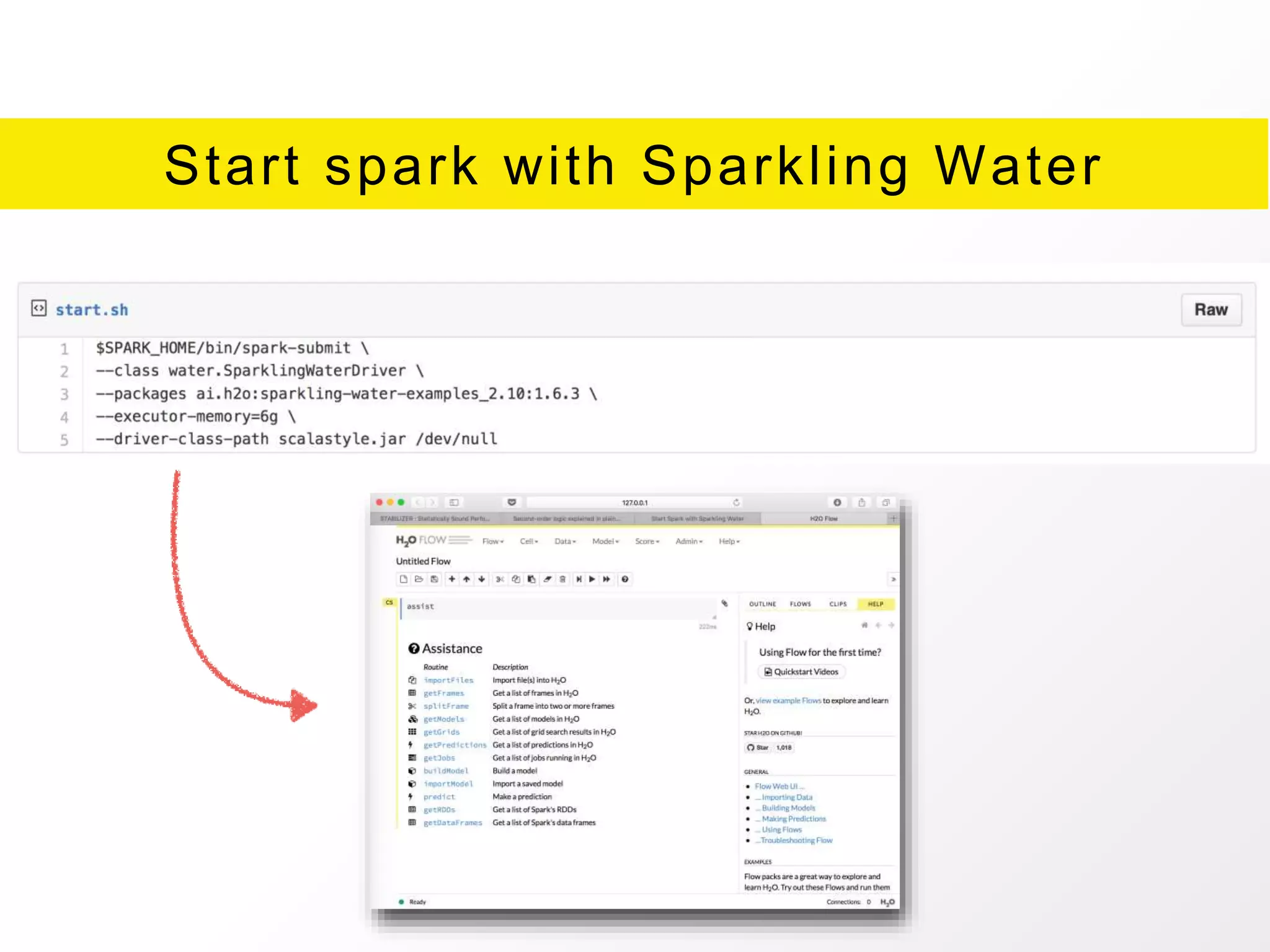
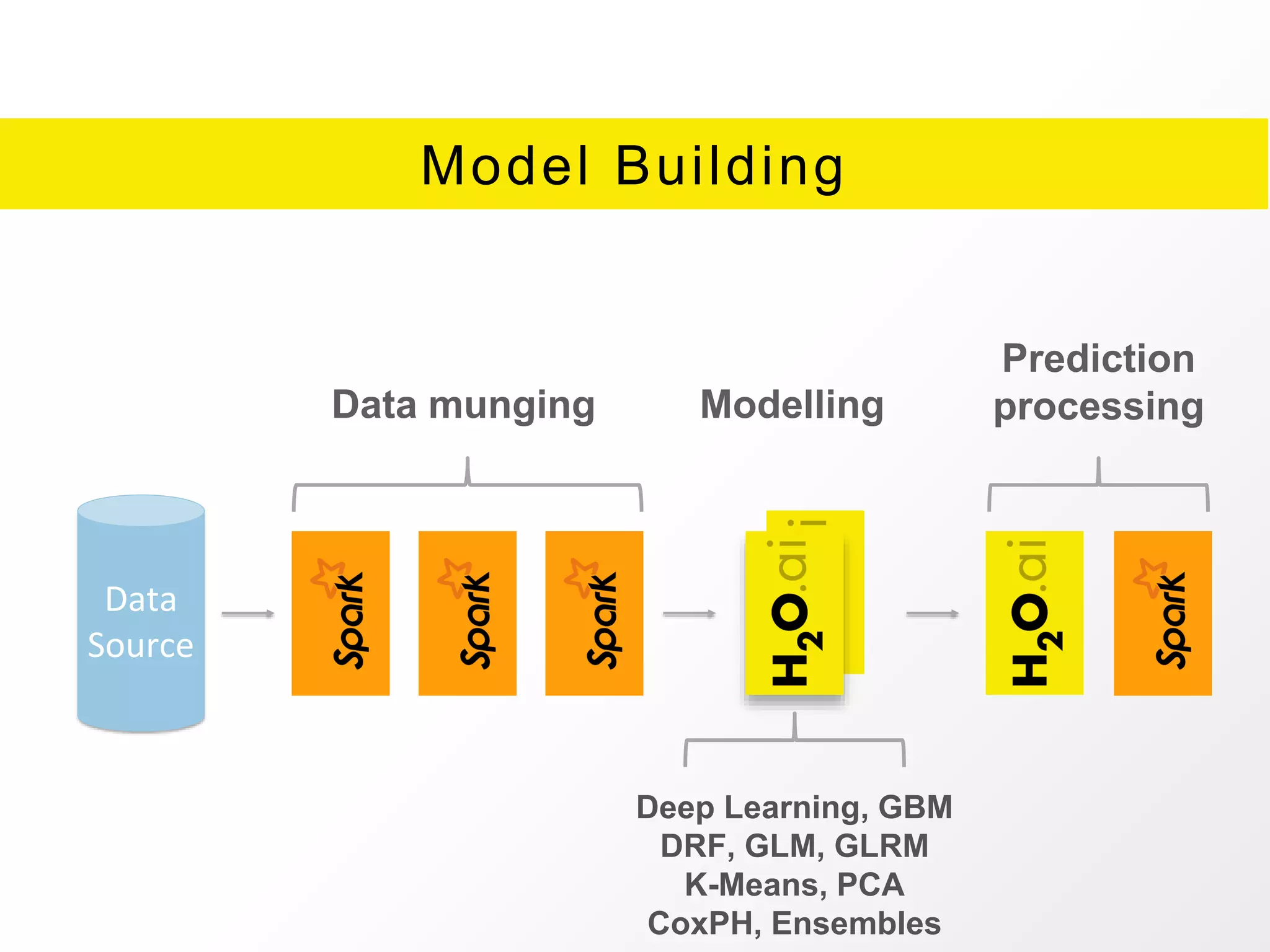
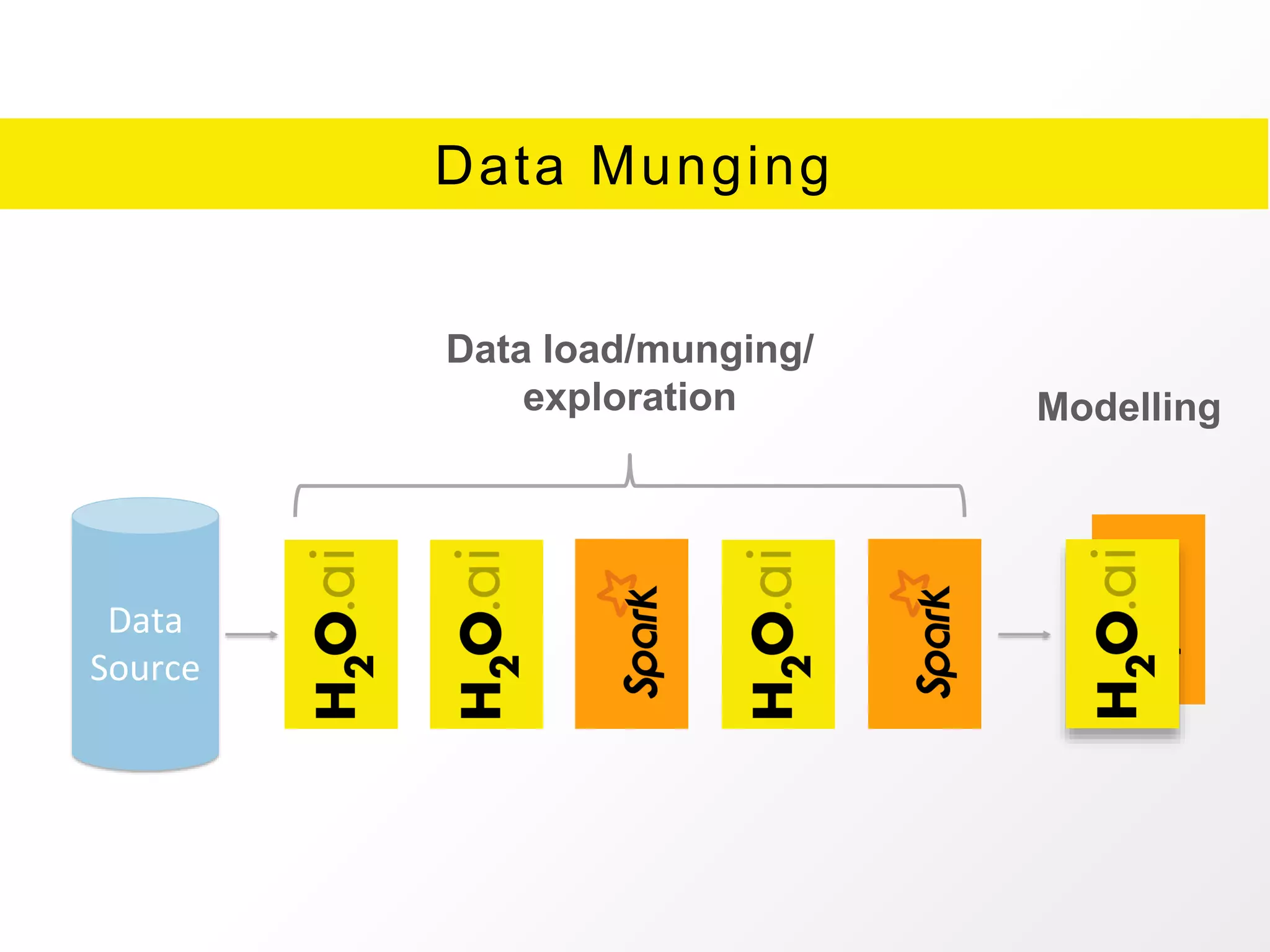
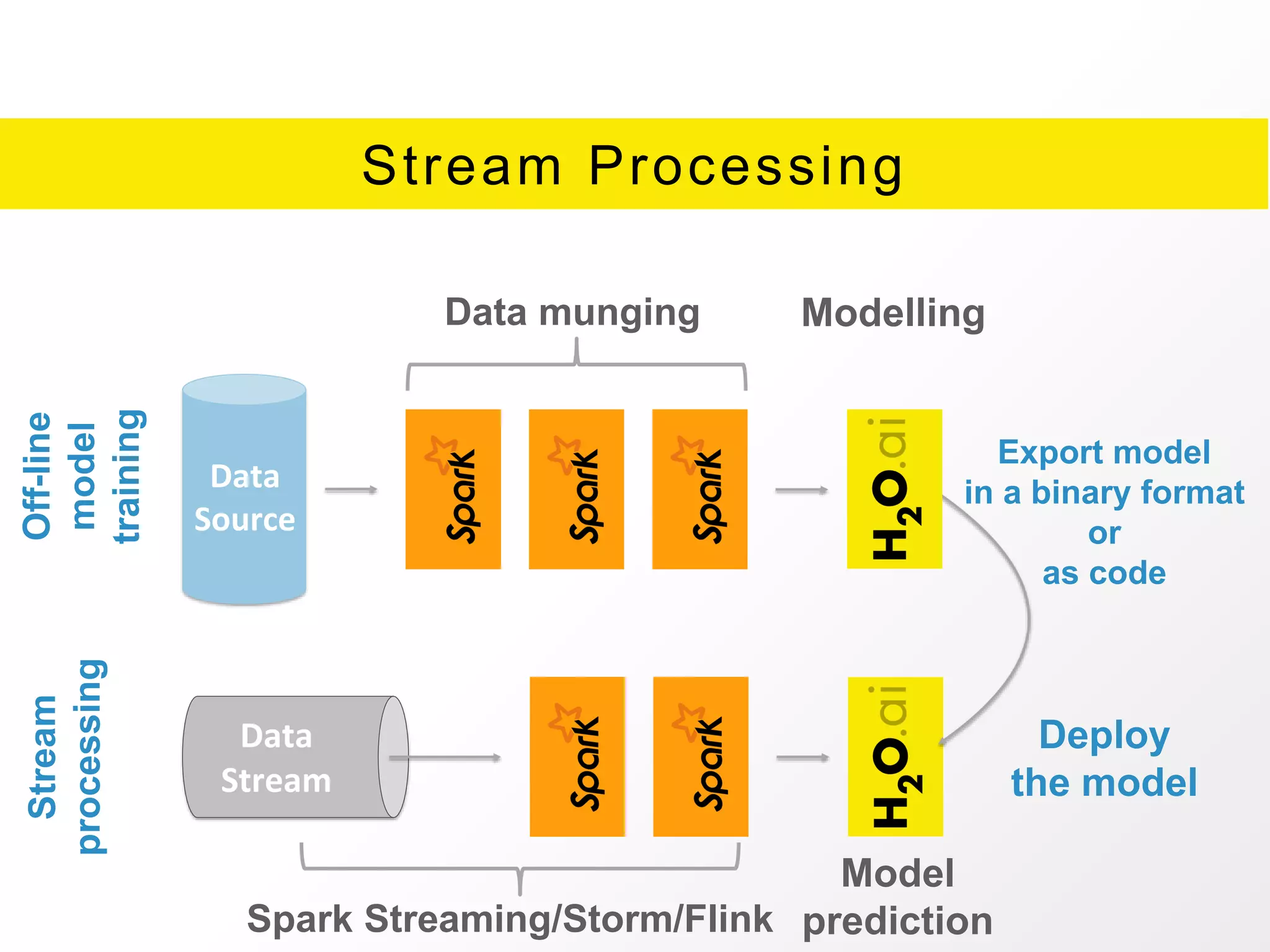












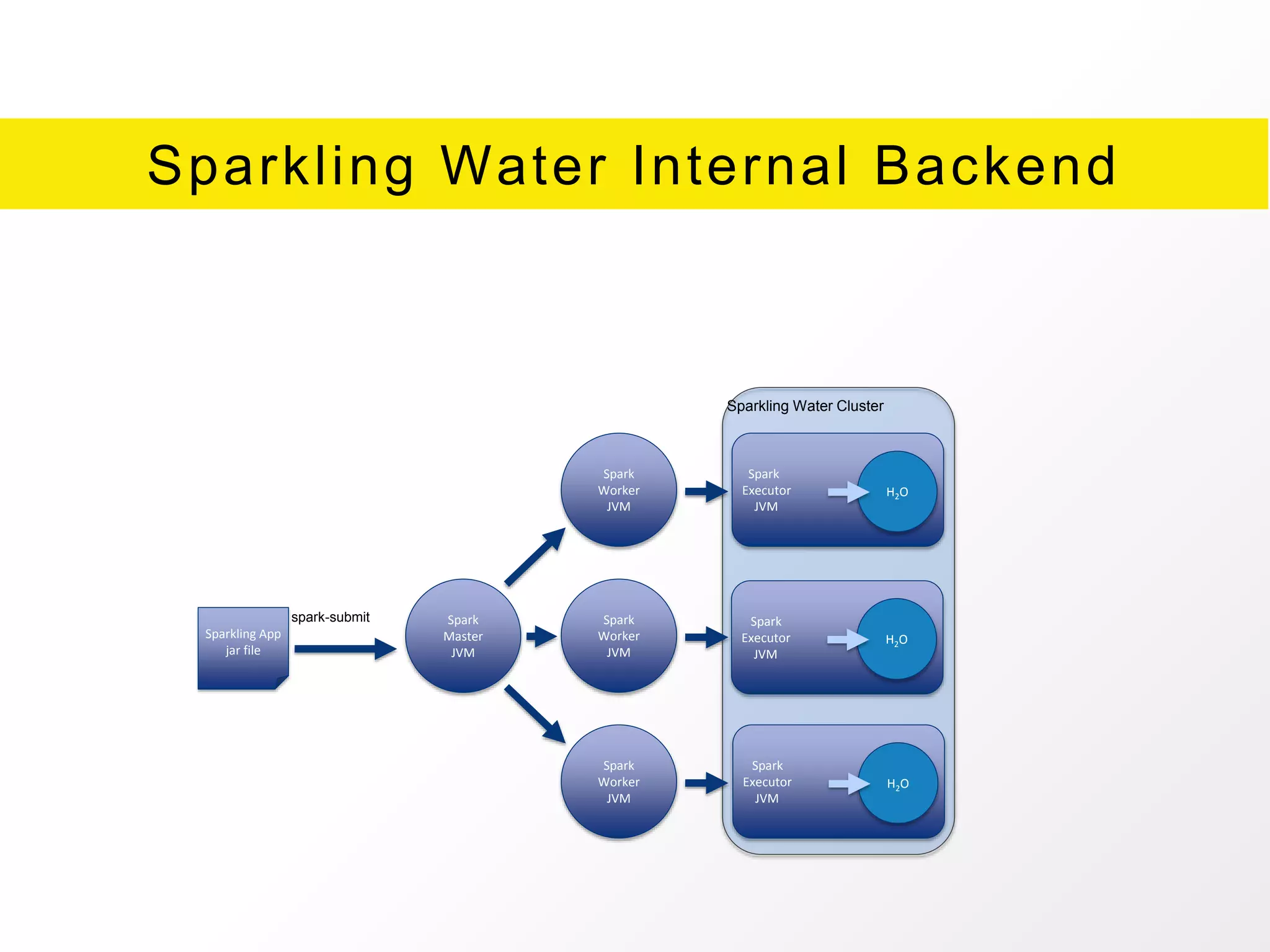
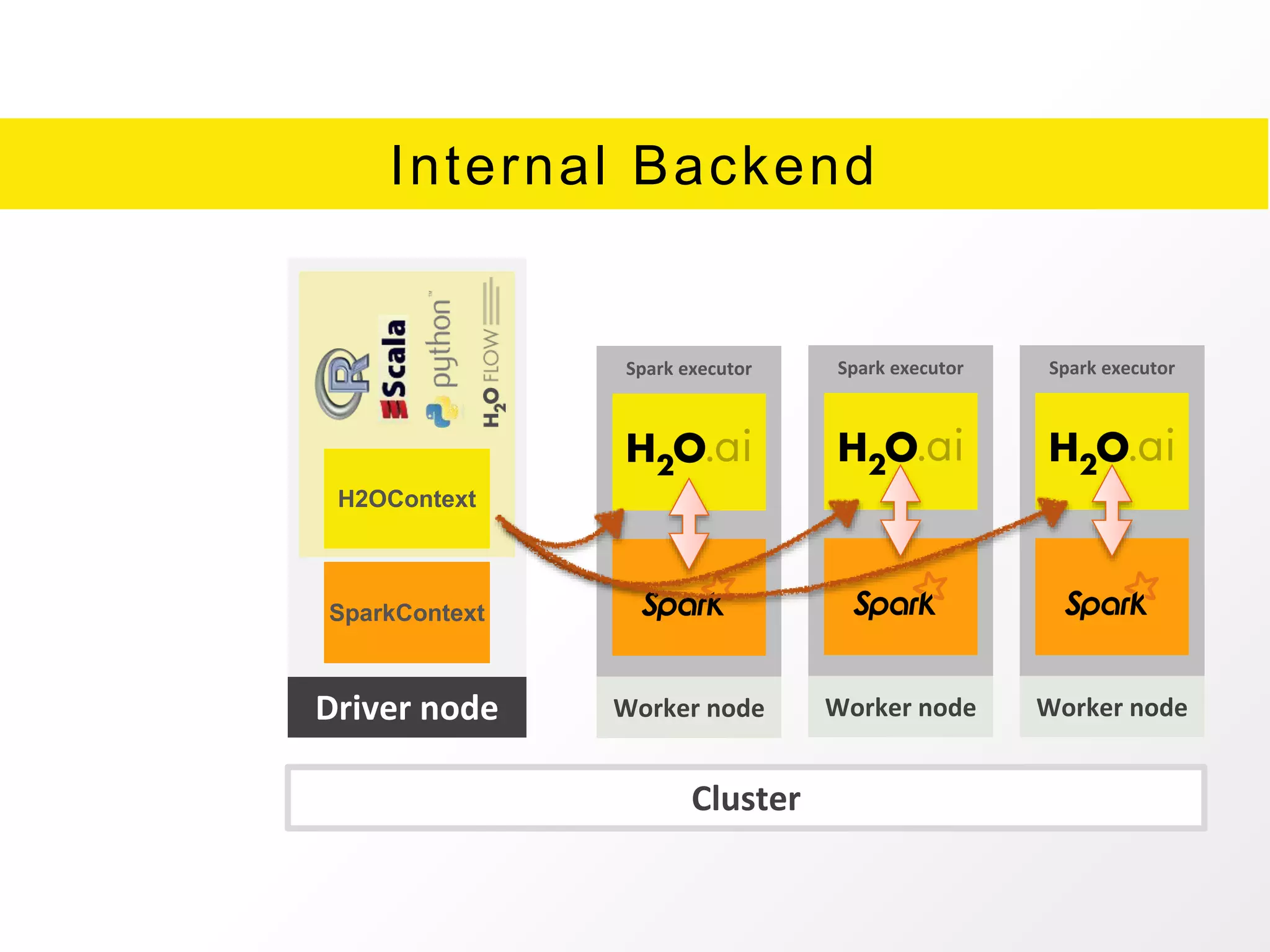
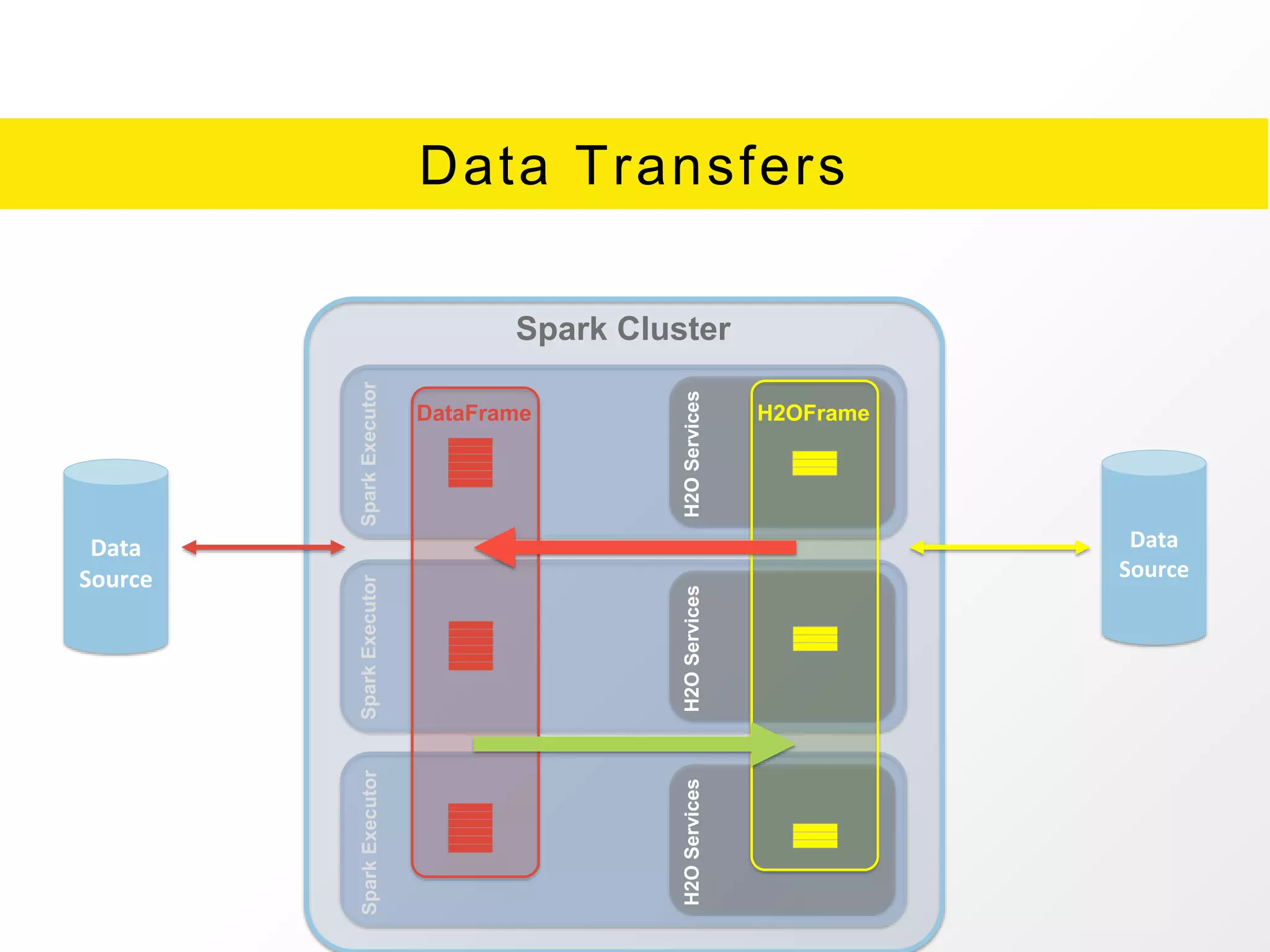




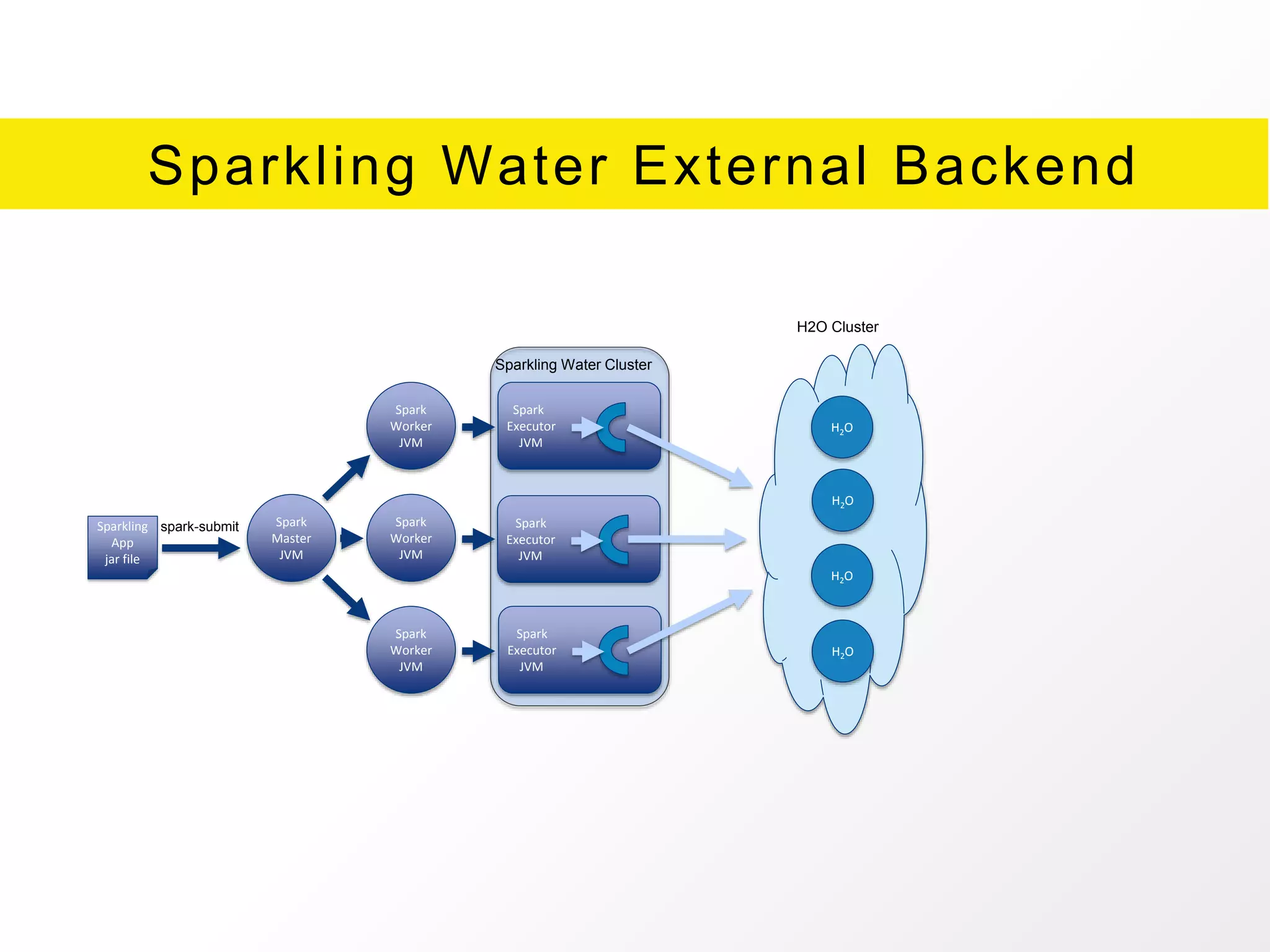
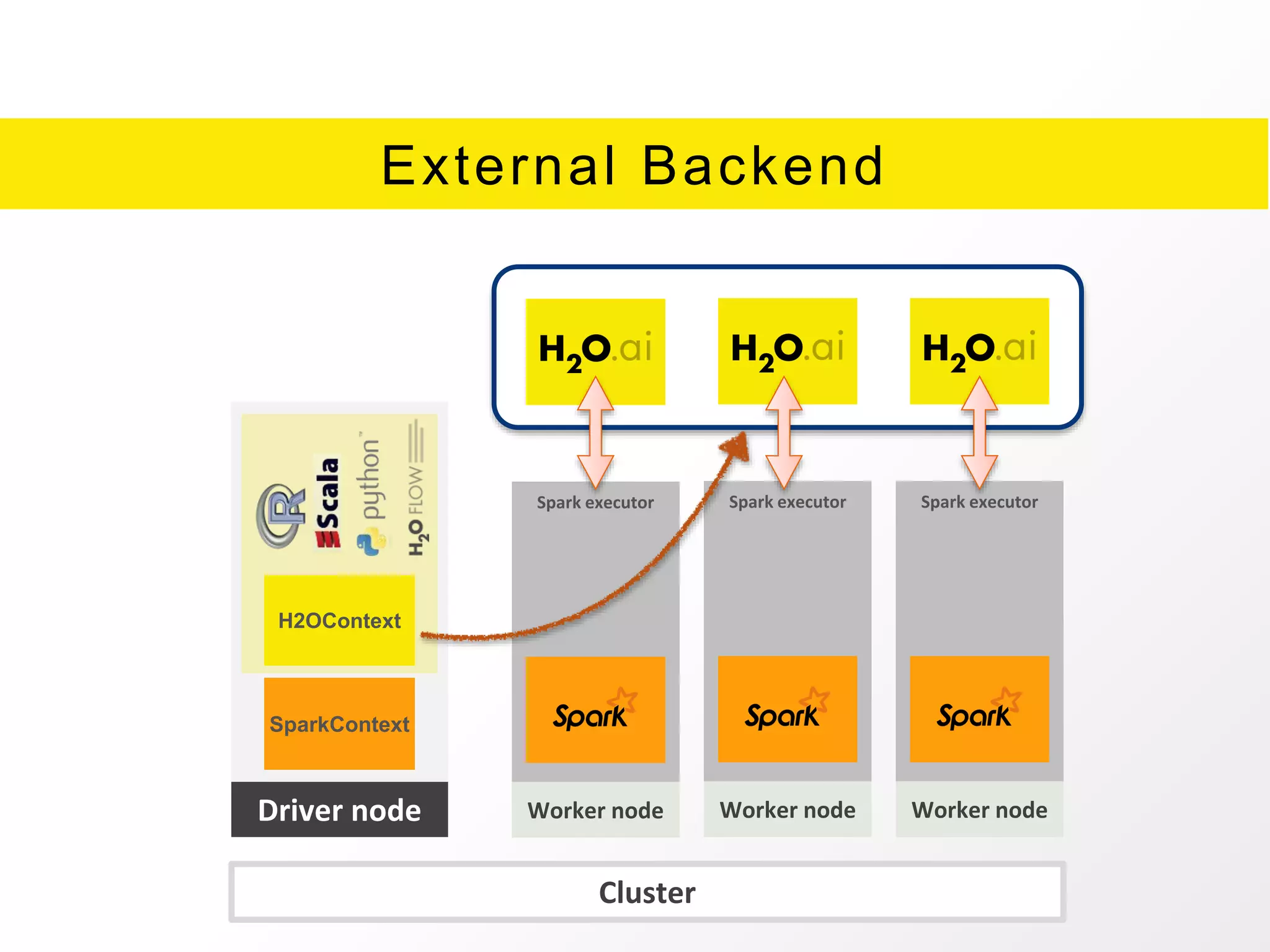
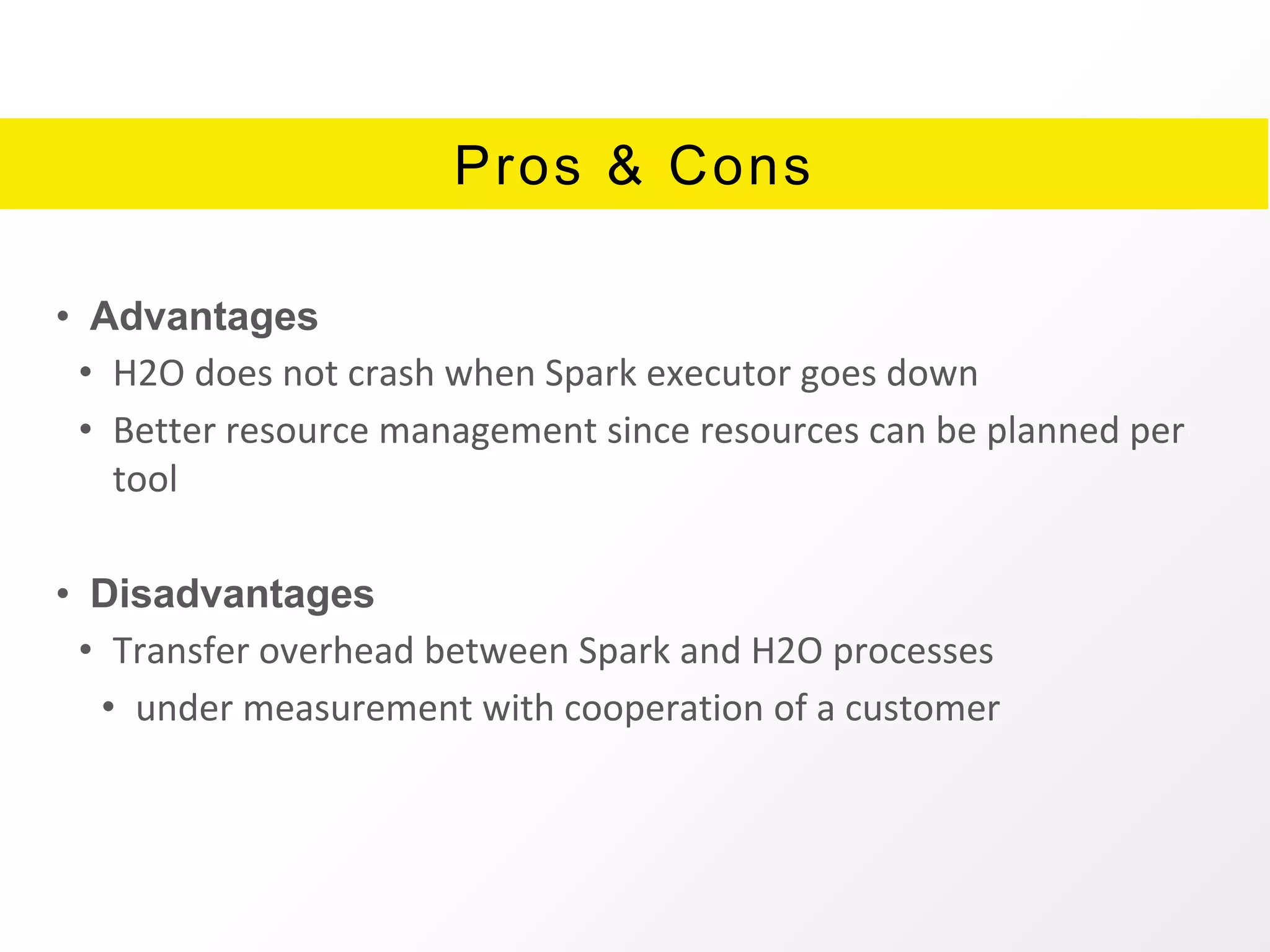






The document presents an overview of H2O.ai's Sparkling Water, which integrates H2O machine learning algorithms with Apache Spark. It highlights features such as seamless integration, advanced modeling capabilities, and support for different programming languages, along with various operational modes of the H2O cluster. Additional resources for documentation, tutorials, and community engagement are also provided.









































































![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)

