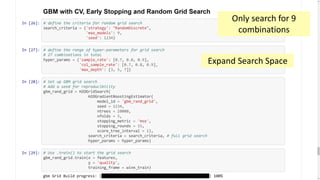
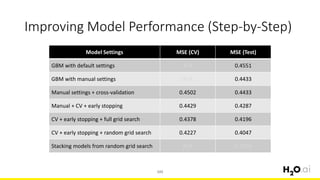
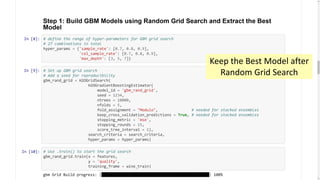
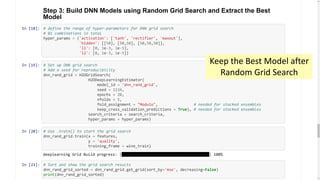
Download as PDF, PPTX












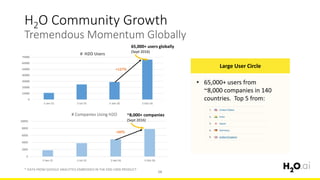






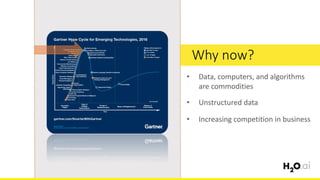
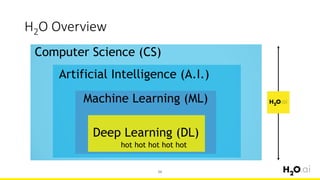
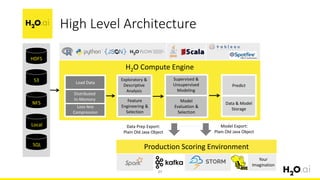
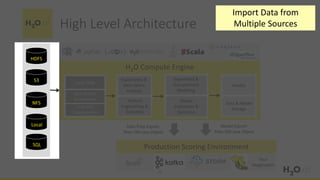
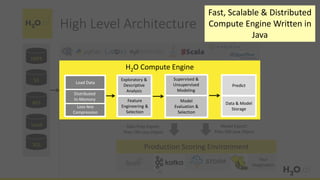
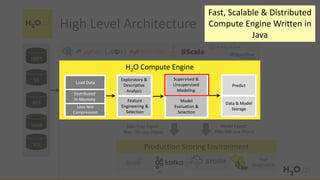


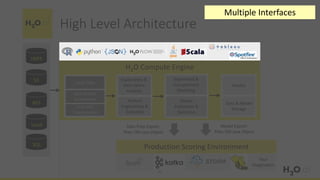
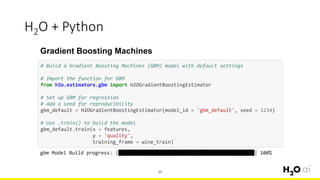

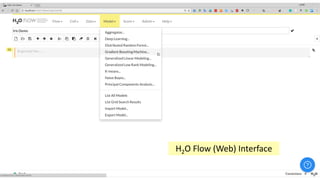
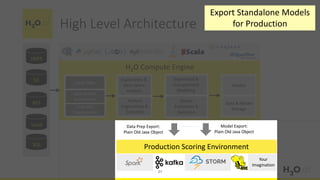




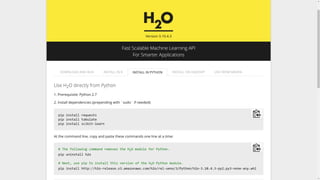

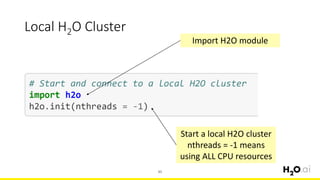
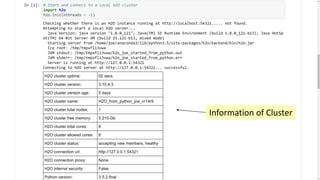

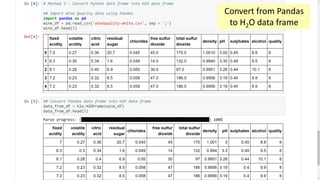









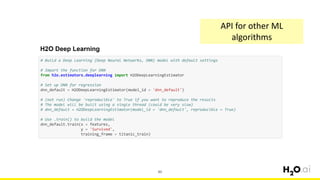






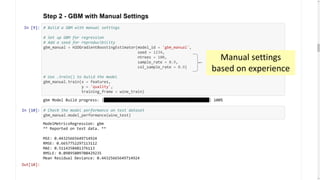

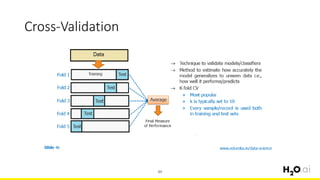

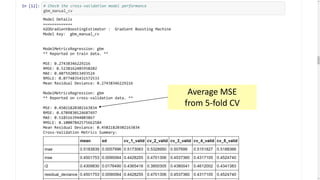













This document provides an introduction and overview of machine learning with H2O and Python. It begins with background information about the presenter, Joe Chow, including his work experience and side projects. The agenda then outlines topics to be covered, including an introduction to H2O.ai the company and machine learning platform, followed by a Python tutorial and examples. The tutorial will cover importing and manipulating data, basic and advanced regression and classification models, and using H2O in the cloud.














































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)


